- Veröffentlicht am
Multimodale RAG, visuell erklärt 👇
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Vanilla-RAG-Systeme funktionieren gut bei Textdokumenten. Aber Dokumente aus der realen Welt enthalten Text + Bilder + Tabellen und was weiß ich nicht. Was tun dann?
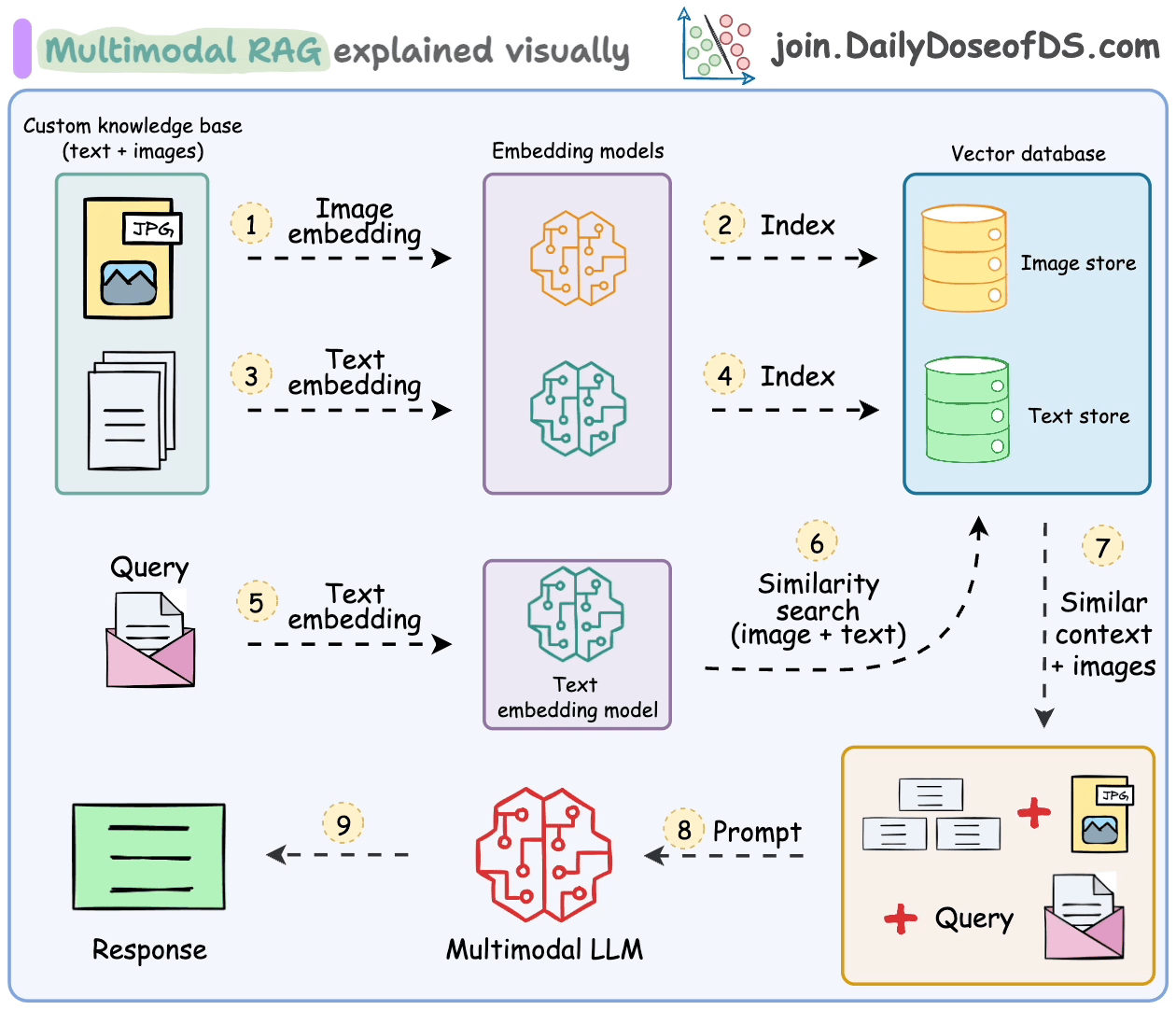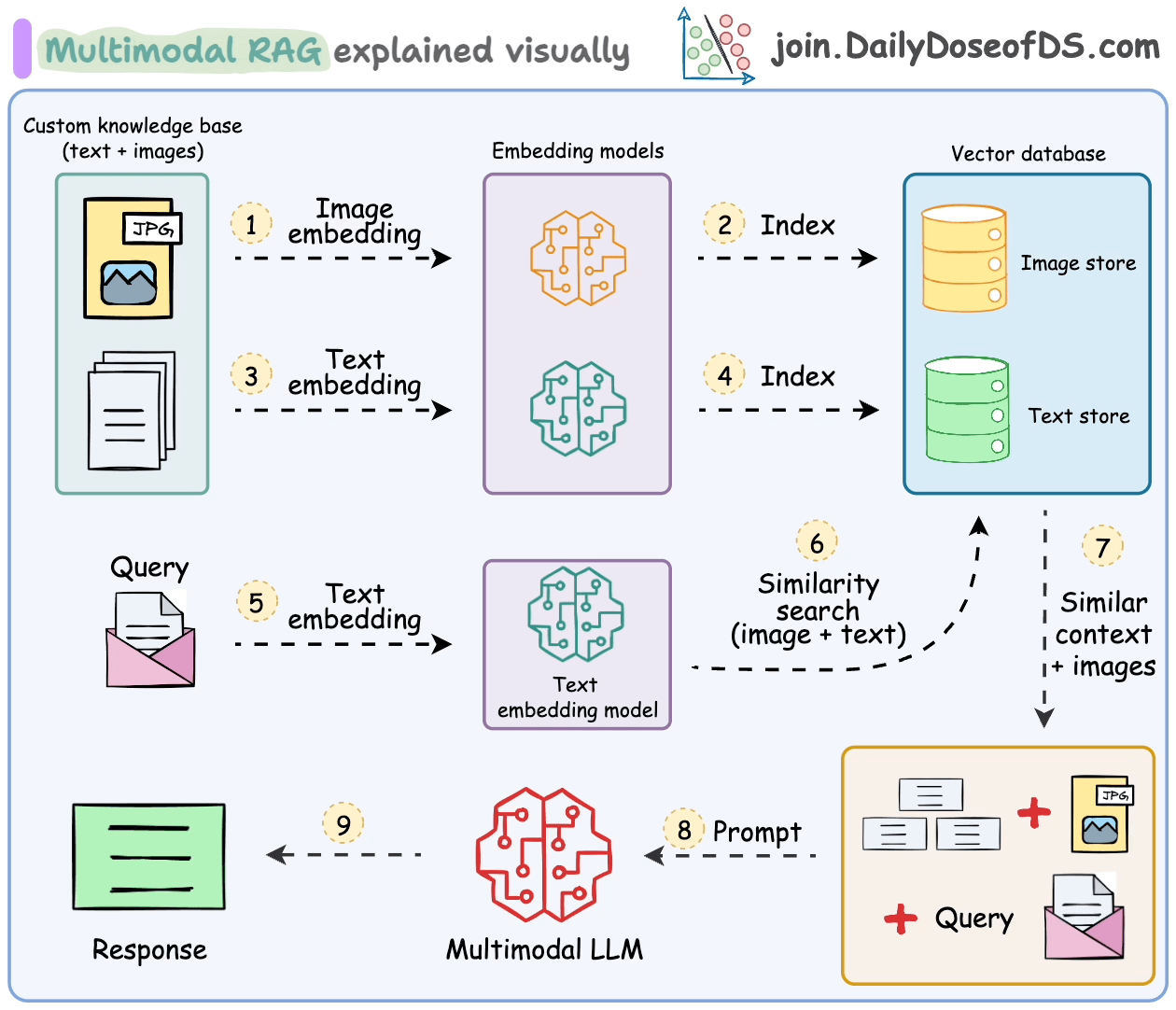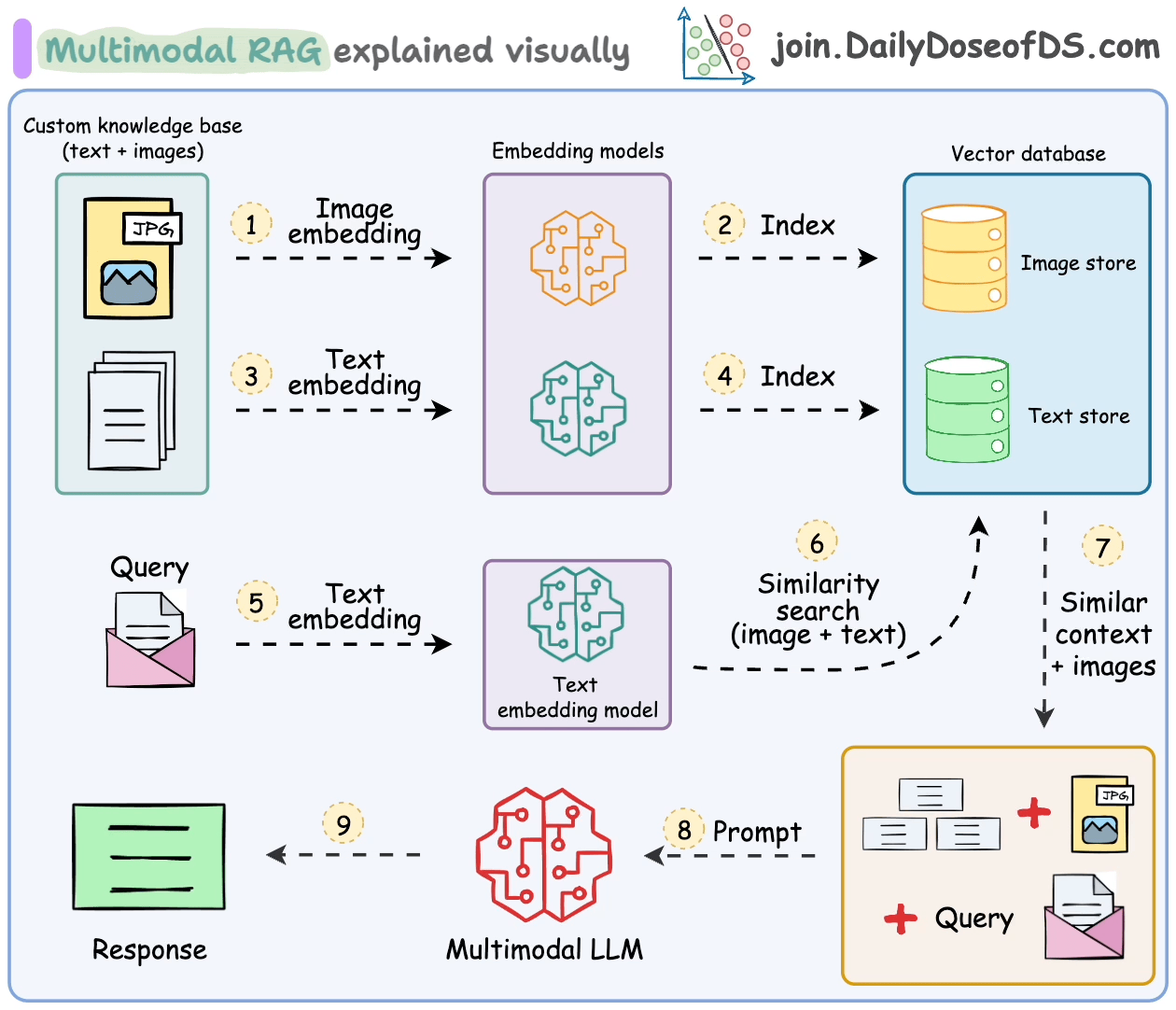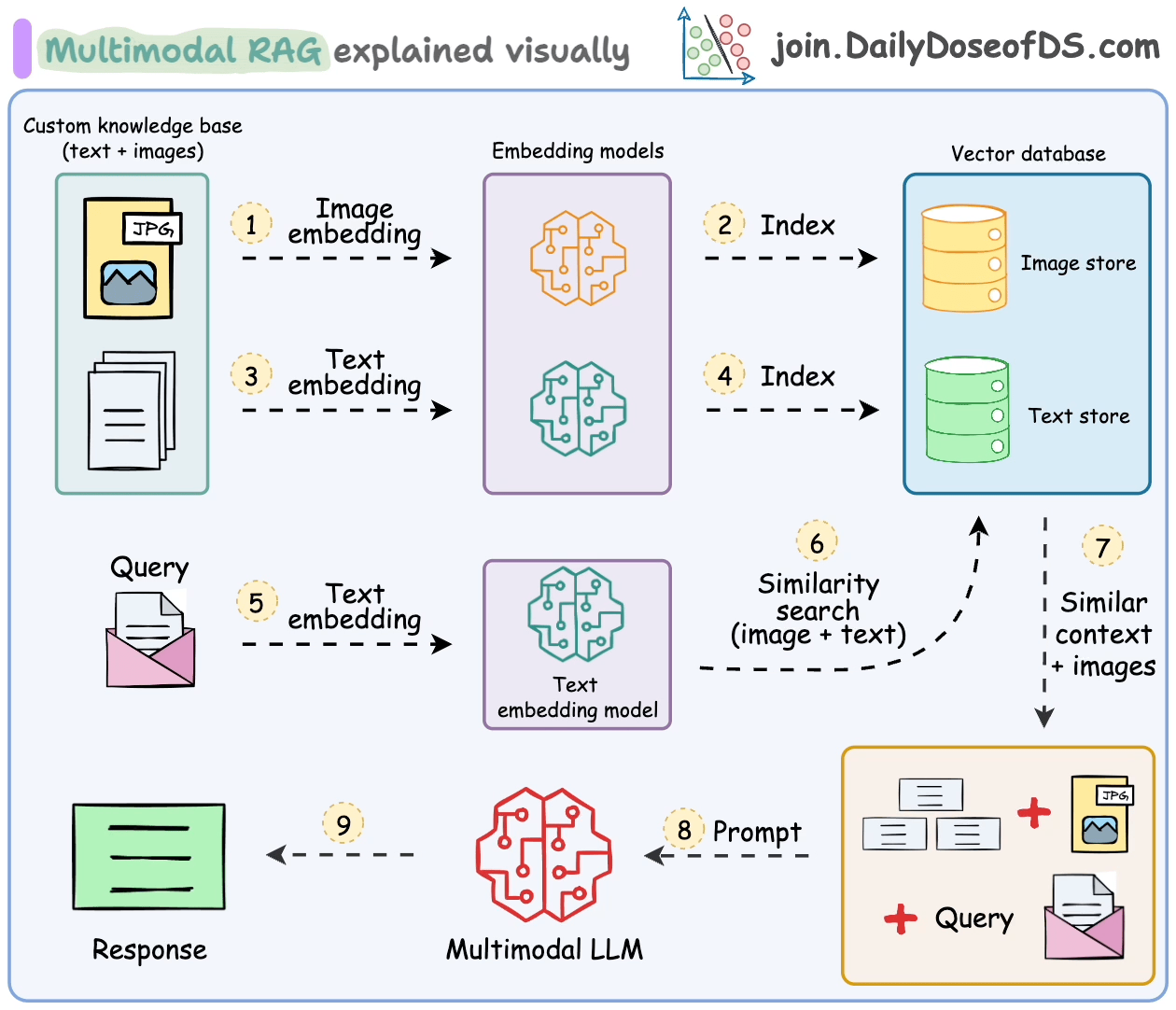
Das Umgang mit solchen multimodalen Daten bringt zusätzliche Herausforderungen bei der Analyse, Einbettung und Abrufung.
Multimodale RAG-Systeme sind so konzipiert, dass sie mehrere Datentypen verarbeiten und RAG über sie ausführen.
Lassen Sie uns einige ihrer wichtigsten Komponenten und wie sie zusammenarbeiten, um dies zu ermöglichen, verstehen.
- Multimodales großes Sprachmodell (LLM):
Im Zentrum des multimodalen RAG steht ein multimodales LLM, das in der Lage ist, sowohl Text als auch Bilder zu verarbeiten.
Dies ermöglicht es dem Assistenten, Anfragen zu verstehen und Antworten auf der Grundlage sowohl visueller als auch textbasierter Informationen zu liefern.
- Text-Einbettungsmodell:
Wir verwenden ein Text-Einbettungsmodell, um textuelle Daten in numerische Vektoren umzuwandeln.
Diese Einbettungen erfassen die semantische Bedeutung des Textes und ermöglichen eine effiziente Abrufung relevanter Dokumente.
- Bild-Einbettungsmodell:
Ähnlich transformiert ein Bild-Einbettungsmodell (z. B. OpenAI CLIP) Bilder in numerische Vektoren.
Dies ermöglicht es dem System, Bilder auf der Grundlage ihres Inhalts zu indizieren und abzurufen und die Lücke zwischen visuellen und textuellen Daten zu schließen.
- Wissensbasis mit Text und Bildern:
Unsere Wissensbasis ist eine Sammlung von Textdokumenten und Bildern.
Diese multimodale Datenbank bildet die Grundlage für den Assistenten, wenn er Antworten generiert.
- Vektor-Speicher mit Unterstützung für multimodale Einbettungen:
Ein Vektor-Speicher, der sowohl Text- als auch Bild-Einbettungen verarbeiten kann, ist entscheidend.
Qdrant ist eine sehr gute Wahl, ich verwende es regelmäßig!
- Prompt-Vorlage:
Wir erstellen eine Prompt-Vorlage, die sowohl textuellen als auch visuellen Kontext einbezieht.
Diese Vorlage leitet das multimodale LLM an, um kohärente Antworten auf der Grundlage der abgerufenen Texte und Bilder zu generieren.
Die Schritte sind auch in der folgenden Abbildung zusammengefasst.
Wir haben kürzlich einen Crash-Kurs zum Aufbau von RAG-Systemen begonnen und haben vier Teile veröffentlicht:
Im ersten Teil haben wir die grundlegenden Komponenten von RAG-Systemen, den typischen RAG-Workflow und den Tool-Stack erkundet und auch die Implementierung gelernt.
Im zweiten Teil haben wir gelernt, wie man RAG-Systeme bewertet (mit Implementierung).
Im dritten Teil haben wir Techniken zum Optimieren von RAG-Systemen und zum Umgang mit Millionen/Milliarden von Vektoren (mit Implementierung) gelernt.
Im vierten Teil haben wir Multimodalität erkundet und Techniken zum Aufbau von RAG-Systemen auf komplexen Dokumenten – solchen, die Bilder, Tabellen und Texte enthalten – (mit Implementierung) gelernt.
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA