- Veröffentlicht am
Beschleunigen Sie die LLM-Auswertung mit spekulativer Dekodierung
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Erinnern Sie sich an MSN Messenger?
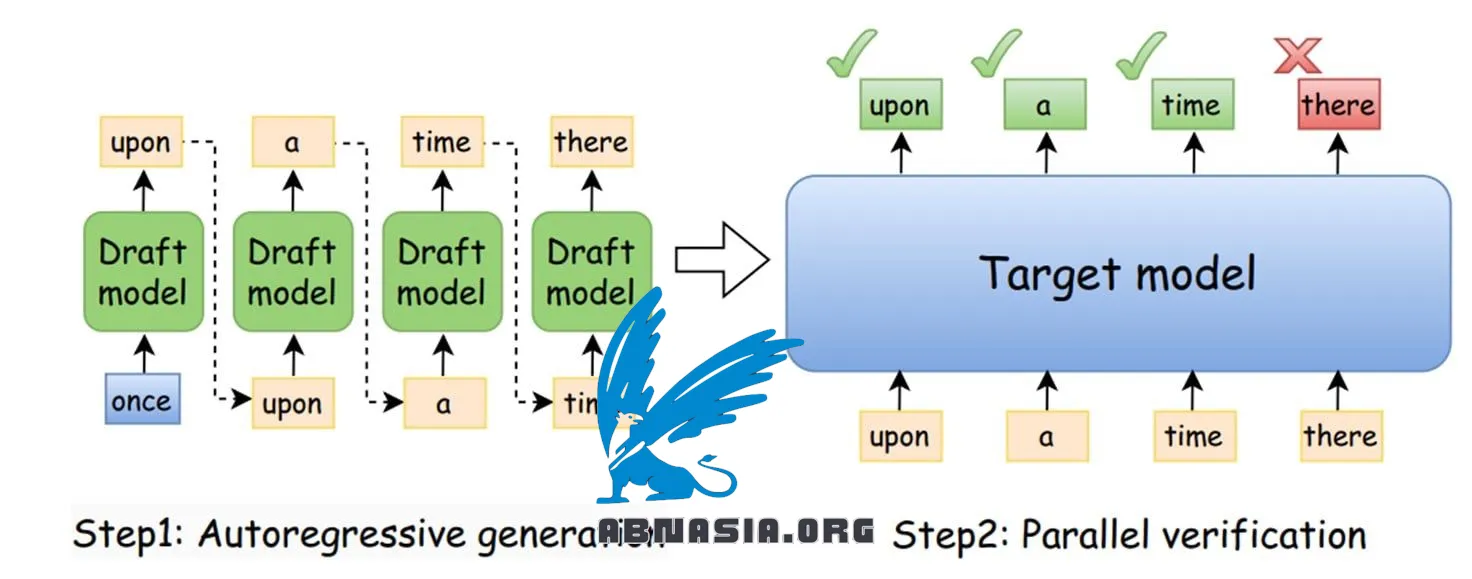
Was ist Spekulative Dekodierung?
Es handelt sich um eine Technik, die ein Entwurfsmodell (SLM) verwendet, um gemeinsam mit dem Haupt-LLM zu arbeiten:
1️⃣ Das Entwurfsmodell prognostiziert die nächsten K Token.
2️⃣ Das Haupt-LLM überprüft und korrigiert sie bei Bedarf.
3️⃣ Wenn es eine Diskrepanz gibt, setzt das LLM die Sequenz fort und das Entwurfsmodell beginnt mit aktualisiertem Input neu.
Warum es funktioniert:
• Bis zu 3-mal schneller für Code-Vervollständigung.
• Bis zu 2-mal schneller für Zusammenfassung, Textgenerierung und Anweisungen.
Vortrainierte Entwurfsmodelle:
• Llama-3.1-8B-FastDraft-150M
• Phi-3-mini-FastDraft-50M
Warum es wichtig ist:
Es macht LLMs schneller, effizienter und bereit für reale Aufgaben.
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA