- 发布于
LLM(大型语言模型)如何生成文本?
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
这绝非易事。
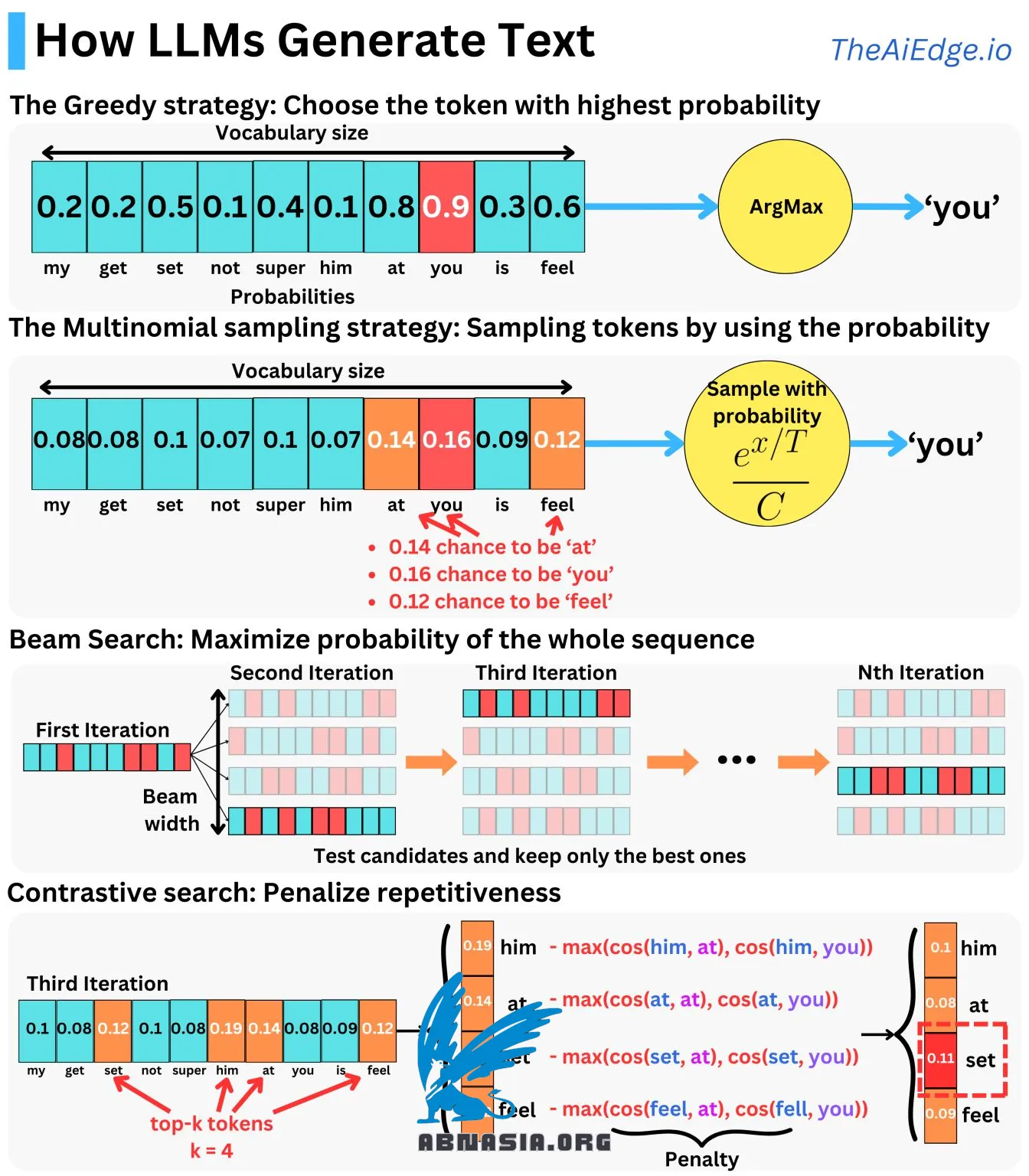
生成文本绝非易事。大型语言模型(LLMs)被优化为预测下一个标记的概率,但我们如何利用此信息生成文本呢?
一种简单的方法是使用模型生成的概率向量,选择概率最高的词,并自回归。这是贪婪方法,但它往往会生成重复的句子,当句子太长时会退化。另一种方法是使用模型生成的概率,并根据这些概率对词进行采样。通常,我们使用温度参数来调整此过程的随机性水平。这使得生成的句子不那么重复,更加富有创意。
但是,这两种技术都存在问题。当我们生成一个句子时,我们希望最大化整个输出序列的概率,而不仅仅是下一个标记的概率:
P(输出序列 | 提示)
幸运的是,我们可以将此概率表示为预测下一个标记的概率的乘积:
P(标记 1,..,标记 N | 提示)= P(标记 1 | 提示)x ... P(标记 N | 提示,标记 1,...,标记 N - 1)
但是,精确解决这个问题是一个NP-hard问题。因此,我们可以通过在每次迭代中选择k个候选标记,测试它们,并保留最大化整个序列概率的k个序列来近似解决这个问题。最后,我们只需选择概率最高的序列即可。这被称为束搜索生成,可以与贪婪和多项式方法混合使用。
另一种方法是对比搜索,我们考虑额外的指标,如流畅度或多样性。在每次迭代中,我们选择候选标记,使用先前生成的标记的相似度指标来惩罚概率,并选择最大化新评分的标记。
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA