- 发布于
什么是优化器,它们为什么存在?
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
我们都知道,优化器指导学习过程:它们通过调整参数来最小化损失函数,从而帮助神经网络学习。
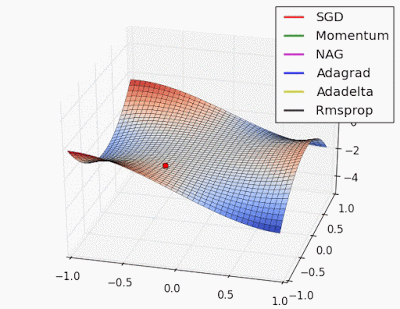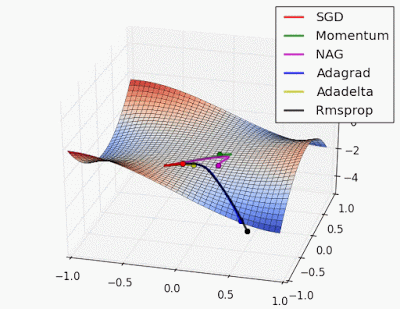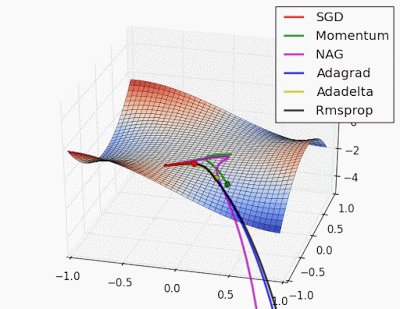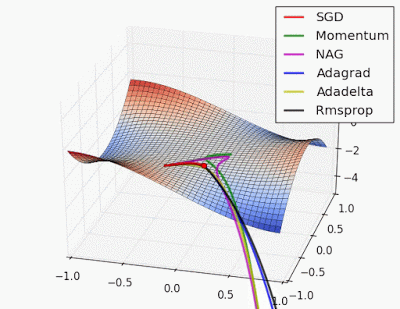
😀
想象一下,你和朋友们一起去公路旅行,但迷路了。
周围的环境是起伏的山丘,而且天色已经暗了。幸运的是,你的车上装有GPS导航系统。
想象优化器(optimizer)就像你的GPS导航系统。
就像GPS导航系统可以引导你沿着最快或最平滑的路线到达目的地一样,优化器可以引导训练过程朝着损失值(目的地)降低的方向前进。
一个基本的优化器,如简单的梯度下降法,类似于使用基本的路线地图:它可能最终会引导你到达目的地,但可能会导致绕路(没有实时更新,道路中断等)。
而自适应优化器,如Adam或RMSProp,则类似于高级GPS导航系统,可以实时调整障碍并选择高效的路径到达目的地。
没有GPS导航系统,你可能会花费几个小时来导航未知的路线。
同样,没有优化器,训练模型将是一个漫长而艰难的过程,难以有效地从数据中学习。
那么,为什么有这么多选项?
首先,让我们了解优化器解决的问题:
1️⃣ 高效地搜索权重空间 - 训练神经网络意味着在复杂的非凸权重空间中导航,目标是找到最小化损失的权重组合。
2️⃣ 稳定可靠的收敛 - 在训练过程中,模型可能会陷入局部最小值,或者权重可能会在没有收敛的情况下振荡。优化器可以帮助管理这些挑战。
故事始于很久以前,最初是为了解决数学中的优化问题。
梯度下降法(GD)始于19世纪中叶(真的那么久?),然后出现了随机梯度下降法(SGD)和小批量梯度下降法(Mini Batch GD)- 虽然它们有效,但它们在收敛速度和复杂数据上的稳定性方面存在局限性。
为了解决这些问题,研究人员开发了更复杂的优化器,它们可以根据学习率或使用动量来更好地处理不同的梯度。
然后出现了动量优化器(如SGD with Momentum)-> 自适应优化器(如AdaGrad,RMSProp)-> Adam(动量和自适应方法的组合)-> 和新方法(如AdamW,LAMB和Lion),它们解决了特定的训练挑战。
新的优化器将继续出现,每个优化器都旨在解决特定的挑战,如训练稳定性、效率或适应新架构。一些优化器将成为主流,另一些将消失,而一些将经受时间的考验。
但是,它们的核心目的 - 高效有效地引导训练过程 - 始终保持不变。
最后一件事,当你犹豫不决时,只需要使用Adam 😀
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA