- Veröffentlicht am
4 Strategien für Multi-GPU-Training visuell erklärt.
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Standardmäßig nutzen Deep-Learning-Modelle nur eine einzelne GPU für das Training, selbst wenn mehrere GPUs verfügbar sind. Hier ist ein Trick.
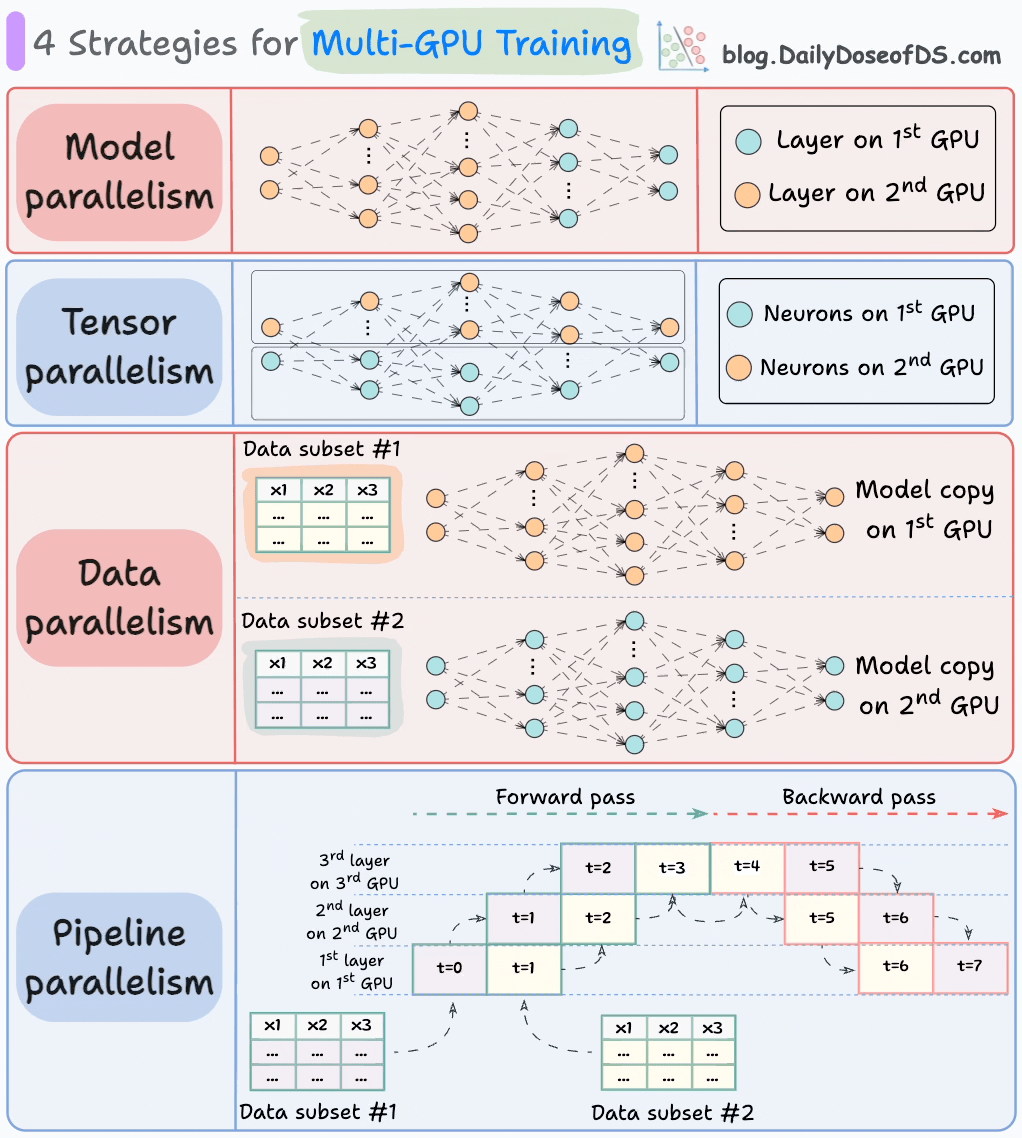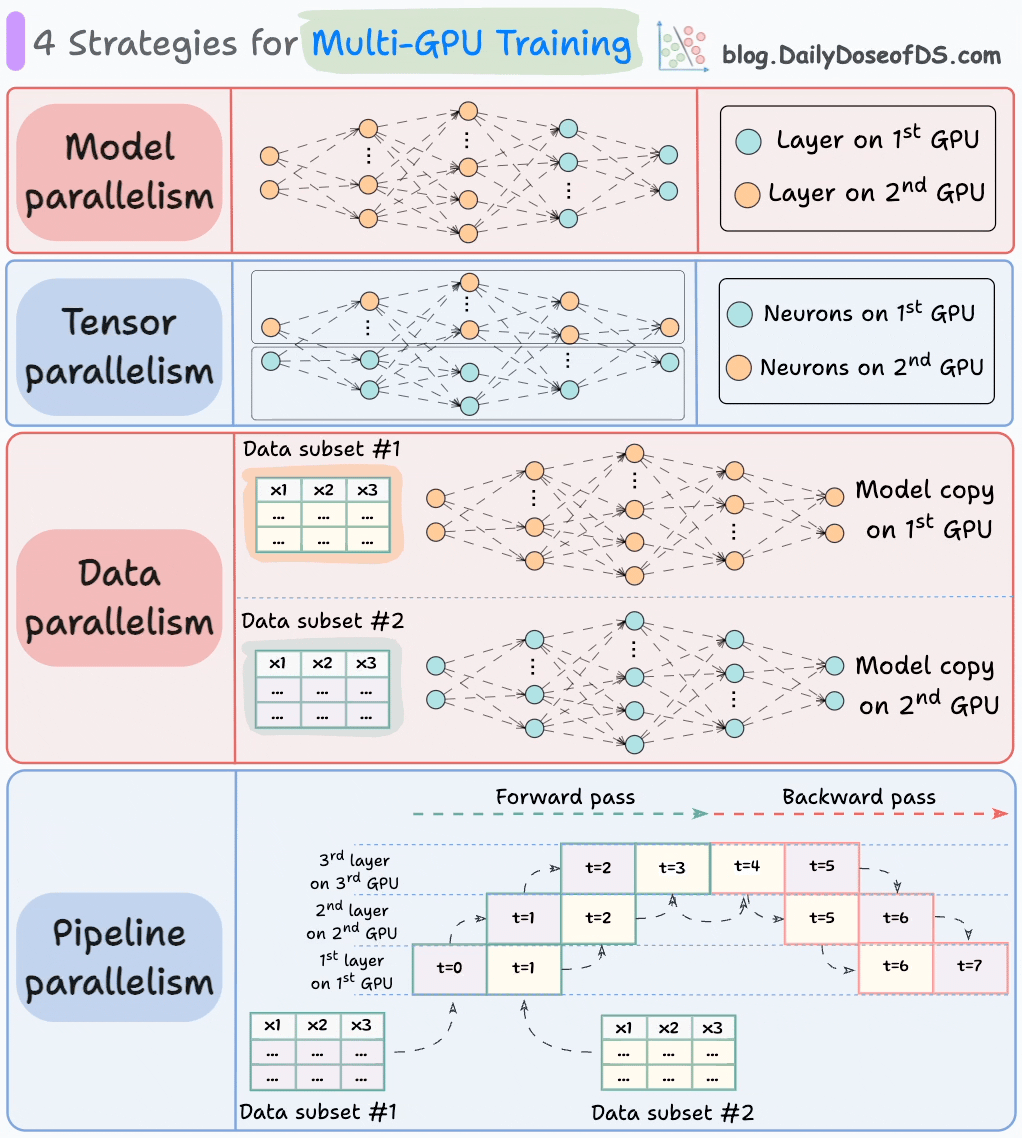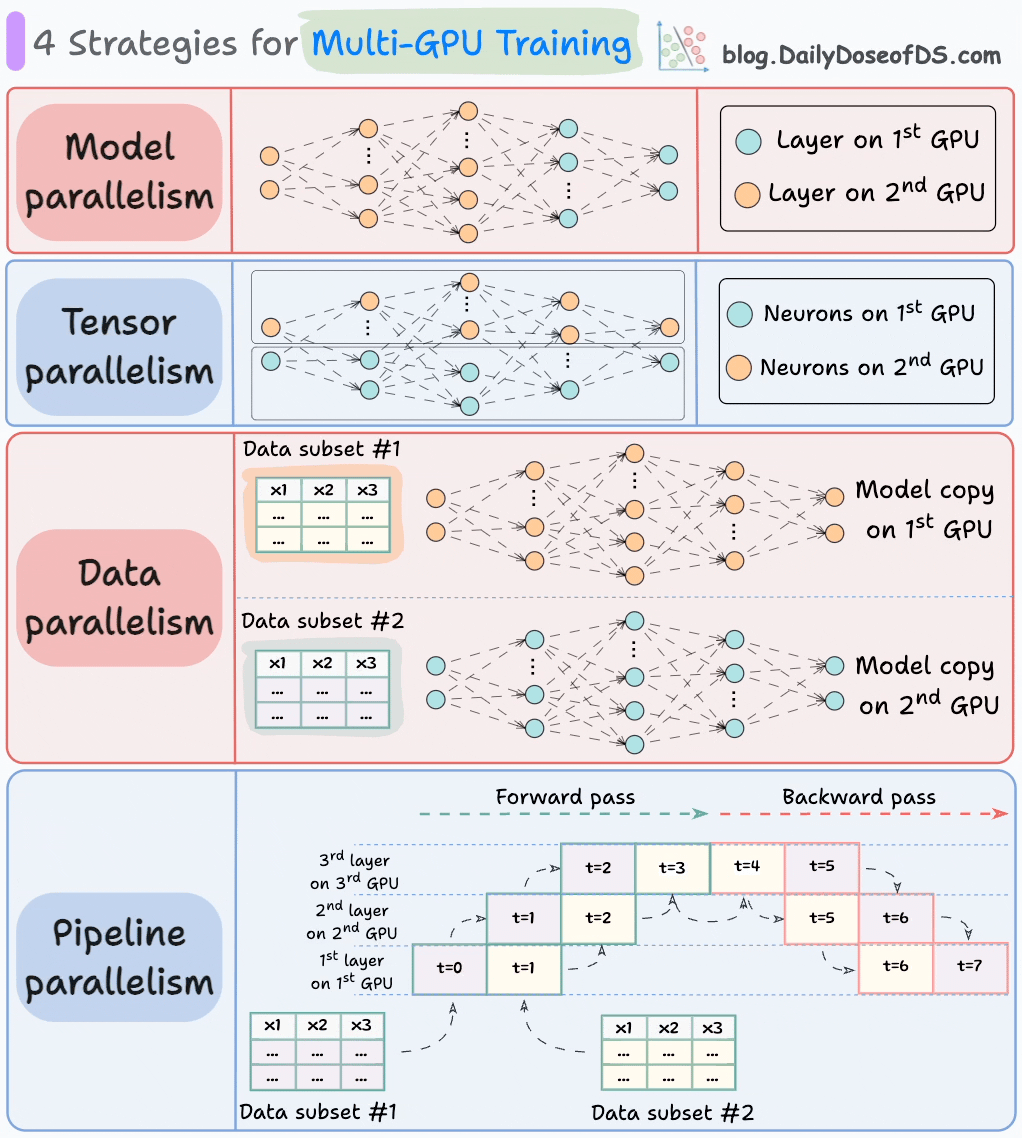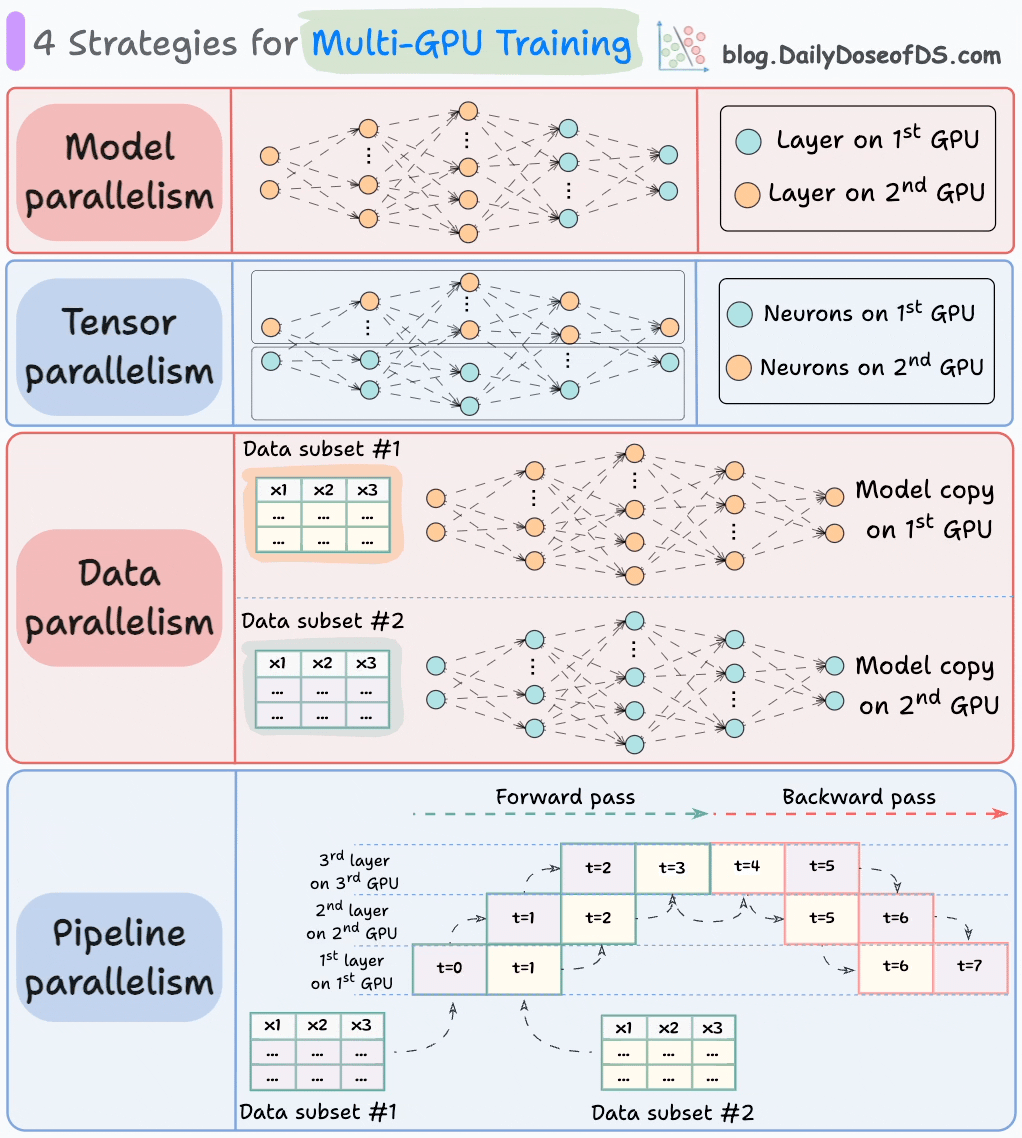
Ein idealer Weg, um fortzufahren (besonders in Big-Data-Einstellungen), ist es, die Trainingslast auf mehrere GPUs zu verteilen.
Das folgende Diagramm zeigt vier gängige Strategien für das Training mit mehreren GPUs:
- Model-Parallelität
- Verschiedene Teile (oder Schichten) des Modells werden auf verschiedenen GPUs platziert.
- Nützlich für riesige Modelle, die nicht auf einer einzelnen GPU passen.
- Model-Parallelität führt jedoch auch zu schwerwiegenden Engpässen, da sie einen Datenfluss zwischen den GPUs erfordert, wenn Aktivierungen von einer GPU auf eine andere GPU übertragen werden.
- Tensor-Parallelität
- Verteilt und verarbeitet einzelne Tensor-Operationen auf mehreren Geräten oder Prozessoren.
- Sie basiert auf der Idee, dass eine große Tensor-Operation, wie die Matrixmultiplikation, in kleinere Tensor-Operationen unterteilt werden kann und jede kleinere Operation auf einem separaten Gerät oder Prozessor ausgeführt werden kann.
- Solche Parallelisierungsstrategien sind inhärent in Standardimplementierungen von PyTorch und anderen Deep-Learning-Frameworks integriert, aber sie werden in einer verteilten Umgebung viel deutlicher.
- Daten-Parallelität
- Repliziert das Modell auf allen GPUs.
- Teilt die verfügbaren Daten in kleinere Batches auf und jeder Batch wird von einer separaten GPU verarbeitet.
- Die Updates (oder Gradienten) von jeder GPU werden dann aggregiert und verwendet, um die Modellparameter auf jeder GPU zu aktualisieren.
- Pipeline-Parallelität
Dies wird oft als Kombination aus Daten-Parallelität und Model-Parallelität betrachtet.
Das Problem mit der Standard-Model-Parallelität ist, dass die 1. GPU untätig bleibt, wenn Daten durch die Schichten auf der 2. GPU propagiert werden:
Pipeline-Parallelität behebt dies, indem die nächste Mikro-Batch-Daten geladen werden, sobald die 1. GPU die Berechnungen auf dem 1. Mikro-Batch abgeschlossen und Aktivierungen an die Schichten auf der 2. GPU übertragen hat.
Der Prozess sieht so aus:
↳ 1. Mikro-Batch passiert die Schichten auf der 1. GPU.
↳ 2. GPU erhält Aktivierungen auf dem 1. Mikro-Batch von der 1. GPU.
↳ Während die 2. GPU die Daten durch die Schichten passiert, wird ein weiterer Mikro-Batch auf der 1. GPU geladen.
↳ Und der Prozess geht weiter.
- Die GPU-Auslastung verbessert sich dramatisch auf diese Weise. Dies ist offensichtlich aus der Animation unten, in der mehrere GPUs zur gleichen Zeit genutzt werden (siehe t=1, t=2, t=5 und t=6).
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA