- Published on
How Do Large Language Models Work?
- Authors

- Name
- AbnAsia.org
- @steven_n_t
The diagram below illustrates the core architecture of LLMs.
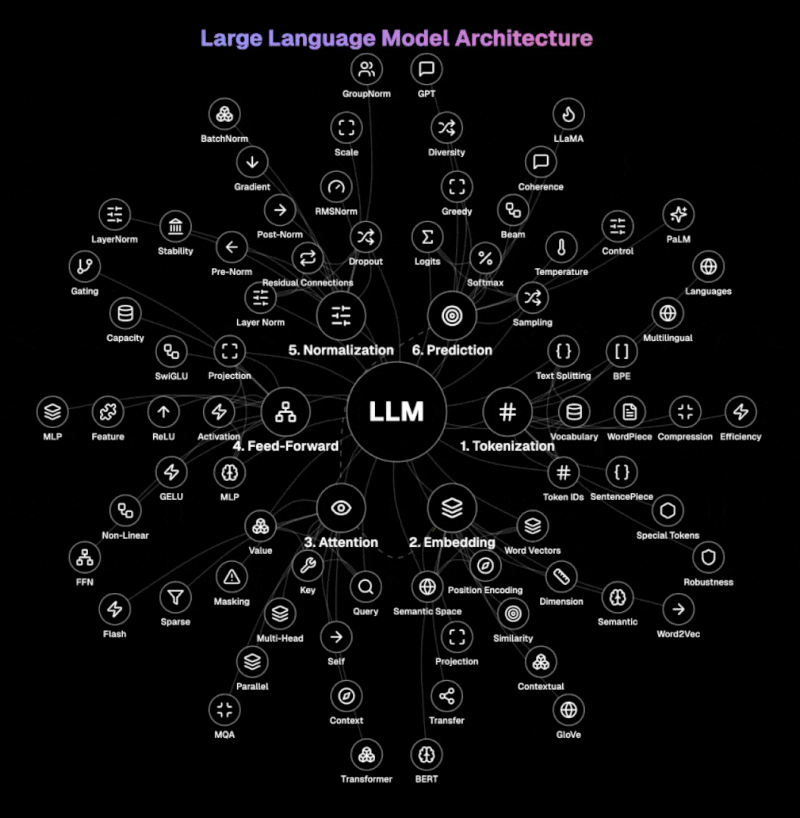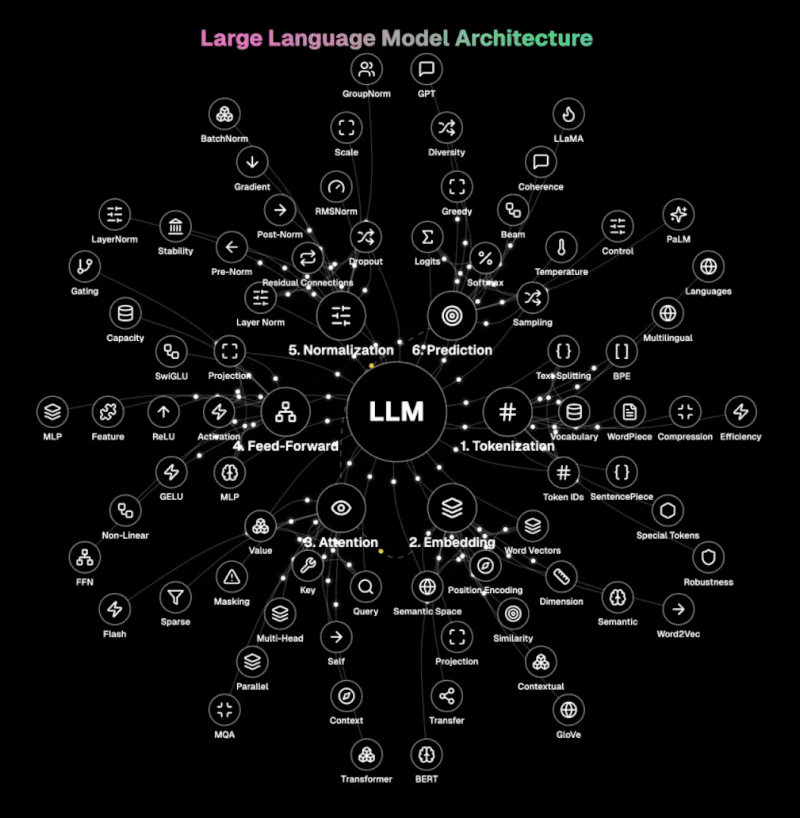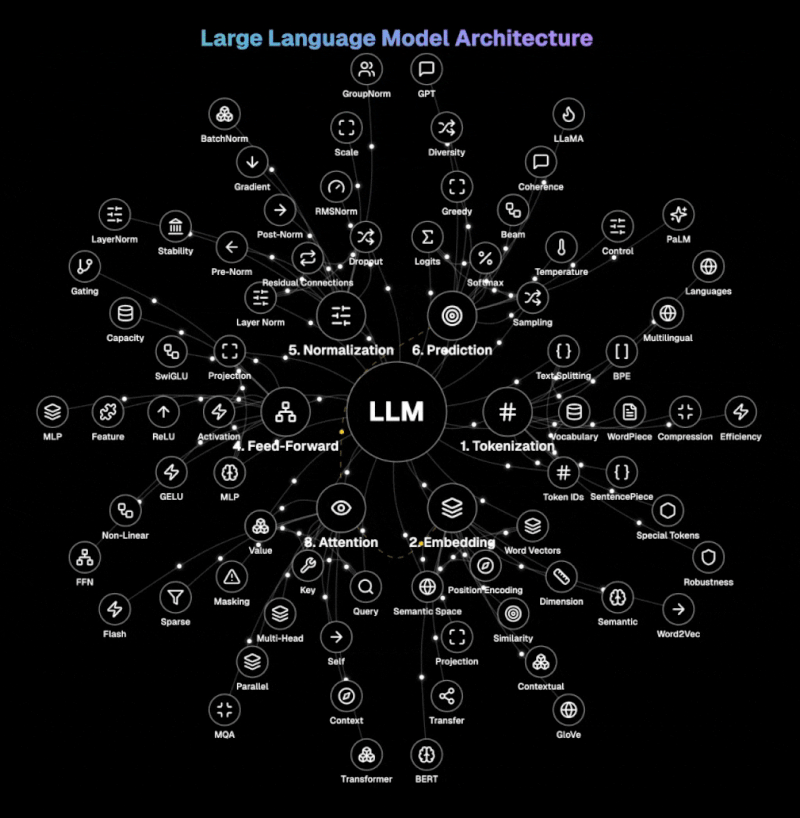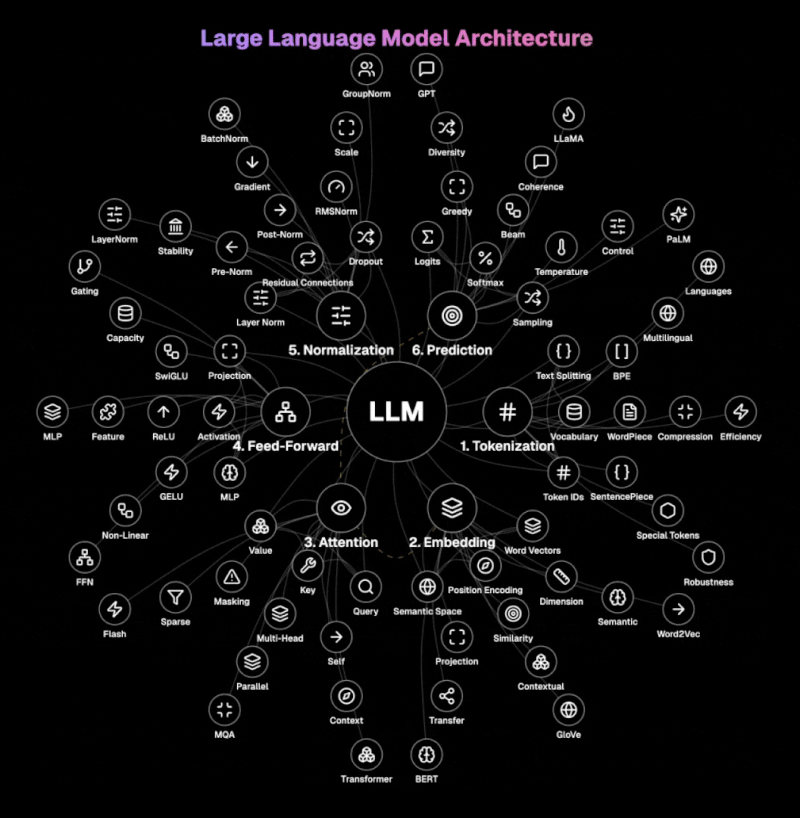
Step 1: Tokenization The LLM breaks down text into manageable units called tokens. It handles words, subwords, or characters using techniques like BPE, WordPiece, or SentencePiece. This process transforms natural language into token IDs that the model can process, with special tokens marking the beginning, end, or special functions within the text. Vocabulary size and token compression techniques are crucial for efficient processing.
Step 2: Embedding This layer transforms discrete token IDs into rich vector representations in a high-dimensional semantic space. It combines word vectors with positional encoding to preserve sequence information. The embedding matrix captures semantic relationships between words, allowing similar concepts to exist near each other in the vector space.
Step 3: Attention The heart of modern LLMs, attention determines which parts of the input to focus on when generating each output token. Using query, key, and value vectors, it computes relevance scores between all tokens in the sequence. Multi-head attention processes information in parallel across different representation subspaces, capturing various relationships simultaneously. Self-attention allows the model to consider the entire context when processing each token.
Step 4: Feed-Forward This component transforms each token's representation independently through a multi-layer perceptron (MLP). It applies non-linear activation functions like GELU or ReLU to introduce complexity that captures subtle patterns in the data. The feed-forward network increases the model's capacity to represent complex functions and relationships. It processes token representations individually, complementing the contextual processing of the attention mechanism.
Step 5: Normalisation Layer normalisation standardises inputs across features, while residual connections allow information to flow directly through the network. Pre-norm and post-norm architectures offer different stability-performance tradeoffs. Dropout prevents overfitting by randomly deactivating neurons during training, forcing the model to develop redundant representations.
Step 6: Prediction The final step transforms the processed representations into probabilities over the vocabulary. It generates logits (raw scores) for each possible next token, which are converted to probabilities using the softmax function. Temperature sampling controls randomness in generation, with lower temperatures producing more deterministic outputs. Decoding strategies like greedy, beam search, or nucleus sampling determine how the model selects tokens during generation.
What makes LLMs different from traditional language processing systems is their autoregressive nature. This creates a step-by-step generation process rather than producing entire responses at once.
In your view: Which architectural component causes hallucinations in LLMs?
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA