- 发布于
OpenAi O1:非常好的基准测试
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
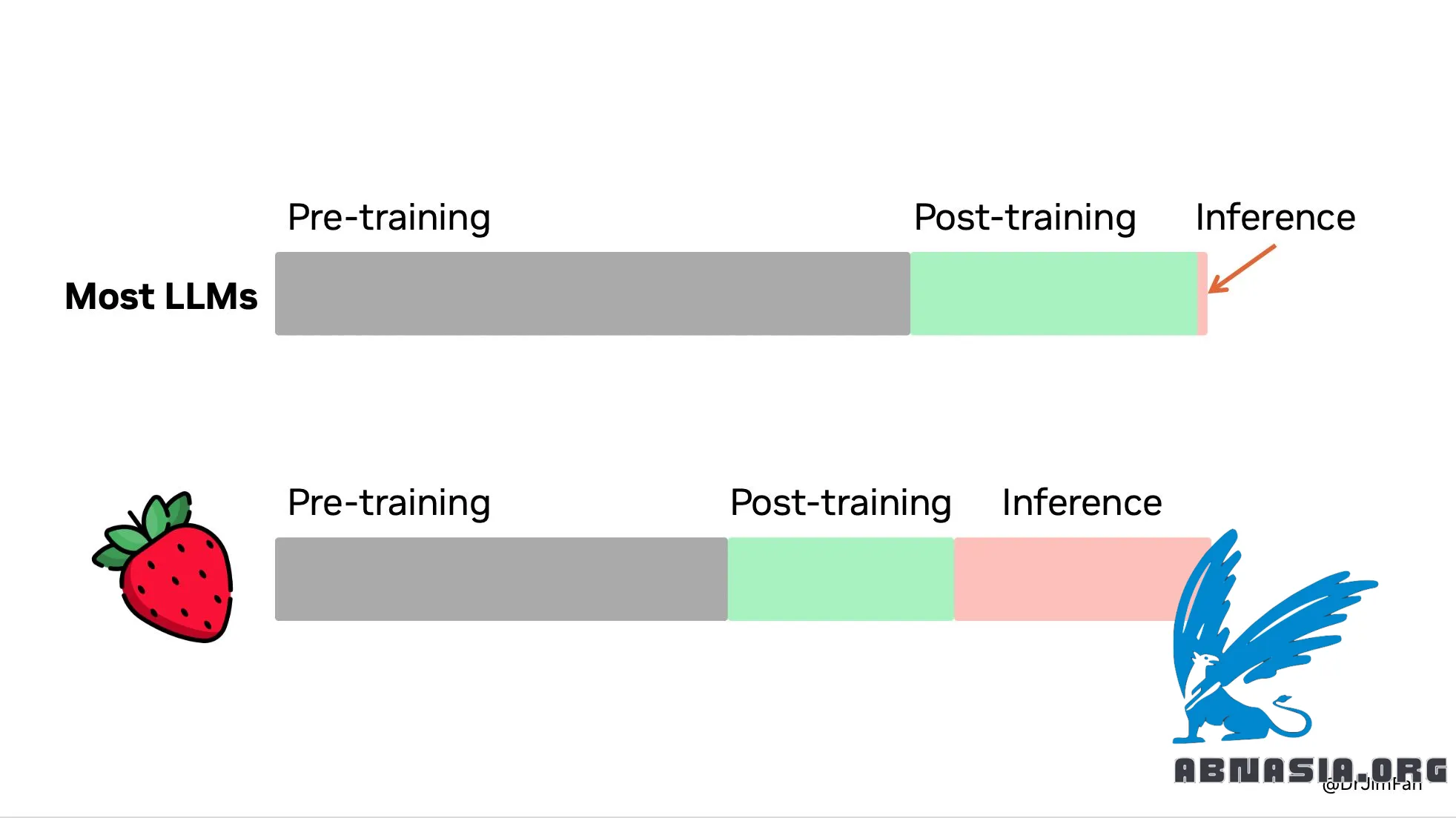
"OpenAI 草莓 (o1) 已出炉!我们终于看到推理时间扩展的范例在生产中得到普及和部署。正如萨顿在《痛苦的教训》中所说,只有两种技术可以随着计算无限扩展:学习和搜索。是时候将焦点转移到后者了。
1.你不需要一个巨大的模型来进行推理。许多参数专门用于记忆事实,以便在琐事 QA 等基准测试中表现良好。可以从知识中分解出推理,即一个知道如何调用浏览器和代码验证器等工具的小型推理核心。预训练计算量可能会减少。
大量计算转移到推理服务,而不是训练前/训练后。法学硕士是基于文本的模拟器。通过在模拟器中推出许多可能的策略和场景,模型最终将收敛到良好的解决方案。这个过程是一个经过充分研究的问题,就像 AlphaGo 的蒙特卡罗树搜索(MCTS)一样。
OpenAI 肯定很早之前就已经弄清楚了推理缩放定律,而学术界最近才发现这一定律。上个月,Arxiv 上相隔一周发表了两篇论文:
大型语言猴子:通过重复采样扩展推理计算。布朗等人。发现 DeepSeek-Coder 在 SWE-Bench 上从 1 个样本的 15.9% 提高到 250 个样本的 56%,击败了 Sonnet-3.5。
优化 LLM 测试时间计算比缩放模型参数更有效。斯内尔等人。发现 PaLM 2-S 通过测试时搜索在数学上击败了 14 倍大的模型。
- 将o1产品化比确定学术基准要困难得多。对于野外推理问题,如何决定何时停止搜索?奖励函数是什么?成功的标准?何时在循环中调用代码解释器等工具?如何考虑这些 CPU 进程的计算成本?他们的研究帖子没有太多分享。
5.草莓很容易成为数据飞轮。如果答案正确,整个搜索轨迹将成为训练示例的小型数据集,其中包含正面奖励和负面奖励。
这反过来又改进了 GPT 未来版本的推理核心,类似于 AlphaGo 的价值网络(用于评估每个棋盘位置的质量)如何随着 MCTS 生成越来越精细的训练数据而改进。"
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA