- Veröffentlicht am
OpenAi O1: Sehr guter Benchmark
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
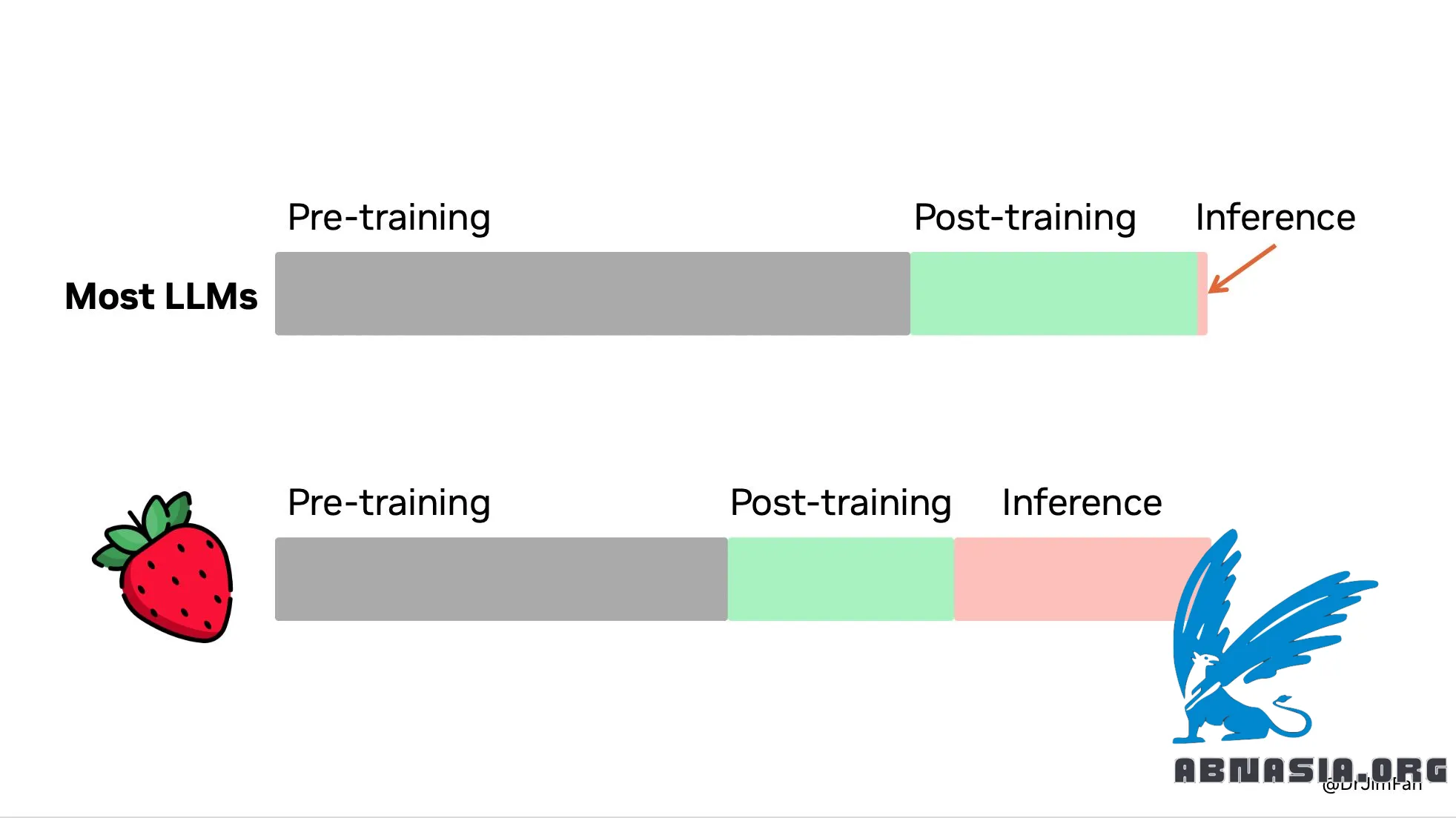
"OpenAI Strawberry (o1) ist da! Endlich wird das Paradigma der Inferenzzeitskalierung populär und in der Produktion eingesetzt. Wie Sutton in der Bitter Lesson sagte, gibt es nur zwei Techniken, die sich unbegrenzt mit der Datenverarbeitung skalieren lassen: Lernen und Suchen. Es ist an der Zeit, den Fokus auf Letzteres zu richten.
Sie benötigen kein riesiges Modell, um Überlegungen anzustellen. Viele Parameter dienen dem Merken von Fakten, um bei Benchmarks wie Trivia-QA gute Leistungen zu erbringen. Es ist möglich, Argumentation aus Wissen herauszurechnen, d. h. einen kleinen „Argumentationskern, der weiß, wie man Tools wie Browser und Code-Verifizierer aufruft. Die Rechenleistung vor dem Training kann verringert werden.
Ein großer Teil der Rechenleistung wird auf die Bereitstellung von Inferenzen verlagert, statt auf das Training vor/nach dem Training. LLMs sind textbasierte Simulatoren. Durch das Ausrollen vieler möglicher Strategien und Szenarien im Simulator wird das Modell schließlich zu guten Lösungen konvergieren. Der Prozess ist ein gut untersuchtes Problem wie die Monte-Carlo-Baumsuche (MCTS) von AlphaGo.
OpenAI muss das Inferenzskalierungsgesetz schon vor langer Zeit herausgefunden haben, was die Wissenschaft gerade erst entdeckt. Letzten Monat erschienen im Abstand von einer Woche zwei Artikel auf Arxiv:
Large Language Monkeys: Skalierung der Inferenzberechnung mit wiederholter Stichprobe. Brown et al. stellt fest, dass DeepSeek-Coder von 15,9 % mit einer Probe auf 56 % mit 250 Proben auf SWE-Bench steigt und damit Sonnet-3.5 übertrifft.
Die optimale Skalierung der LLM-Testzeitberechnungen kann effektiver sein als die Skalierung von Modellparametern. Snell et al. stellt fest, dass PaLM 2-S bei MATH mit Testzeitsuche ein 14-mal größeres Modell übertrifft.
Die Produktion von o1 ist viel schwieriger, als die akademischen Benchmarks zu erreichen. Wie kann man bei Denkproblemen in freier Wildbahn entscheiden, wann man mit der Suche aufhört? Was ist die Belohnungsfunktion? Erfolgskriterium? Wann sollten Tools wie der Code-Interpreter in der Schleife aufgerufen werden? Wie sind die Rechenkosten dieser CPU-Prozesse zu berücksichtigen? Ihr Forschungsbeitrag teilte nicht viel mit.
Strawberry wird leicht zum Datenschwungrad. Wenn die Antwort richtig ist, wird die gesamte Suchspur zu einem Minidatensatz von Trainingsbeispielen, die sowohl positive als auch negative Belohnungen enthalten.
Dies wiederum verbessert den Argumentationskern für zukünftige Versionen von GPT, ähnlich wie sich das Wertschöpfungsnetzwerk von AlphaGo - das zur Bewertung der Qualität jeder Vorstandsposition verwendet wird - verbessert, da MCTS immer verfeinerte Trainingsdaten generiert."
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA