- 发布于
传统RAG与HyDE的视觉解释。
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
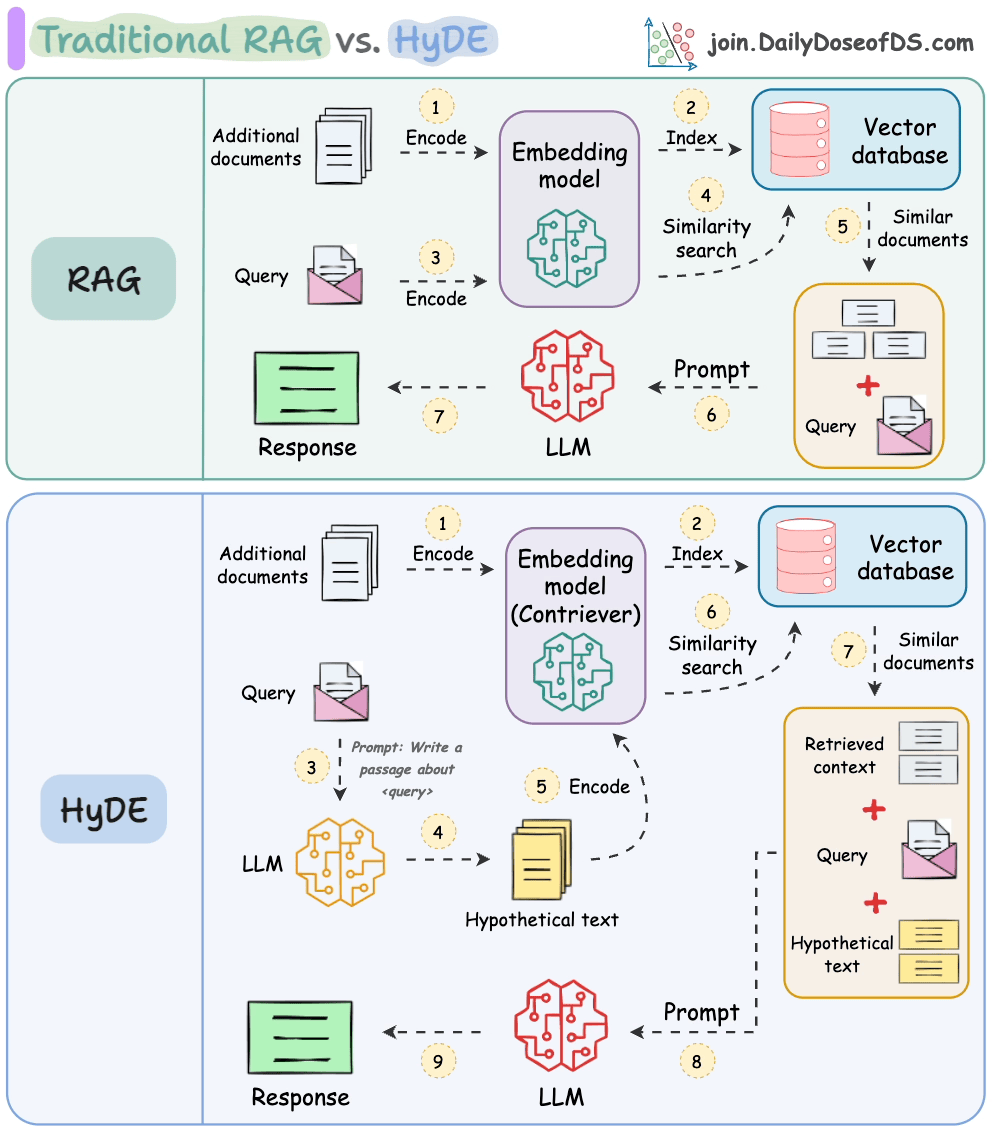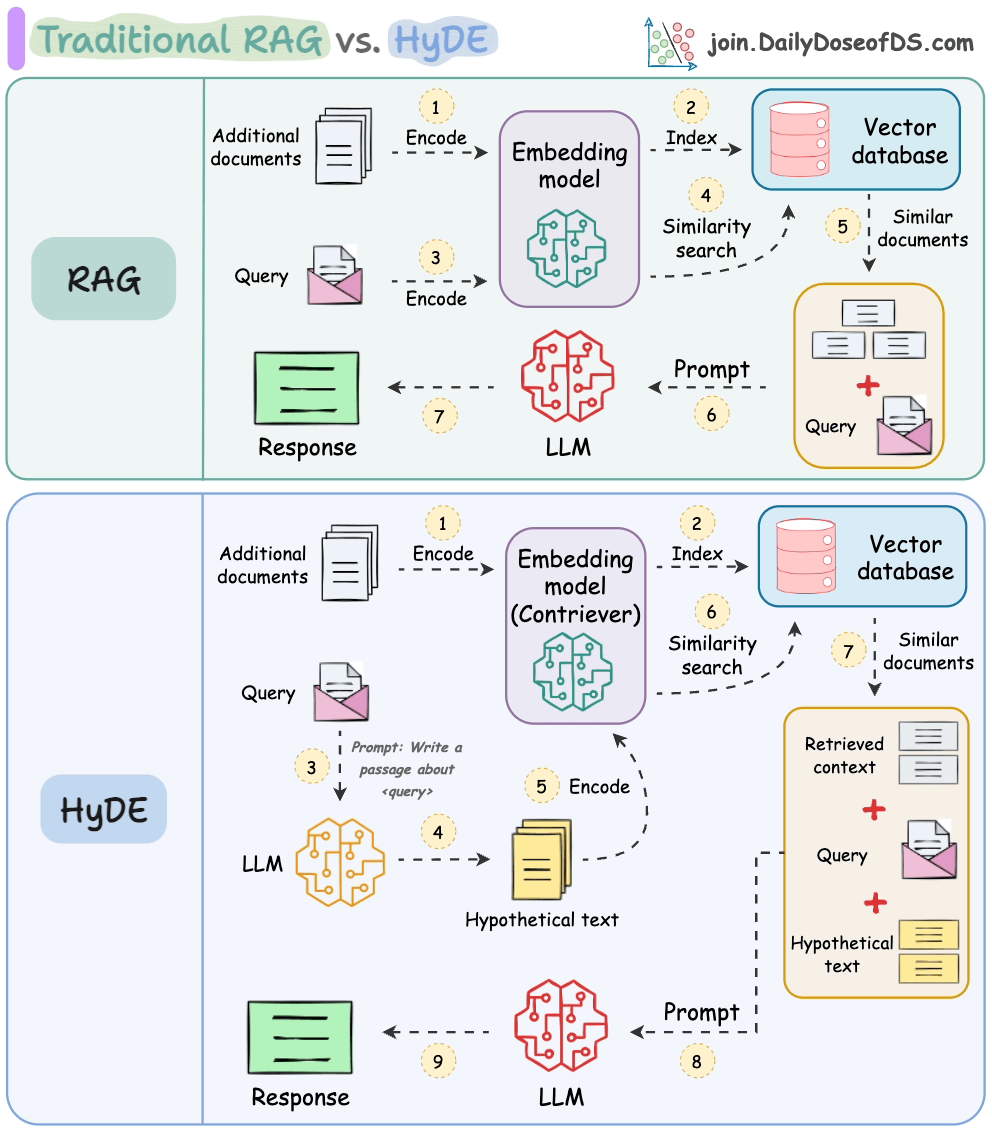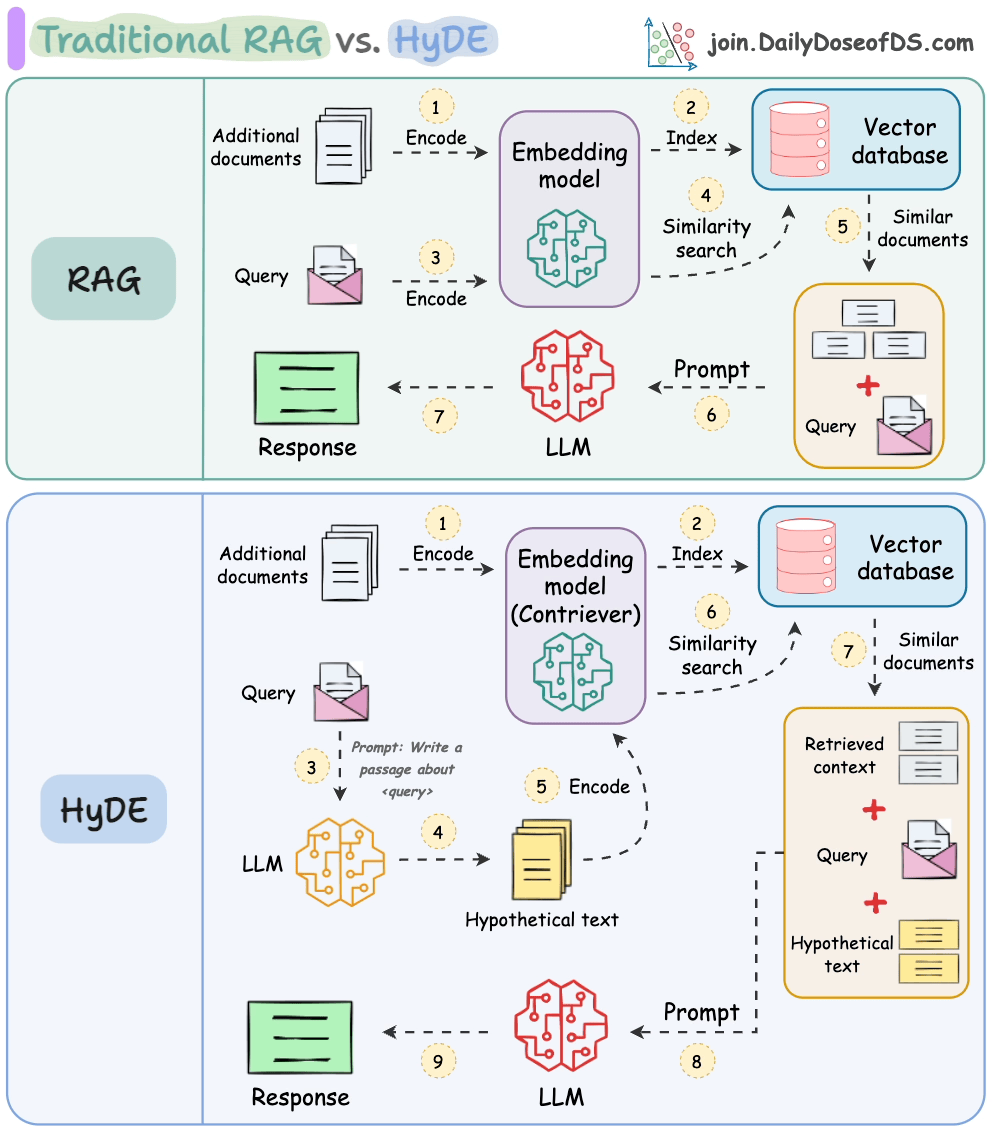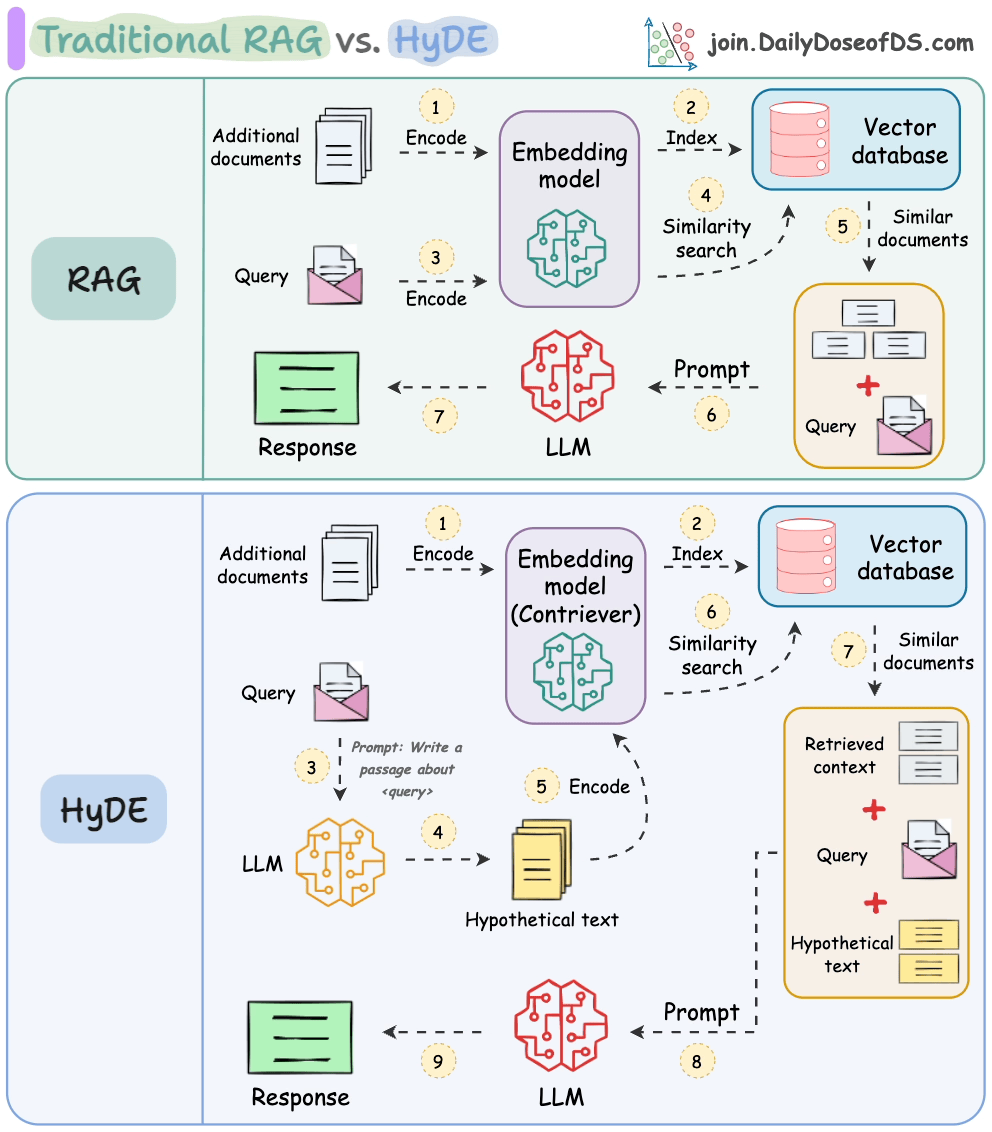
传统的RAG系统存在一个关键问题,即问题与答案在语义上并不相似。
如果你想找到一个与"What is ML?"类似的句子。
很可能"What is AI?"比"Machine learning is fun"更相似。
由于这种语义差异,在检索步骤中会检索到许多不相关的上下文。
HyDE 解决了这个问题。
以下视觉化展示了它与传统 RAG 的区别。
它的工作原理如下:
使用大语言模型(LLM)生成一个假设答案 H 来回答查询 Q(这个答案不需要完全正确)。
使用对比模型(contriever)对答案进行嵌入以获取嵌入 E(使用对比学习训练的双编码器在这里非常有名)。
使用嵌入 E 查询向量数据库并检索相关上下文(C)。
将假设答案 H + 检索到的上下文 C + 查询 Q 传递给 LLM 以生成答案。
完成!
当然,生成的假设答案可能包含虚假的细节。
但这并不会严重影响性能,因为对比模型可以嵌入——它使用对比学习训练,并且还可以作为一个近乎无损的压缩器,其任务是过滤掉假文档的虚假细节。
这生成了一个向量嵌入,预计它与实际文档的嵌入比问题与实际文档更相似。
多项研究表明,HyDE 比传统嵌入模型提高了检索性能。
但这会增加延迟和更多的 LLM 使用。
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA