- Published on
Why GraphRAG one of the best RAG system
- Authors

- Name
- AbnAsia.org
- @steven_n_t
Graph Databases should be the better choice for Retrieval Augmented Generation (RAG)!
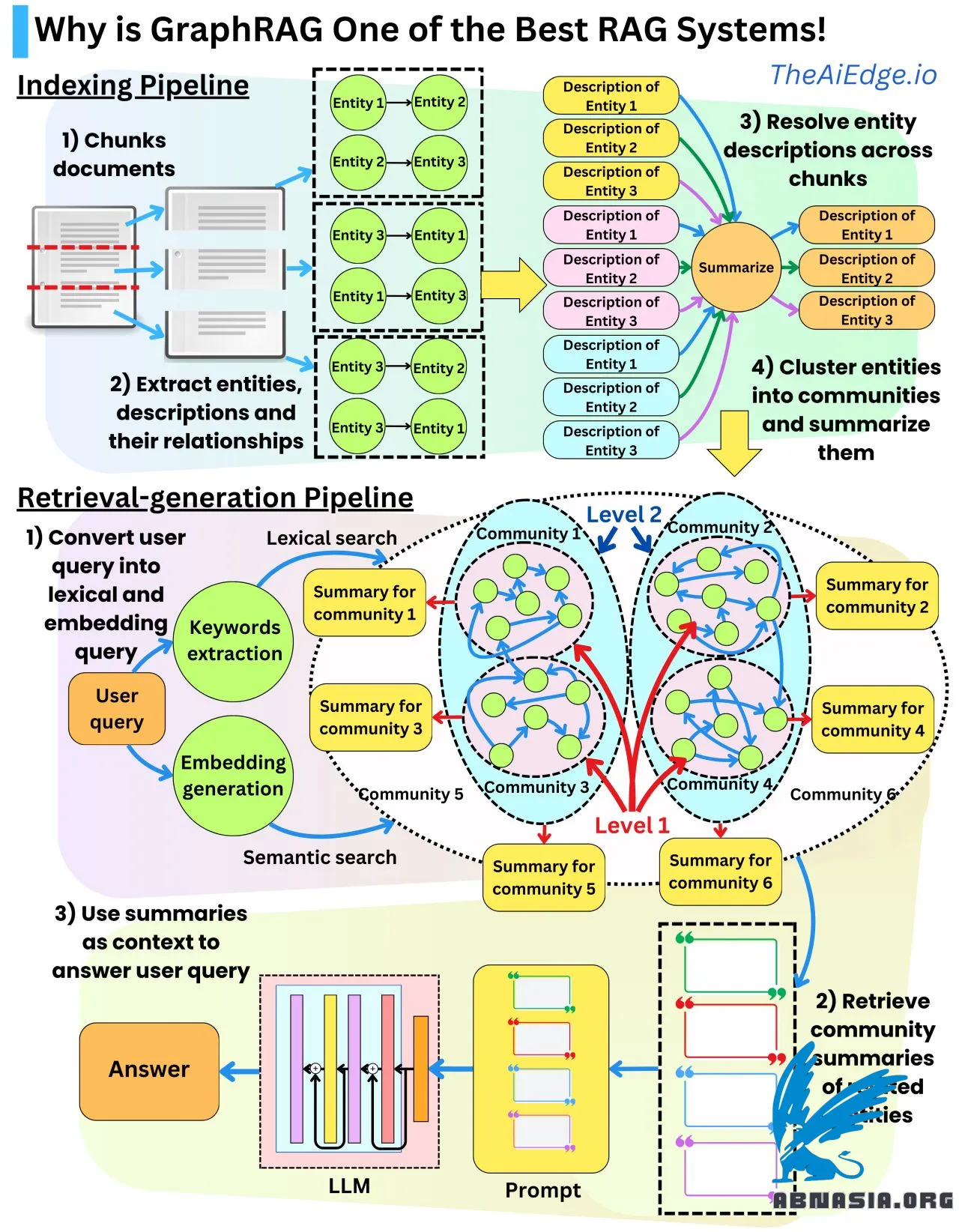
RAG systems are usually pretty bad at retrieving the right context! The retrieved information is very local to the original documents, and it might be tricky to get the documents that actually relate to the user query. That is where Microsoft GraphRAG can provide a solution!
There are 2 important pieces. First, we are going to create summaries of the different documents at different scales. This way, we are going to be able to understand, overall, what global information is contained in the full documents, as well as the local information contained in smaller chunks of text. Second, we are going to reduce the textual information to its graphical form. The assumption is that the information contained in the text can be represented as a set of nodes and edges. This allows the representation of the full information contained in the text as a knowledge base that can be stored in a graph database.
The data indexing pipeline is as follows:
- We chunk the original documents into sub-texts.
- We extract the entities, their relationships, and their descriptions in a structured format by using an LLM.
- We resolve the duplicate entities and relationships we can find across the different text chunks. We can summarize the different descriptions into more complete ones.
- We build the graph representation of the entities and their relationships
- From the graph, we cluster the different entities into communities in a hierarchical manner by using the Leiden algorithm. Each entity belongs to multiple clusters depending on the scale of the clusters.
- For each community, we summarize it by using the entity and relationship descriptions. We have multiple summaries for each entity representing the different scales of the communities.
At retrieval time, we can convert the user query by extracting keywords for a lexical search and a vector representation for a semantic search. From the search, we get entities, and from the entities, we get their related community summaries. Those summaries are used as context in the prompt at generation time to answer the user query.
We only understand things once we implement them.
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA