- Veröffentlicht am
Float32, Float16 oder BFloat16!
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Warum ist das für Deep Learning wichtig?
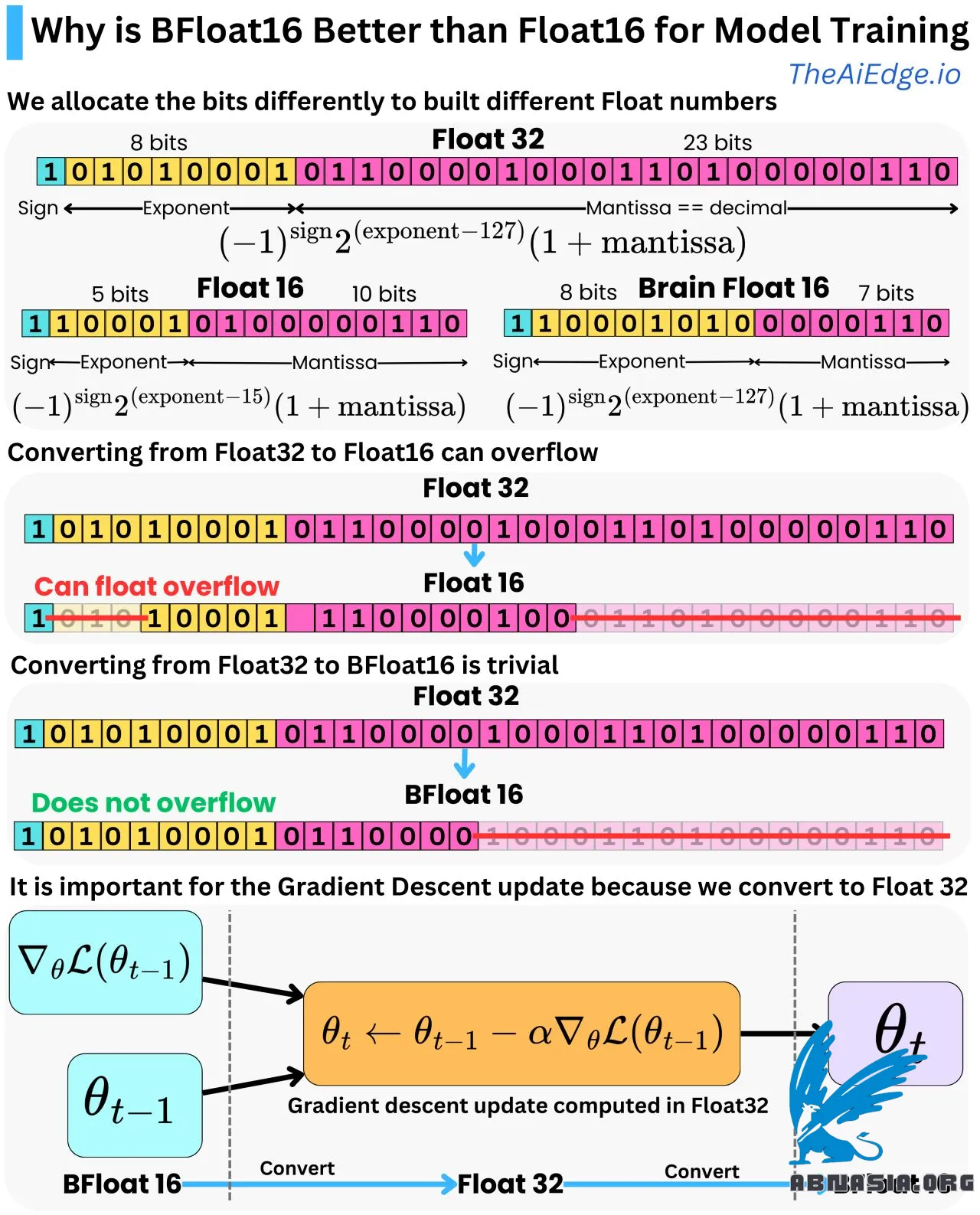
Das sind einfach verschiedene Genauigkeitsgrade. Float32 ist eine Möglichkeit, eine Gleitkommazahl mit 32 Bits (1 oder 0) darzustellen, und Float16/BFloat16 ist eine Möglichkeit, dieselbe Zahl mit nur 16 Bits darzustellen. Mit Float32 weisen wir das erste Bit zu, um das Vorzeichen darzustellen, die nächsten 8 Bits, um den Exponenten darzustellen, und die nächsten 23 Bits, um die Dezimalstellen (auch Mantisse genannt) darzustellen. Wir können von der Bit-Darstellung zur Dezimal-Darstellung gelangen, indem wir die einfache Formel verwenden:
Float32 = (-1)^Vorzeichen * 2^(Exponent - 127) * (1 + Mantisse)
Und dies kann zwischen -3,4e^38 und 3,4e^38 liegen.
Float16 verwendet 1 Bit für das Vorzeichen, 5 Bits für den Exponenten und 10 Bits für die Mantisse mit der Formel:
Float16 = (-1)^Vorzeichen * 2^(Exponent - 15) * (1 + Mantisse)
Und der Bereich liegt zwischen -6,55e^4 und 6,55e^4 (also ein viel kleinerer Bereich!). Um von Float32 auf Float16 umzurechnen, müssen Sie einfach die Ziffern entfernen, die nicht in die 5 und 10 Bits passen, die für den Exponenten und die Mantisse zugewiesen sind. Bei der Mantisse erstellen Sie einfach einen Rundungsfehler, aber wenn die Float32-Zahl größer als 6,55e^4 ist, erstellen Sie einen Float-Überlauf-Fehler! Es ist also durchaus möglich, Umrechnungsfehler von Float32 auf Float16 zu erhalten.
Brain Float 16 (BFloat16) ist eine weitere Gleitkommadarstellung in 16 Bits. Wir bieten weniger Dezimalgenauigkeit, aber denselben Bereich wie Float32. Wir haben 8 Bits für den Exponenten und 7 Bits für die Mantisse mit der gleichen Umrechnungsformel:
BFloat16 = (-1)^Vorzeichen * 2^(Exponent - 127) * (1 + Mantisse)
Und bieten denselben Bereich wie Float32 [-3,4e^38 und 3,4e^38]. Die Umrechnung von Float32 auf BFloat16 ist also trivial, da Sie einfach die Mantisse abrunden müssen.
Dies ist für Deep Learning sehr wichtig, da im Backpropagation-Algorithmus die Modellparameter durch einen Gradientenabstiegs-Optimizer (z. B. Adam) aktualisiert werden und die Berechnungen mit Float32-Genauigkeit durchgeführt werden, um weniger Rundungsfehler zu gewährleisten. Die Modellparameter und die Gradienten werden normalerweise im Speicher in Float16 gespeichert, um den Druck auf den Speicher zu reduzieren, sodass wir vor und zurück zwischen Float16 und Float32 umrechnen müssen. BFloat16 ist eine gute Wahl, da es Float-Überlauf-Fehler verhindert und gleichzeitig genug Genauigkeit für die Vorwärts- und Rückwärts-Pässe des Backpropagation-Algorithmus bietet.
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA