- 发布于
多GPU训练的4种策略可视化解释。
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
默认情况下,深度学习模型仅使用单个GPU进行训练,即使有多个GPU可用。这里有一个解决方法。
在大数据环境中,理想的方法是将训练负载分布在多个GPU上。
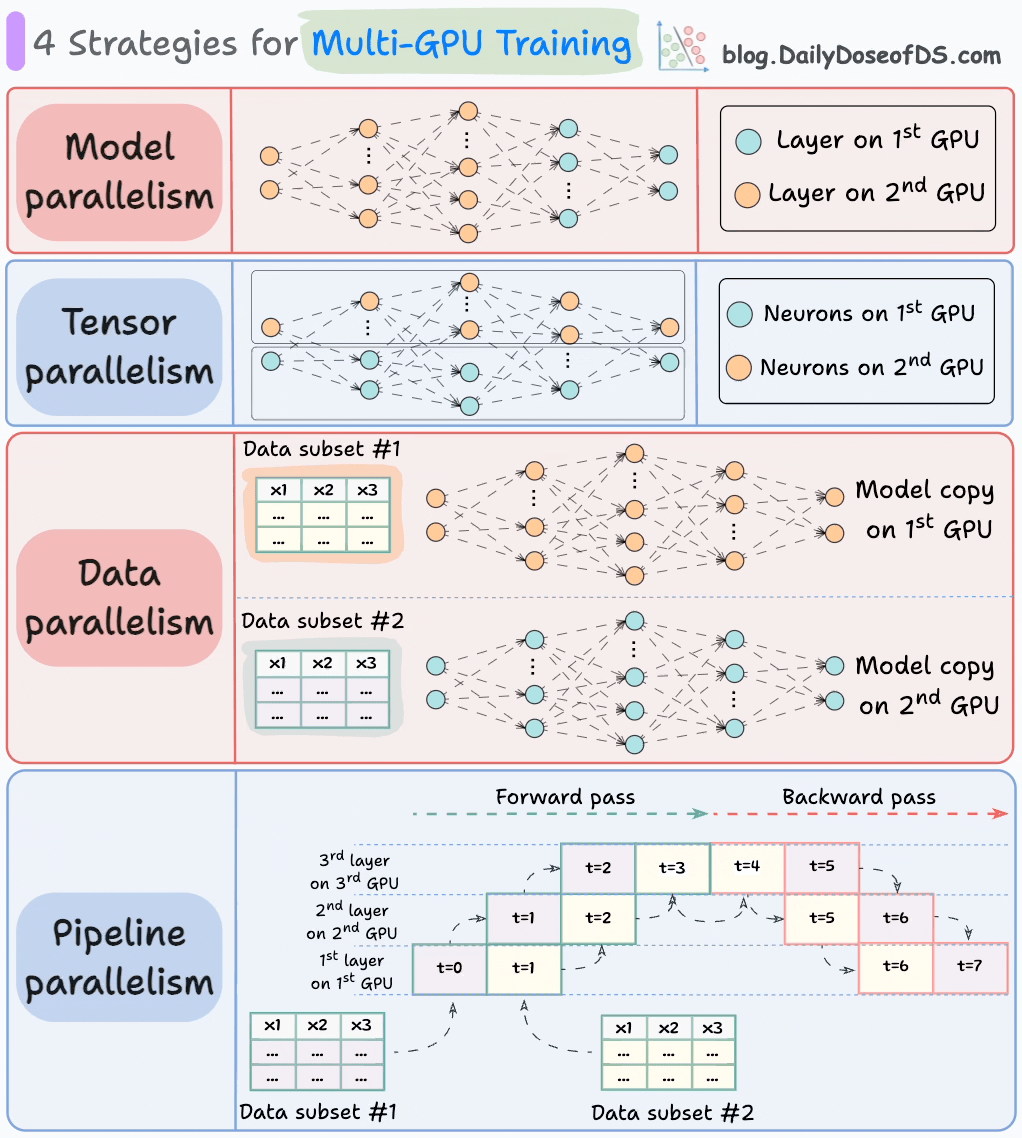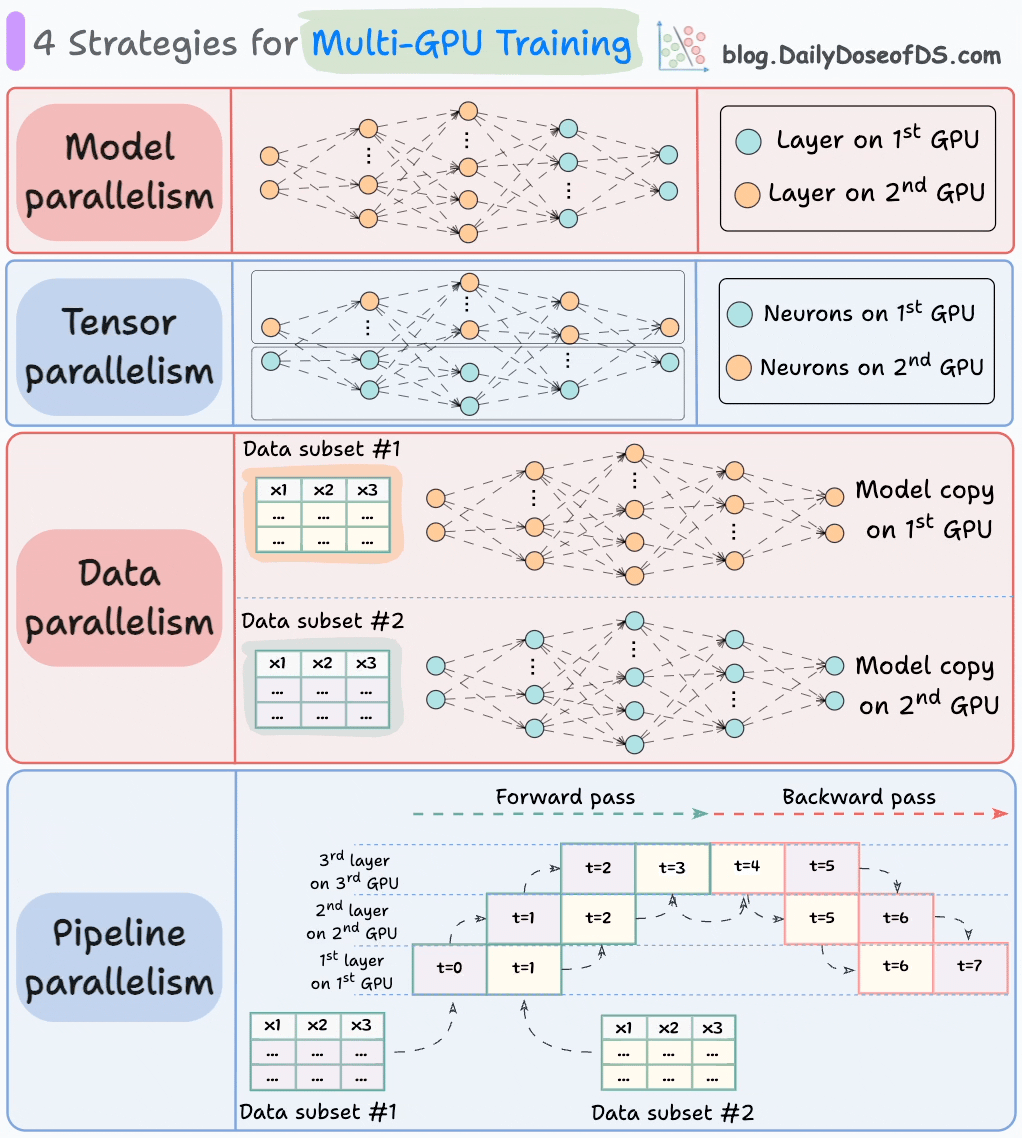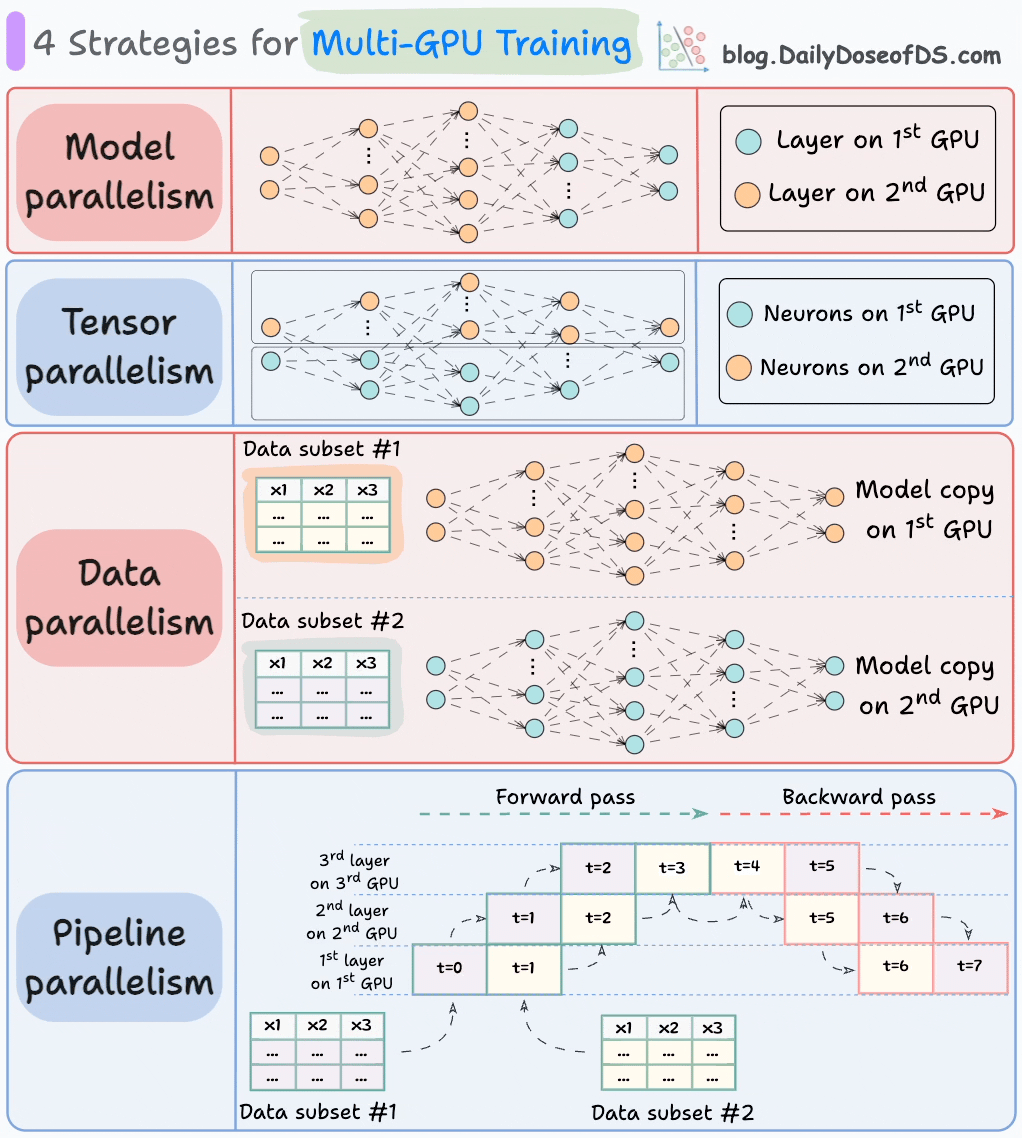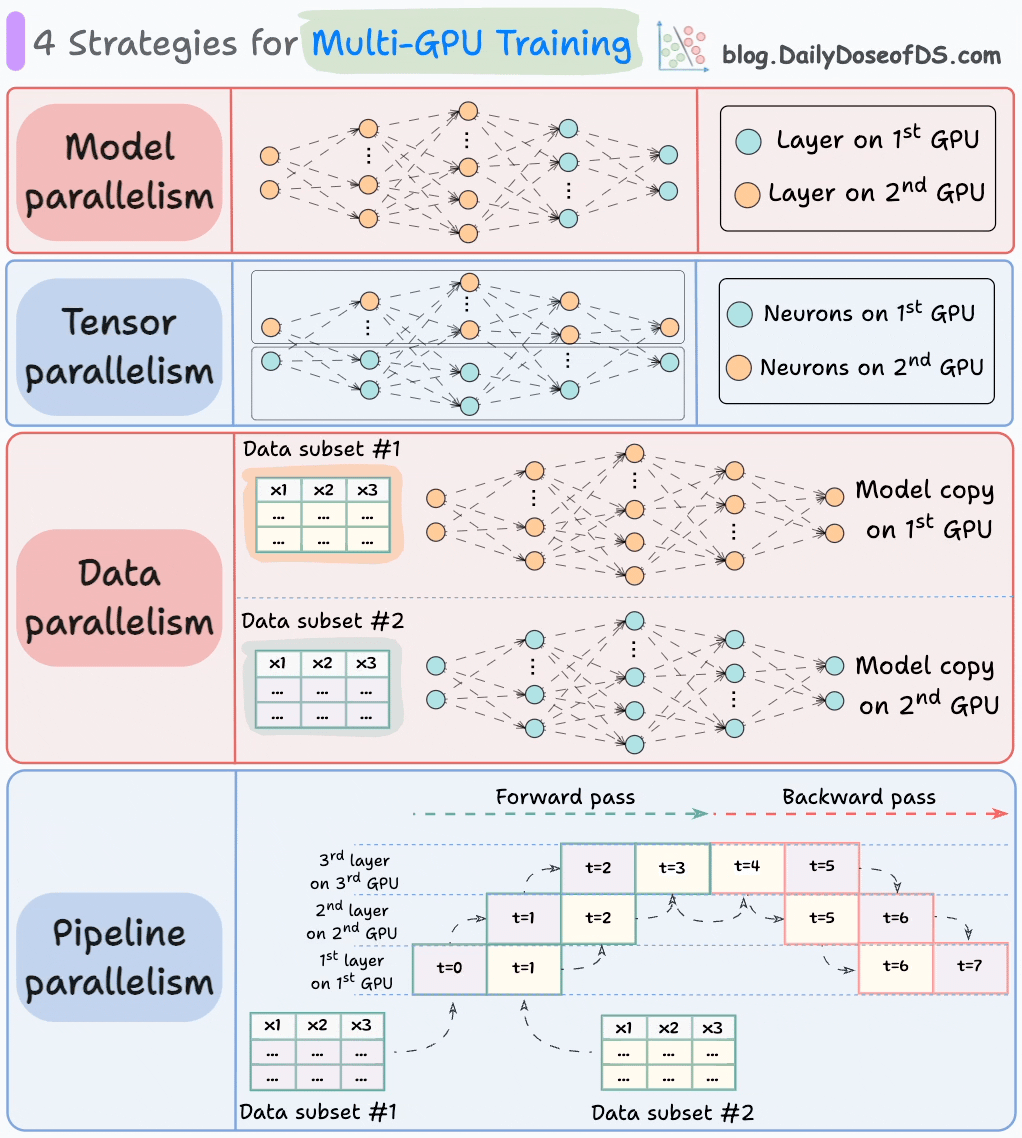
下图展示了四种常见的多GPU训练策略:
1)模型并行
- 将模型的不同部分(或层)放置在不同的GPU上。
- 适用于太大的模型无法放入单个GPU。
- 但是,模型并行也会引入严重的瓶颈,因为它需要在GPU之间传输数据时,需要数据流。
2)张量并行
- 将单个张量操作分布在多个设备或处理器上。
- 基于这样的想法:一个大型张量操作,如矩阵乘法,可以分解为较小的张量操作,每个较小的操作可以在单独的设备或处理器上执行。
- 这样的并行策略在标准的PyTorch和其他深度学习框架的实现中是内在的,但是在分布式环境中,它们变得更加显著。
3)数据并行
- 在所有GPU上复制模型。
- 将可用的数据分成较小的批次,每个批次由单独的GPU处理。
- 然后将每个GPU的更新(或梯度)聚合并用于更新每个GPU上的模型参数。
4)管道并行
这通常被认为是数据并行和模型并行的组合。
标准模型并行的缺点是,当数据被传播到第二个GPU的层时,第一个GPU会保持空闲:
管道并行通过在第一个GPU完成第一个微批次的计算并将激活传输到第二个GPU的层后,加载下一个微批次的数据来解决这个问题。
过程如下:
↳ 第一个微批次通过第一个GPU的层。
↳ 第二个GPU从第一个GPU接收第一个微批次的激活。
↳ 当第二个GPU将数据传递到层时,另一个微批次被加载到第一个GPU上。
↳ 过程继续。
- 这种方式可以大大提高GPU的利用率。这从下面的动画中可以看出,其中多个GPU在相同的时间戳上被利用(查看t=1,t=2,t=5和t=6)。
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA