- 发布于
来自中国的最新模型:Kimi K1.5:使用大语言模型扩展强化学习
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
🚀 介绍Kimi k1.5 --- 一个O1级多模态模型
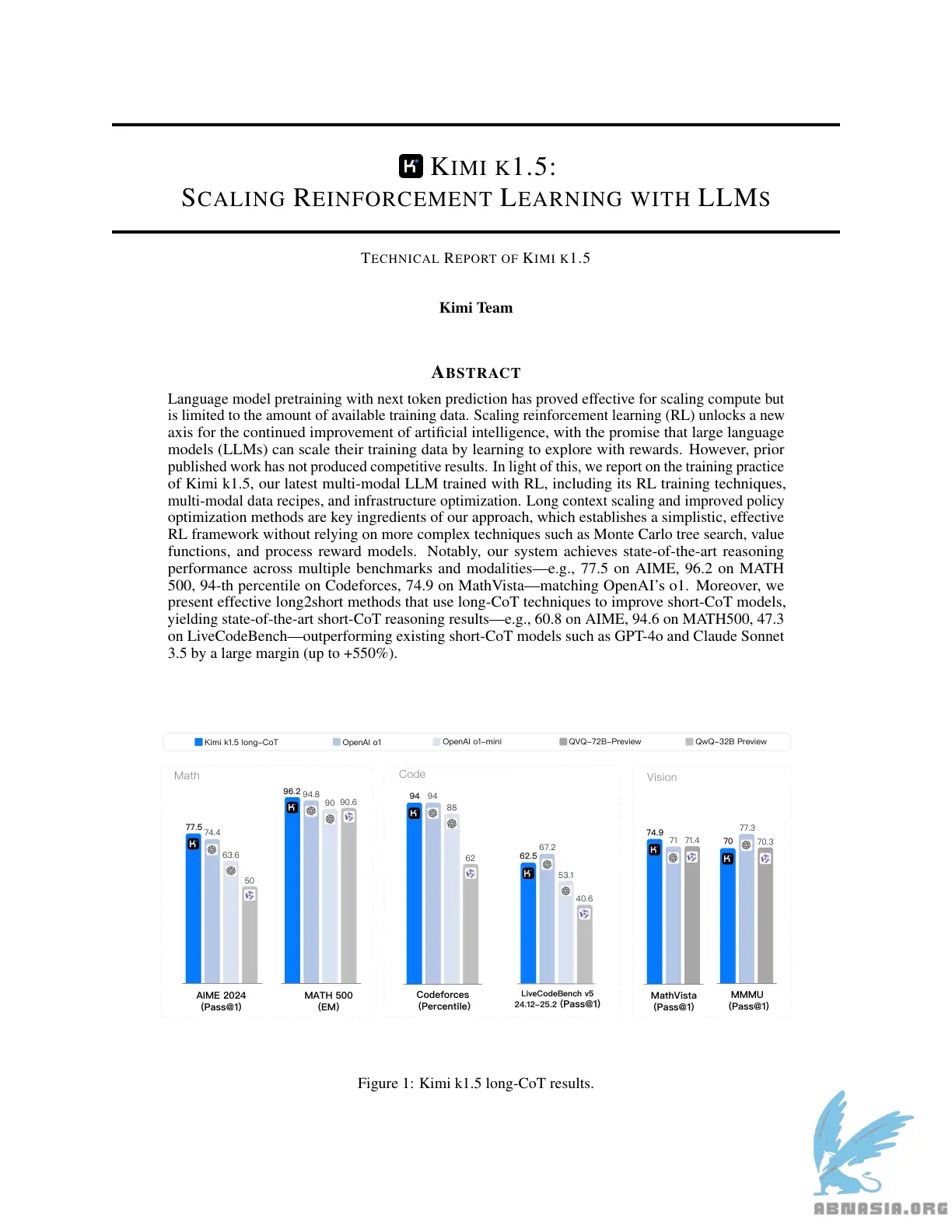

Sota短CoT性能,超越GPT-4o和Claude Sonnet 3.5,在📐AIME、📐MATH-500、💻LiveCodeBench等基准测试中以大幅度优势(最高+550%)领先
长CoT性能在多个模态(👀MathVista、📐AIME、💻Codeforces等)中与o1相匹配
语言模型预训练使用下一个标记预测已被证明对扩大计算有效,但受到可用训练数据量的限制。扩大强化学习(RL)解锁了人工智能持续改进的新维度,承诺大型语言模型(LLM)可以通过学习探索来扩大其训练数据。然而,之前发表的工作并没有产生具有竞争力的结果。因此,我们报告了Kimi k1.5的训练实践,包括其RL训练技术、多模态数据配方和基础设施优化。长上下文缩放和改进的策略优化方法是我们方法的关键成分,这些成分建立了一个简单有效的RL框架,而无需依赖更复杂的技术,如蒙特卡罗树搜索、价值函数和过程奖励模型。值得注意的是,我们的系统在多个基准测试和模态中实现了最先进的推理性能——例如,AIME达到77.5,MATH 500达到96.2,Codeforces达到94百分位,MathVista达到74.9——与OpenAI的o1相匹配。此外,我们提出了一种有效的长短方法,使用长CoT技术来改进短CoT模型,实现了最先进的短CoT推理结果——例如,AIME达到60.8,MATH500达到94.6,LiveCodeBench达到47.3——以大幅度优势(最高+550%)超越现有的短CoT模型,如GPT-4o和Claude Sonnet 3.5。
Kimi k1.5的设计和训练有几个关键要素。
长上下文缩放。我们将RL的上下文窗口扩大到128k,并观察到随着上下文长度的增加,性能持续改进。我们的方法背后的一个关键思想是使用部分回滚来提高训练效率——即通过重用以前轨迹的大部分来采样新的轨迹,避免重新生成新轨迹的成本。我们的观察结果表明,上下文长度是RL与LLM持续扩大的一个关键维度。
改进的策略优化。我们推导出RL与长CoT的公式,并使用在线镜像下降法的变体进行强健的策略优化。该算法进一步通过我们的有效采样策略、长度惩罚和数据配方优化得到改进。
简单框架。长上下文缩放与改进的策略优化方法相结合,建立了一个简单的RL框架,用于学习LLM。由于我们能够扩大上下文长度,学习到的CoT表现出规划、反思和纠正的特性。增加上下文长度的效果是增加搜索步骤的数量。因此,我们展示了在不依赖更复杂技术(如蒙特卡罗树搜索、价值函数和过程奖励模型)的情况下可以实现强大的性能。
多模态。我们的模型是在文本和视觉数据上联合训练的,具有联合推理两个模态的能力。
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA