- 发布于
多模态RAG,视觉解释 👇
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
香草RAG系统在文本文档上表现良好。但是现实世界中的文档包含文本+图像+表格等等。那该怎么办呢?
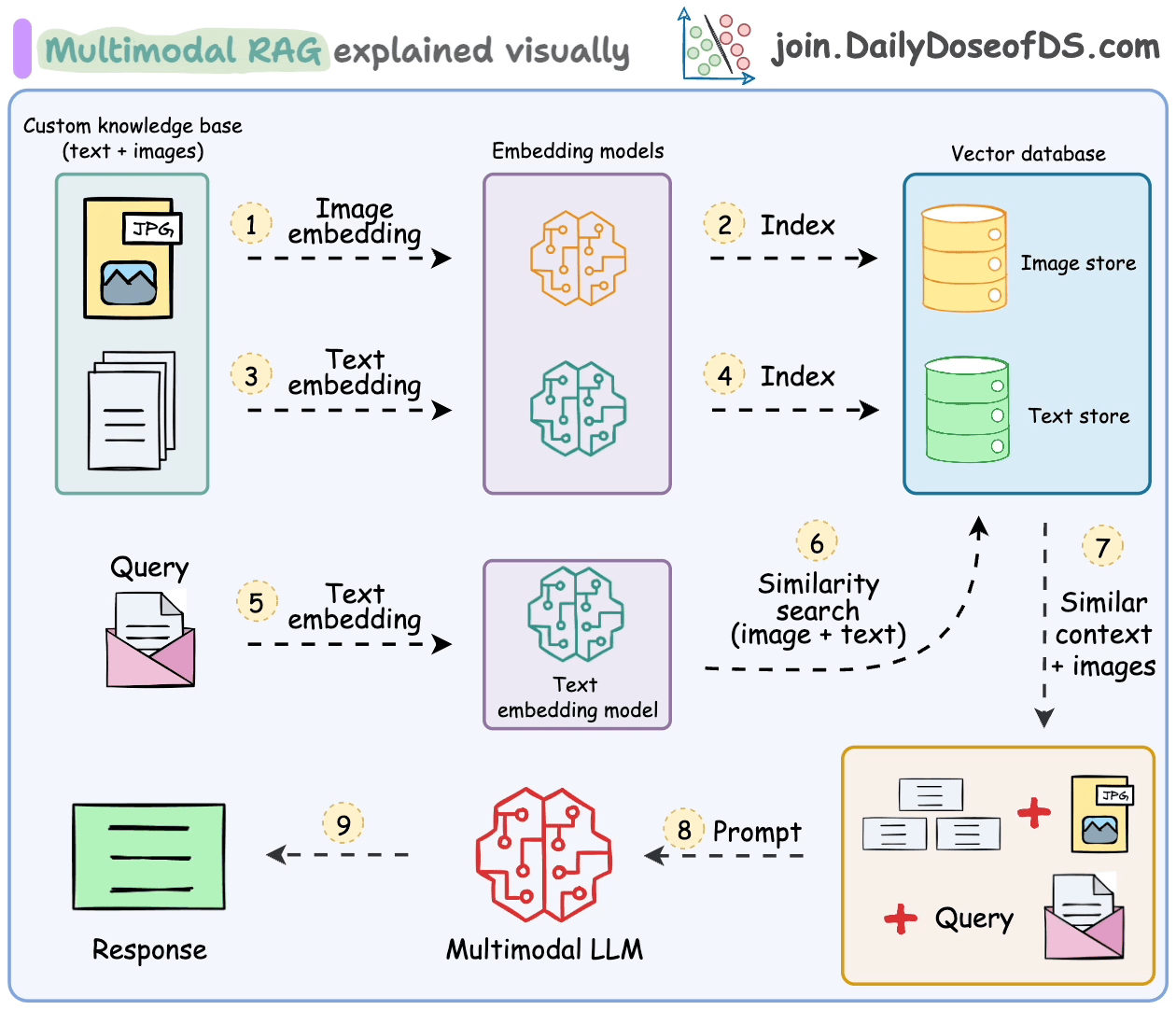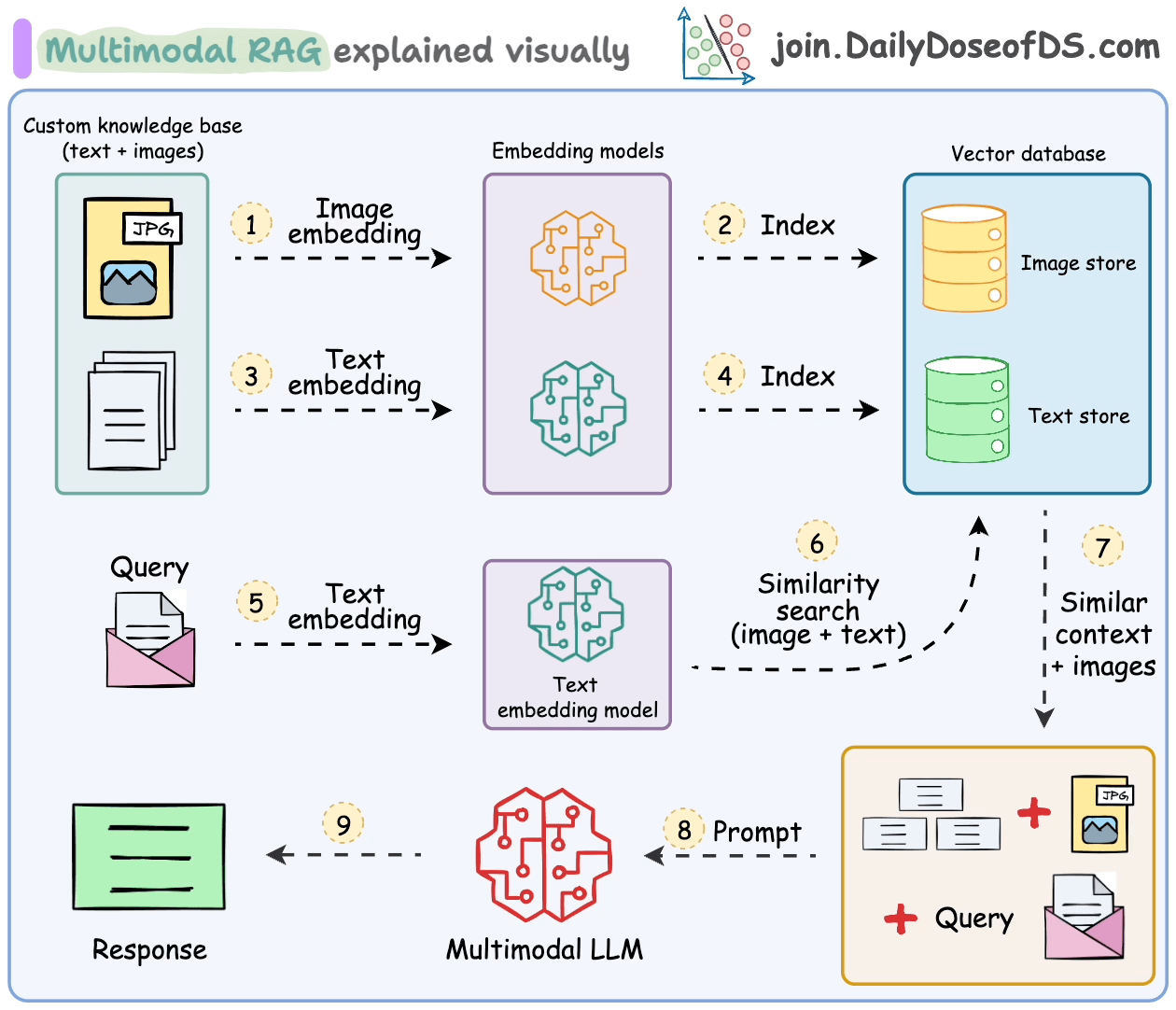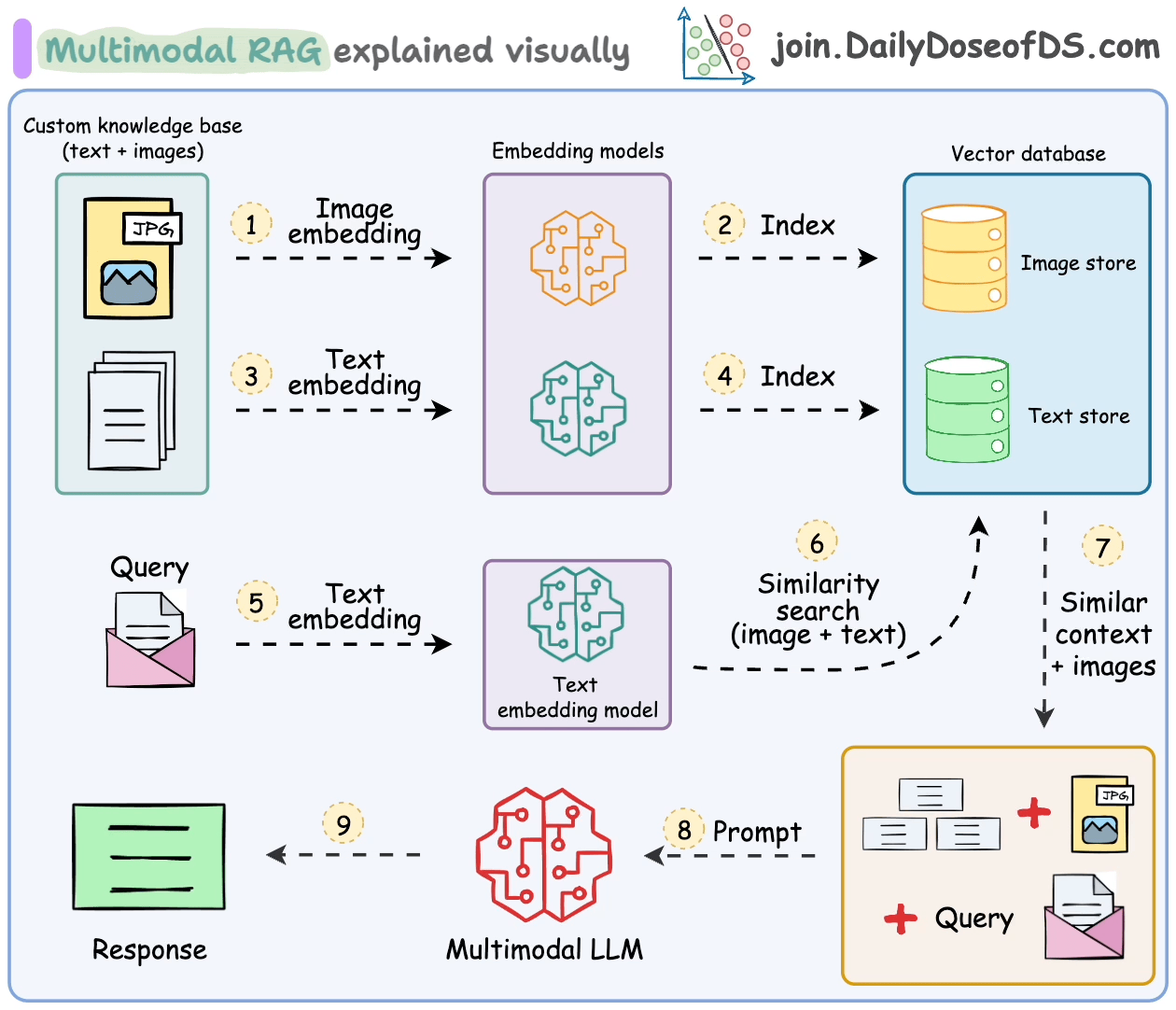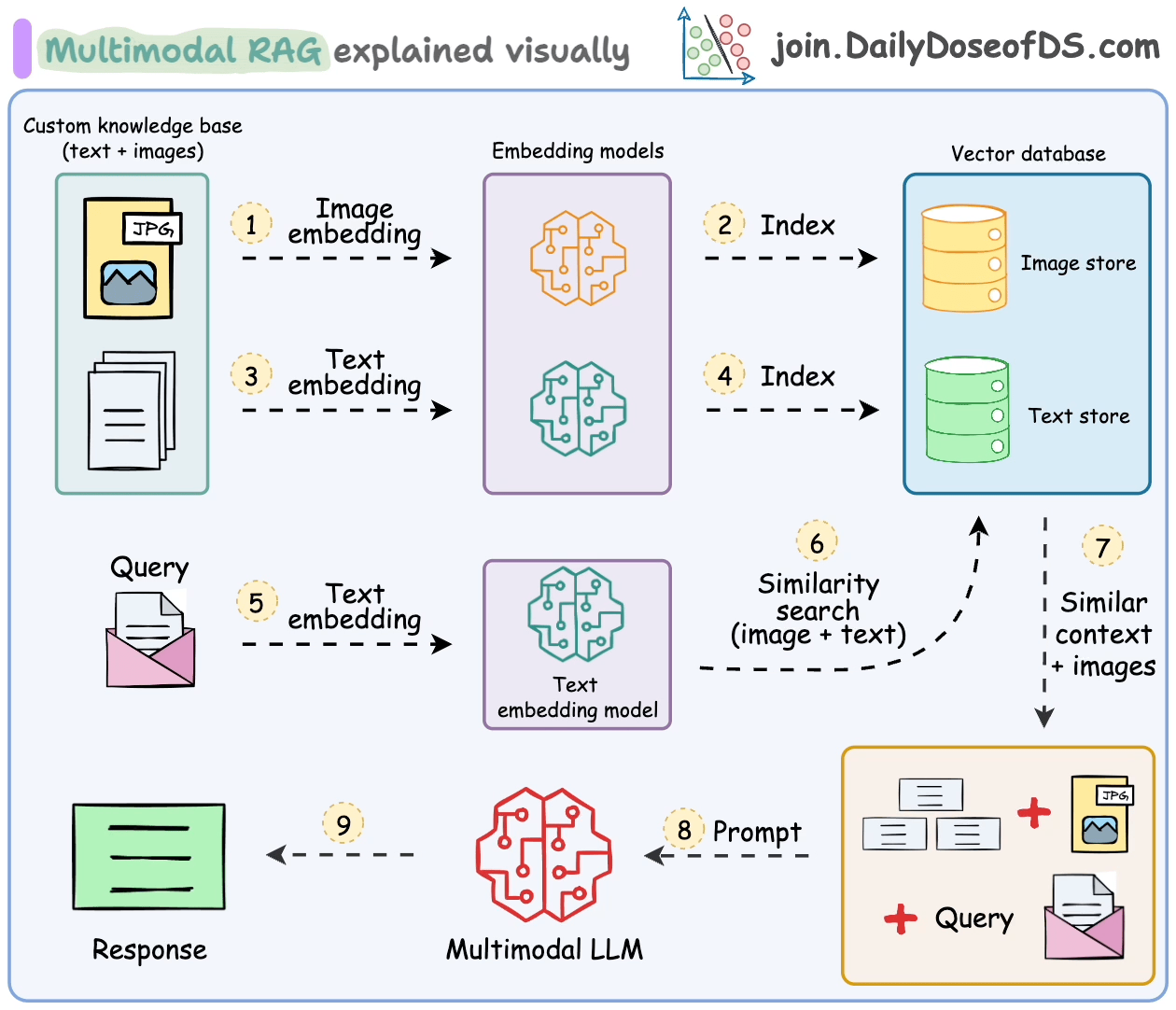
处理多模态数据会在解析、嵌入和检索方面带来额外的挑战。
多模态RAG系统旨在处理多种类型的数据并执行RAG操作。
让我们了解一下它的一些关键组件以及它们如何协同工作来实现这一点。
- 多模态大型语言模型(LLM):
多模态RAG的核心是一个能够处理文本和图像的多模态LLM。
这使得助手能够根据视觉和文本信息理解查询并提供响应。
- 文本嵌入模型:
我们使用文本嵌入模型将文本数据转换为数值向量。
这些嵌入捕捉了文本的语义含义,使得可以高效地检索相关文档。
- 图像嵌入模型:
同样,图像嵌入模型(例如OpenAI CLIP)将图像转换为数值向量。
这使得系统可以根据图像内容对图像进行索引和检索,从而弥合了视觉和文本数据之间的差距。
- 包含文本和图像的知识库:
我们的知识库是一个包含文本文档和图像的集合。
这个多模态数据集为助手生成响应提供了基础。
- 支持多模态嵌入的向量存储:
能够处理文本和图像嵌入的向量存储至关重要。
Qdrant是一个很好的选择,我经常使用它!
- 提示模板:
我们创建了一个包含文本和视觉上下文的提示模板。
这个模板指导多模态LLM使用检索到的文本和图像生成连贯的响应。
这些步骤也在下面的图中总结。
我们最近开始了一门关于构建RAG系统的速成课程,并已发布了四部分:
在第1部分中,我们探讨了RAG系统的基本组件、典型的RAG工作流程和工具栈,并学习了实现。
在第2部分中,我们了解了如何评估RAG系统(包括实现)。
在第3部分中,我们学习了优化RAG系统和处理数百万/数十亿向量的技术(包括实现)。
在第4部分中,我们探讨了多模态性并介绍了在复杂文档上构建RAG系统的技术——这些文档包含图像、表格和文本(包括实现)。
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA