- Published on
Multimodal RAG, explained visually 👇
- Authors

- Name
- AbnAsia.org
- @steven_n_t
Vanilla RAG systems work well on text documents. But real-world documents contain text + images + tables, and whatnot. What to do then?
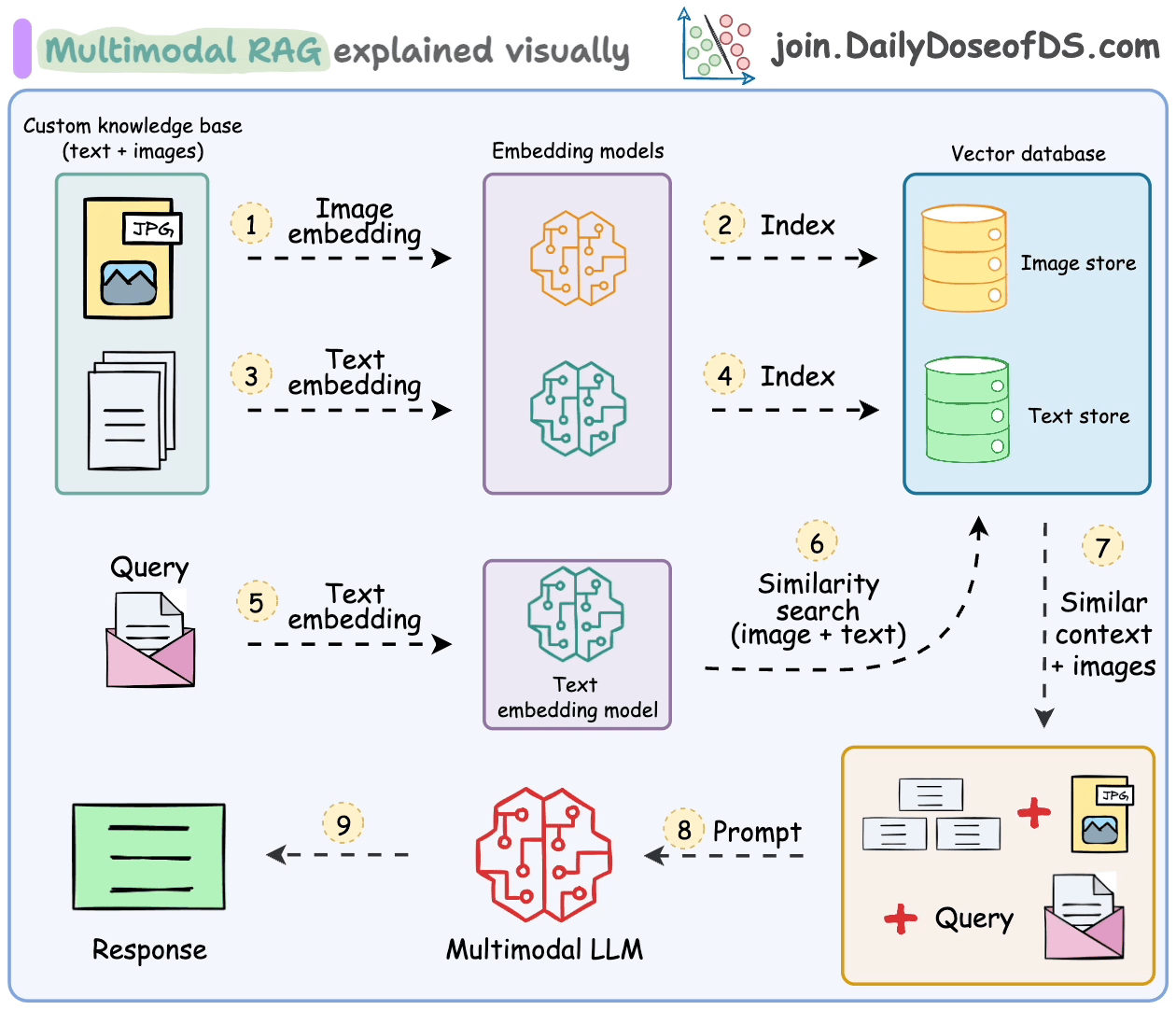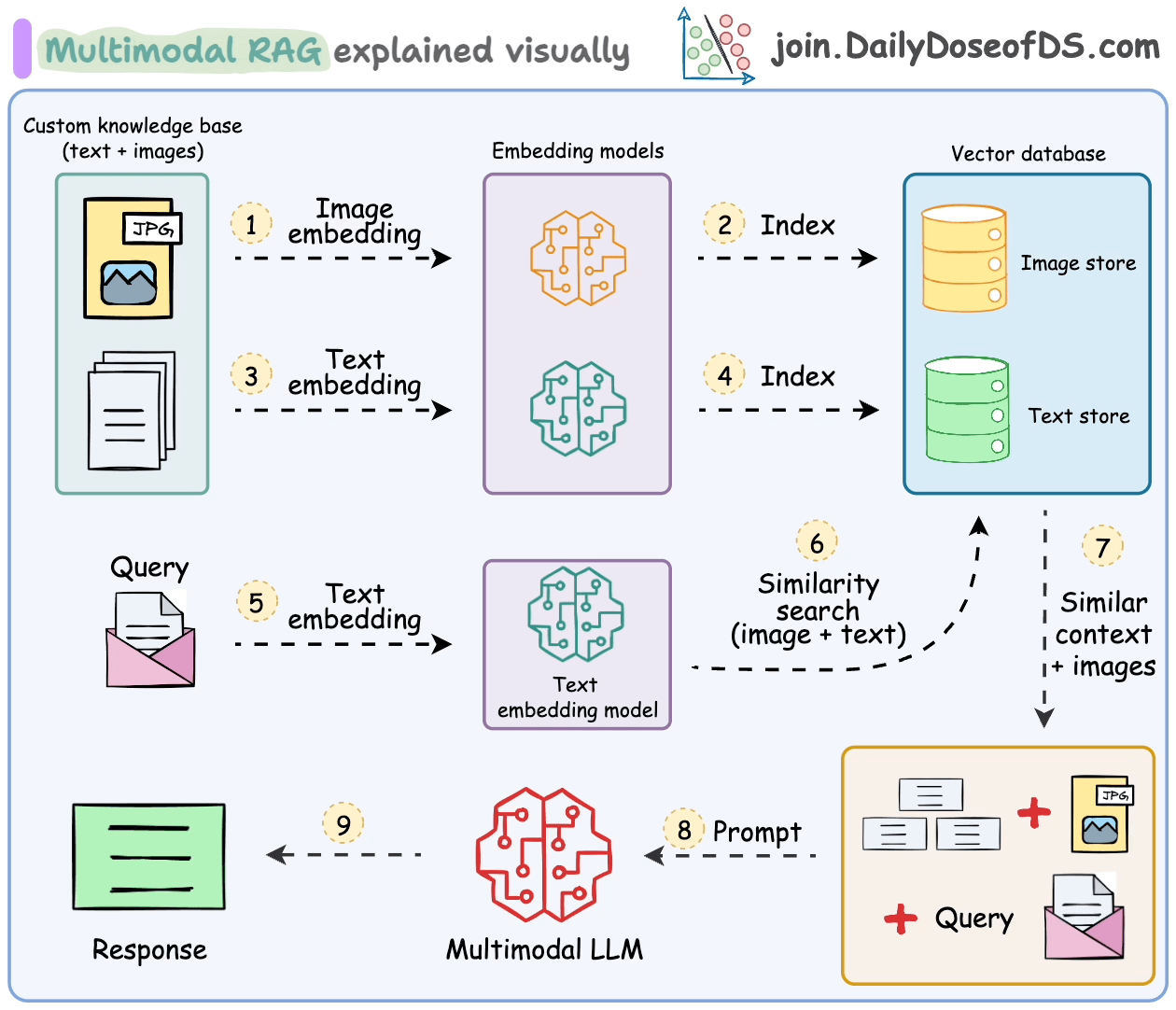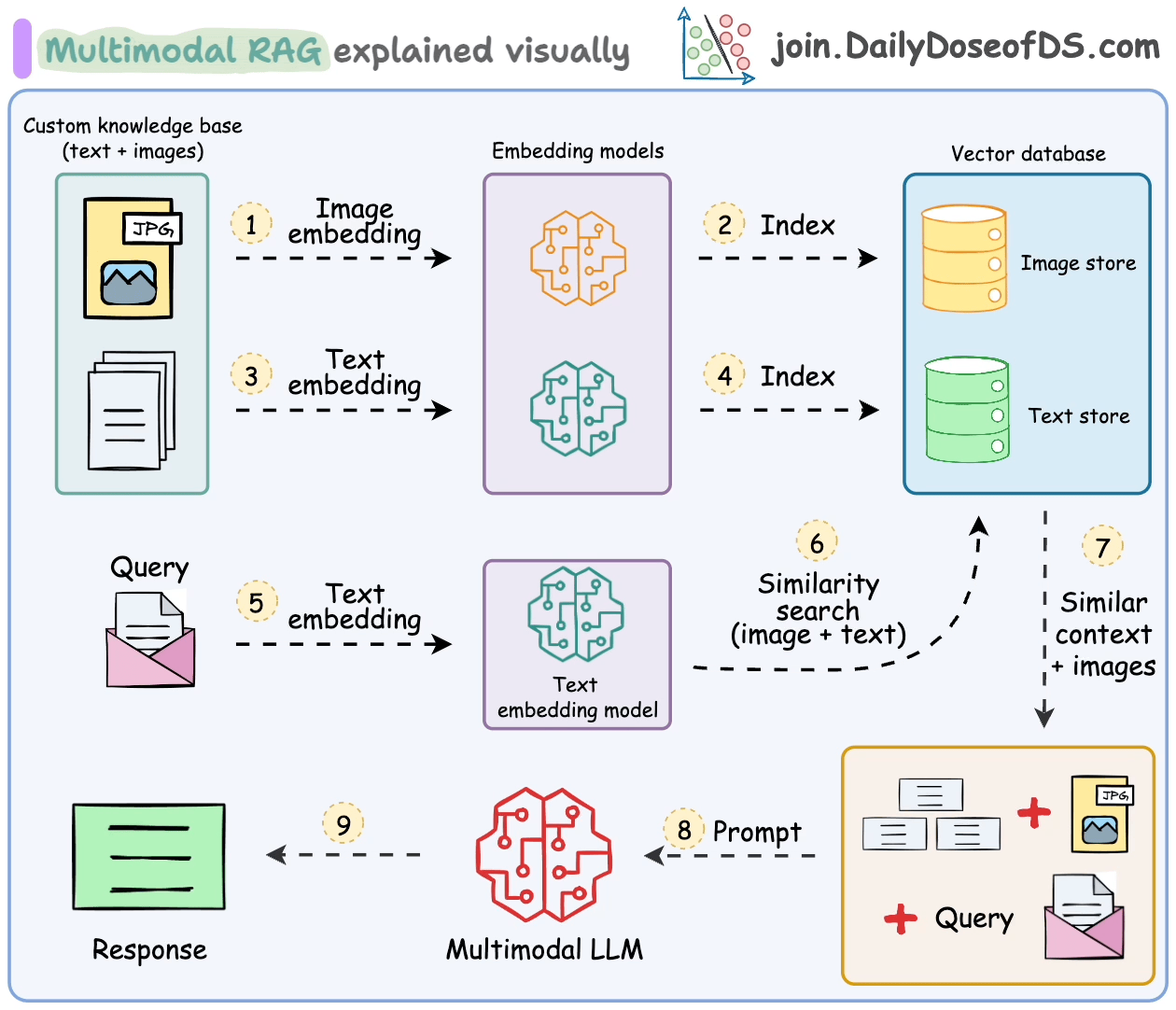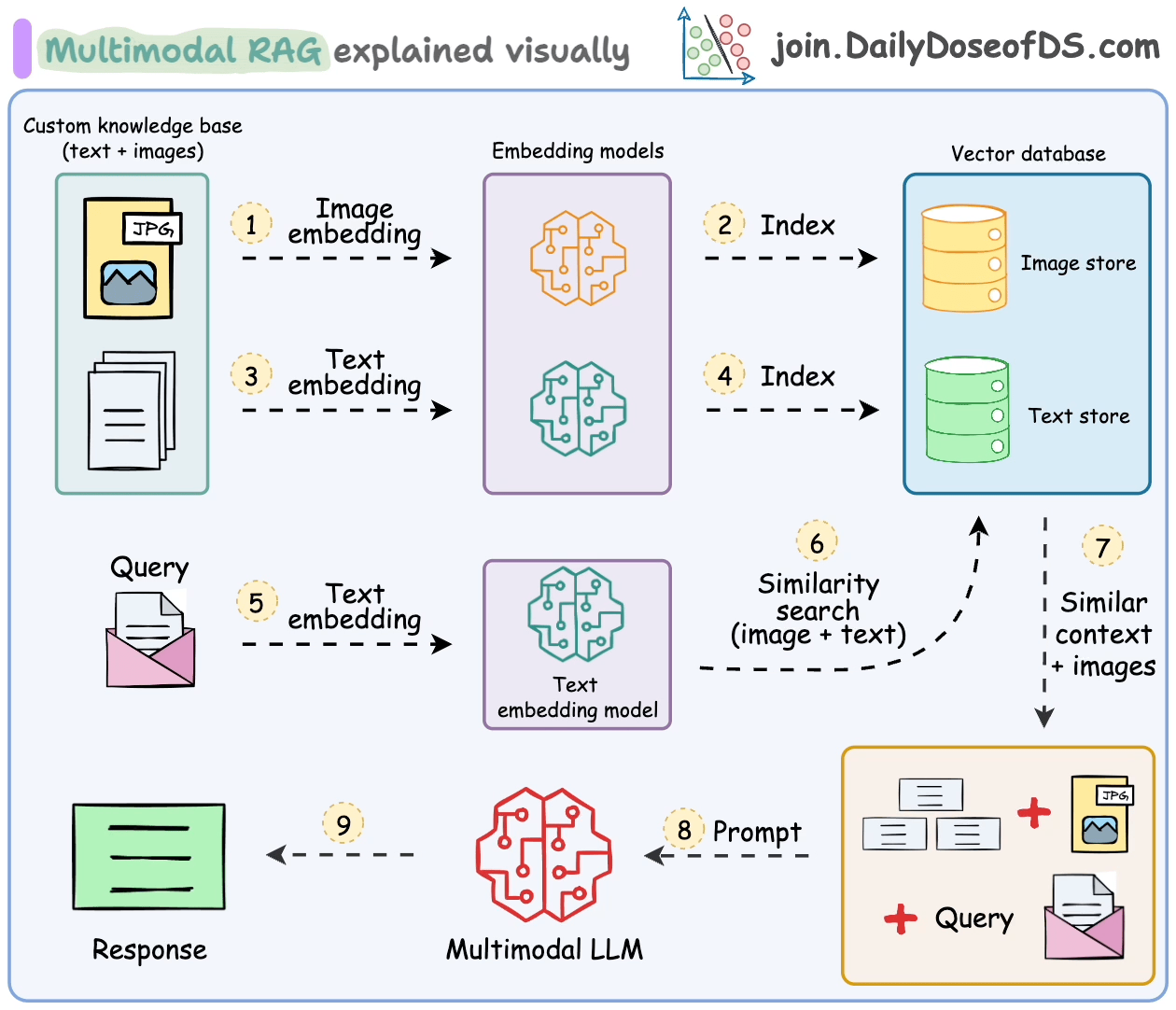
Handling such multimodal data introduces additional challenges in parsing, embedding, and retrieval.
Multimodal RAG systems are built to handle multiple types of data and do RAG over.
Let's understand some of its key components and how they work together to make this happen.
- Multimodal Large Language Model (LLM):
At the heart of Multimodal RAG is a Multimodal LLM capable of processing both text and images.
This enables the assistant to understand queries and provide responses based on both visual and textual information.
- Text Embedding Model:
We use a text embedding model to convert textual data into numerical vectors.
These embeddings capture the semantic meaning of text, allowing for efficient retrieval of relevant documents.
- Image Embedding Model:
Similarly, an image embedding model (eg. OpenAI CLIP) transforms images into numerical vectors.
This allows the system to index and retrieve images based on their content, bridging the gap between visual and textual data.
- Knowledge Base with Text and Images:
Our knowledge base is a collection of both text documents and images.
This multimodal dataset provides the foundation for the assistant to draw upon when generating responses.
- Vector Store Supporting Multimodal Embeddings:
A vector store that can handle both text and image embeddings is crucial.
Qdrant is a really great choice, I regularly use it!
- Prompt Template:
We create a prompt template that incorporates both textual and visual context.
This template guides the Multimodal LLM to generate coherent responses using the retrieved text and images.
The steps are also summarized in the visual below.
We recently started a crash course on building RAG systems and have published four parts:
In Part 1, we explored the foundational components of RAG systems, the typical RAG workflow, and the tool stack, and also learned the implementation.
In Part 2, we understood how to evaluate RAG systems (with implementation).
In Part 3, we learned techniques to optimize RAG systems and handle millions/billions of vectors (with implementation).
In Part 4, we explored multimodality and covered techniques to build RAG systems on complex docs—ones that have images, tables, and texts (with implementation).
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA