- Published on
Do we need to train a model to understand how good it would be?
- Authors

- Name
- AbnAsia.org
- @steven_n_t
The concepts are simple: featurize the learning meta-data, train a model to predict performance metrics with those features, and use that meta-model to search the optimization space when tuning another model.
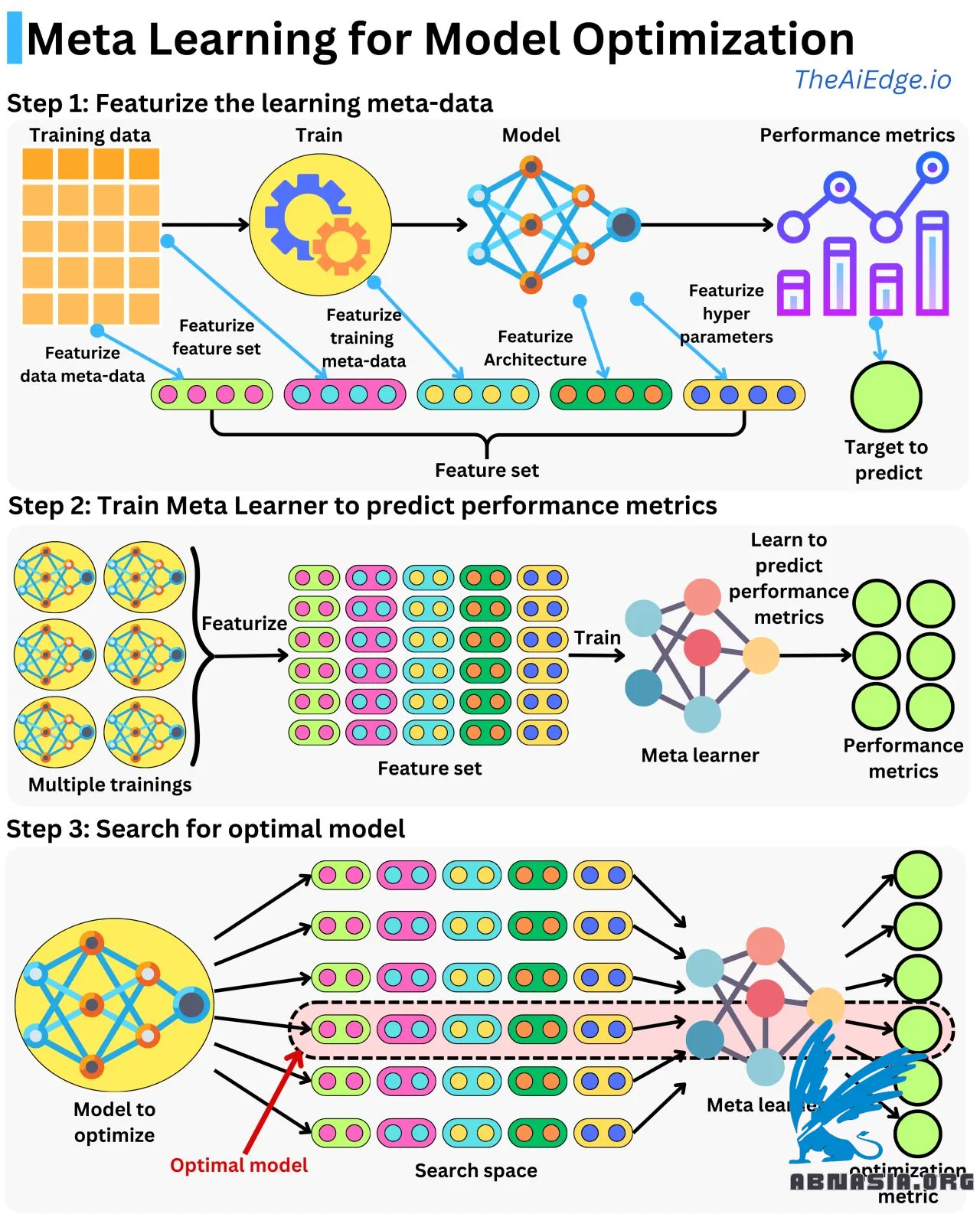
Do we need to train a model to understand how good it would be? Can't we "guess" its potential predictive power just based on its architecture or training parameters? That's the idea behind Meta-Learning: learn the patterns that make a model better than another one for some learning task!
The concepts are simple: featurize the learning meta-data, train a model to predict performance metrics with those features, and use that meta-model to search the optimization space when tuning another model.
Featurizing the learning meta-data means that we create features from the training settings. We can capture the architecture of a network as a one-hot encoded feature vector. We can capture the different hyperparameter values and the training parameters, such as the number of epochs or the hardware (CPU / GPT). We can extend the meta-feature space to the dataset used for training. For example, we can include a one-hot encoded representation of the features used and the number of samples that were used (this will allow you to perform feature selection as well). We could capture anything that could influence the learning and the resulting performance metrics. The more meta-features you include, the greater the space you will be able to optimize over, but also, the more difficult it will be to correctly learn the target variable.
Now that you can featurize training experiments, you can train a meta-learner to learn the relationship between the training parameters and a performance metric. Because you will most likely have very few samples, your meta-learner should be a simple model such as a linear regression or a shallow neural network.
Now that you have a model that understands the relationship between the learning meta-data and the performance metrics, you can search for the learning meta-data that maximizes the performance metric. Because you have a model, you can assess billions of different learning meta-data in seconds and converge to the optimal meta-features quickly. The typical approach is to use Reinforcement Learning or supervised fine-tuning. Fine-tuning means that if you have specific training data or if you want to focus on a subset of the search space, you can train a couple of new models on that data and get the resulting performance metrics. This will allow you to fine-tune the meta-learner to get a more optimal optimization search.
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA