- 发布于
聊天机器人排名:不同任务,不同的赢家
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
Chatbot Arena 的一个鲜为人知的功能是,它会根据类别(如数学、编程或创意写作)以及风格进行评分。
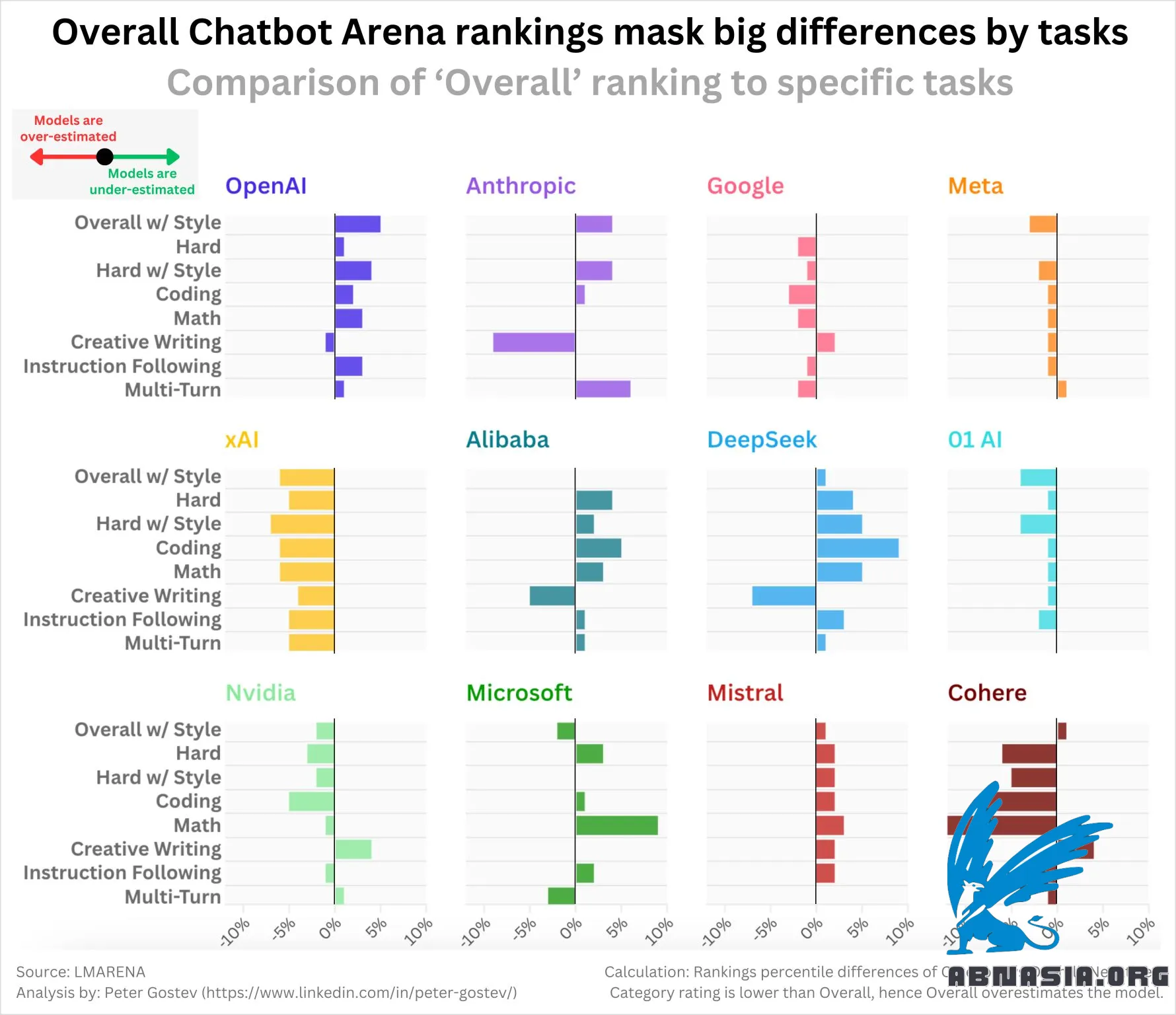
这意味着我们可以看到模型在某些任务上的“核心”性能。
我对探索某些实验室是否在“总体”评级中对各种任务的表现高估或低估感兴趣。结果老实说并不是我所期望的:
OpenAI 模型大多被低估(即,如果你查看单独的评级,它们会更强大)
xAI、Google、Meta、01(实验室,而不是模型)、Cohere、Nvidia 都被高估
DeepSeek、Mistral、阿里巴巴(Qwen 模型)被低估
人本主义模型结果更为混合 - 创意写作的高估结果相当有趣
提示:如果你想查看最佳模型,我建议查看“具有样式控制的困难任务” - Sonnet 3.6、o1-preview 和 Google-Exp-1121 并列第一 - 它更好地符合我对最佳模型的直觉。
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA