- Veröffentlicht am
Traditionelles RAG vs. HyDE, visuell erklärt.
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Ein kritisches Problem des traditionellen RAG-Systems ist, dass Fragen semantisch nicht ihren Antworten ähneln.
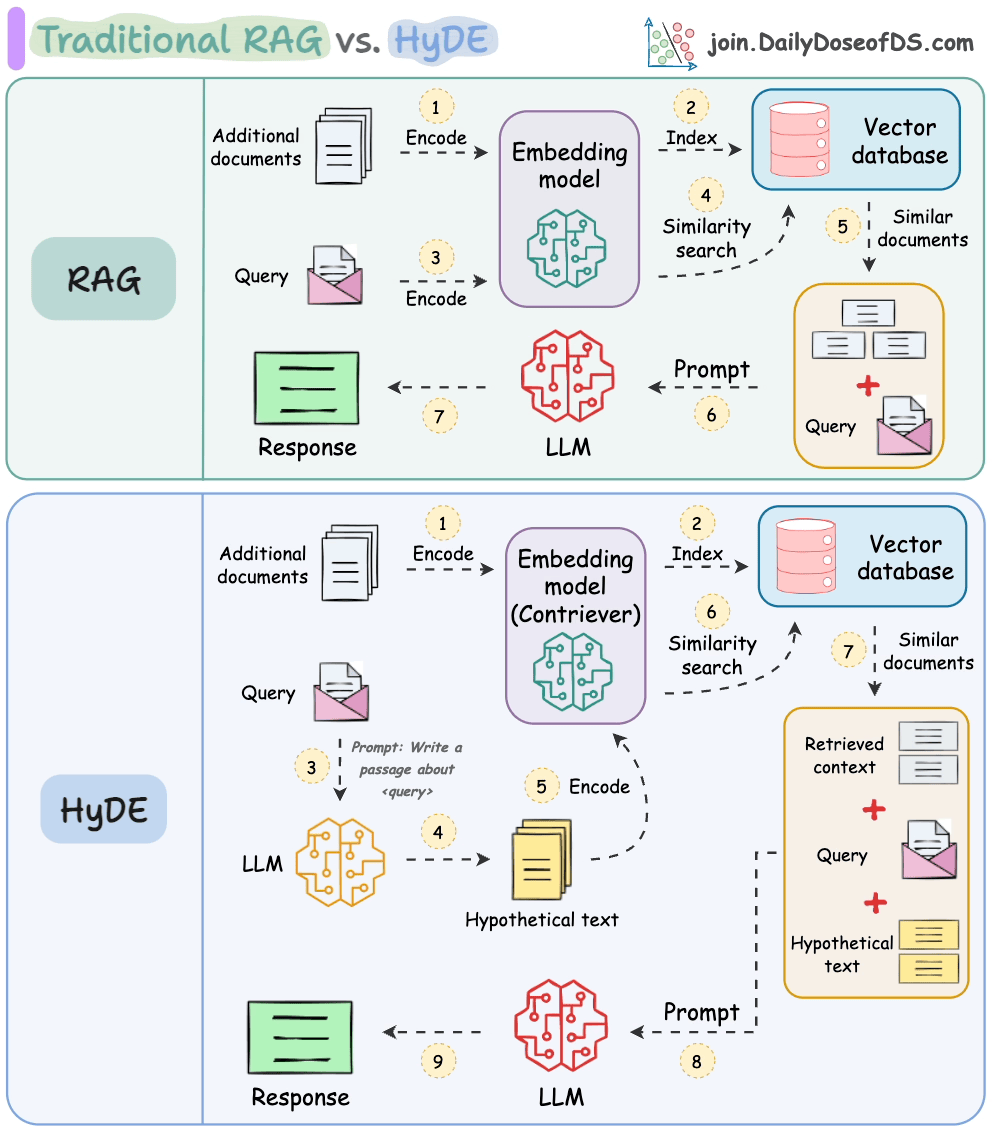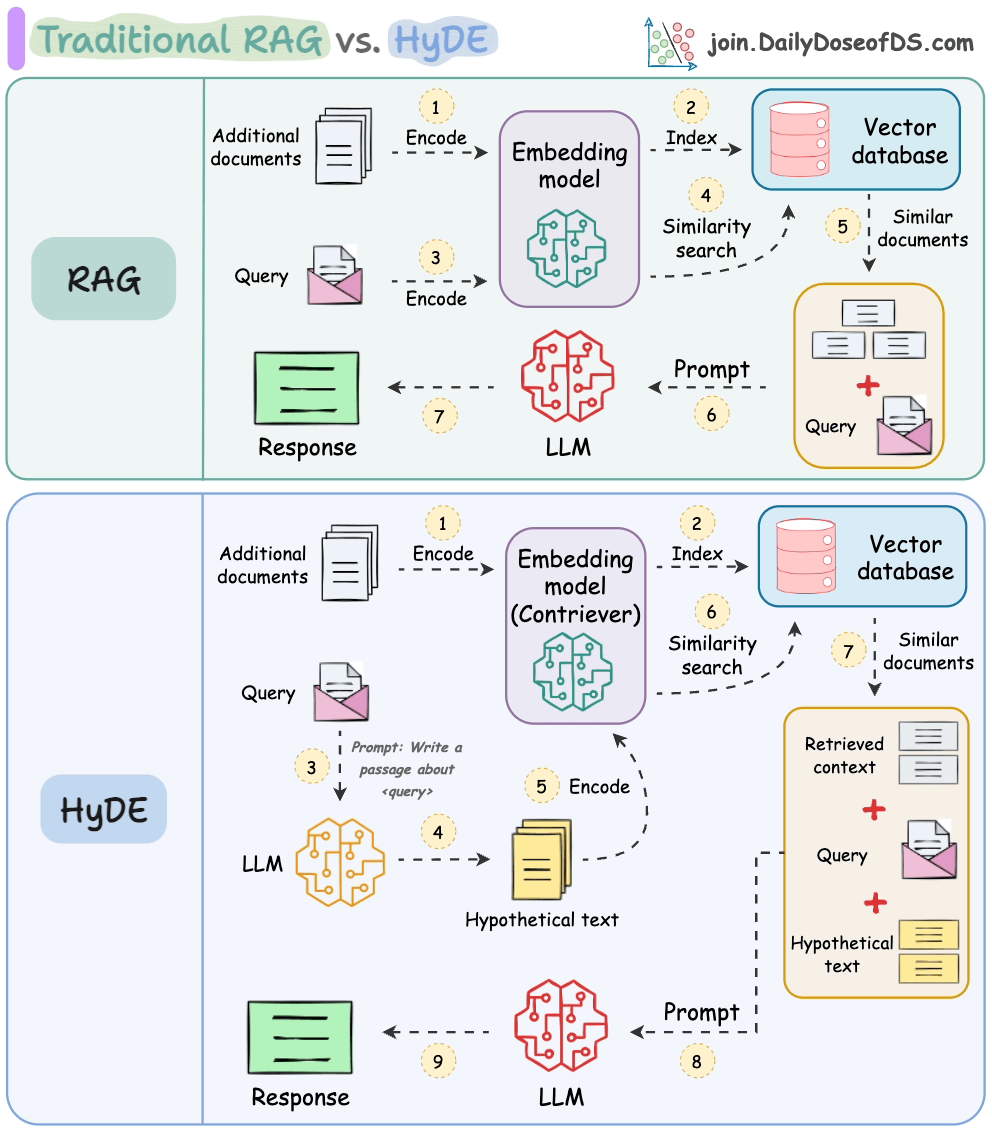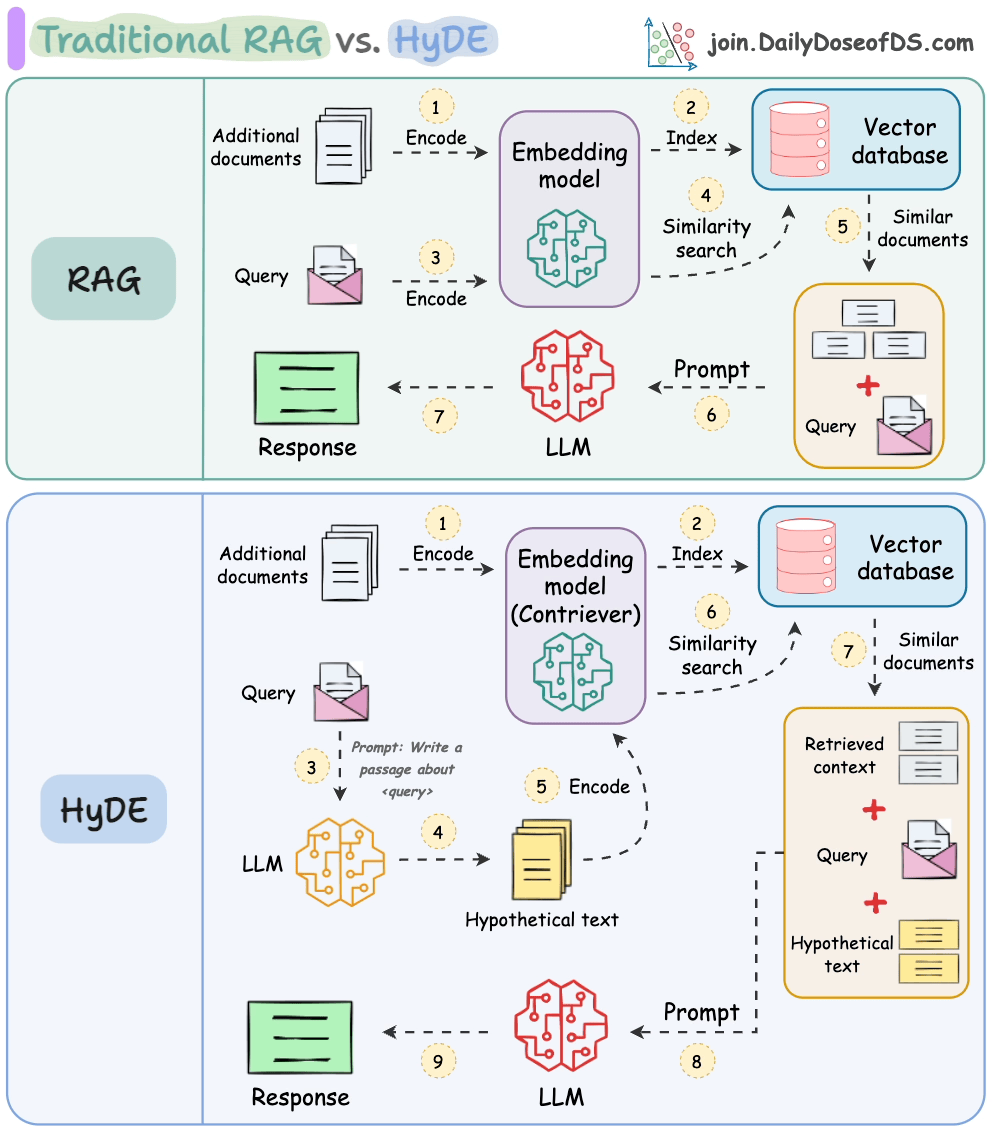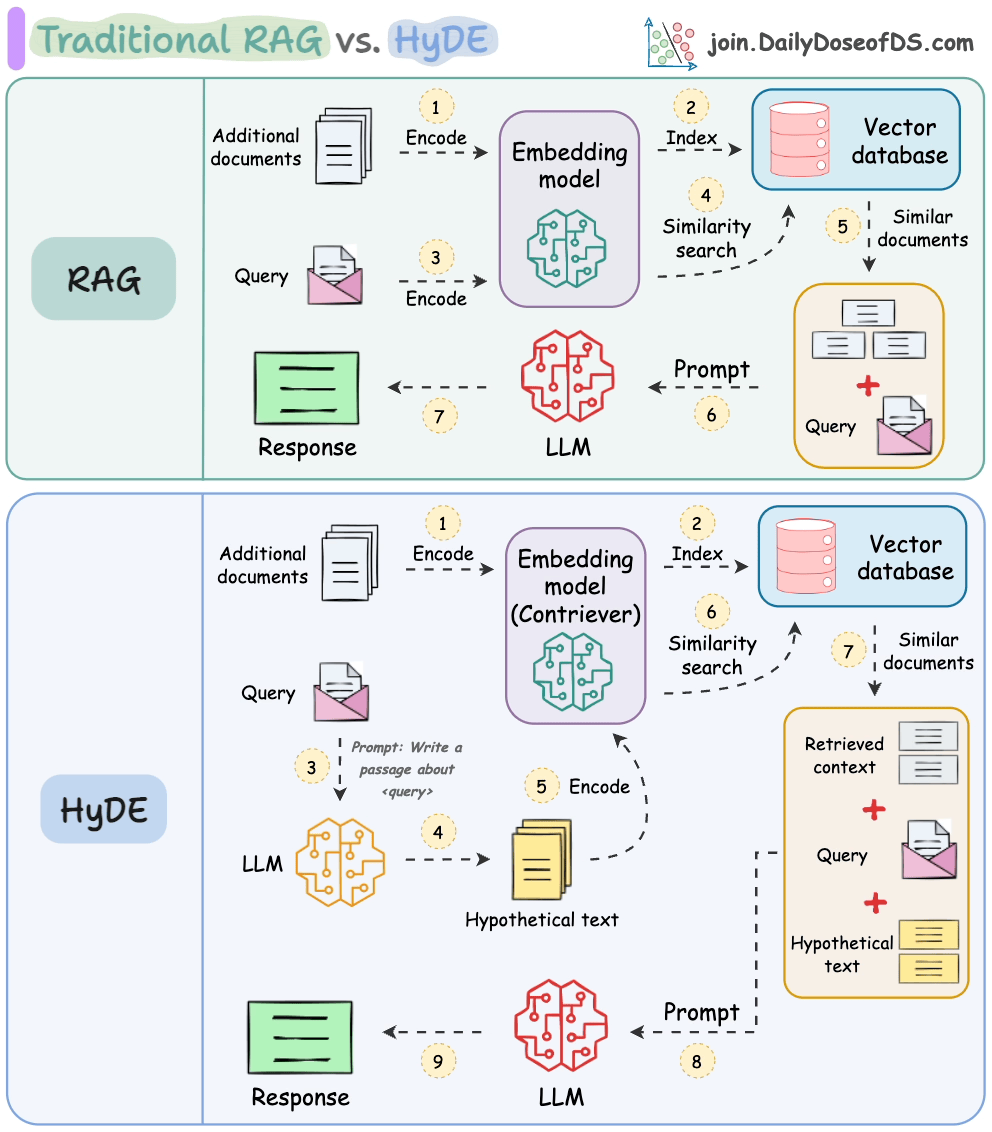
Wenn man nach einem Satz sucht, der dem "Was ist ML?" ähnelt, ist es wahrscheinlich, dass "Was ist KI?" ihm ähnlicher ist als "Maschinelles Lernen macht Spaß."
Aufgrund dieser semantischen Unähnlichkeit werden während des Retrieval-Schritts mehrere irrelevante Kontexte abgerufen.
HyDE löst dieses Problem.
Das folgende Bild zeigt, wie es sich von traditionellem RAG unterscheidet.
So funktioniert es:
Verwenden Sie ein LLM, um eine hypothetische Antwort H für die Abfrage Q zu generieren (diese Antwort muss nicht vollständig korrekt sein).
Betten Sie die Antwort mithilfe eines Contriever-Modells ein, um E zu erhalten (Bi-Encoder, die mit kontrastivem Lernen trainiert wurden, werden hier berühmt eingesetzt).
Verwenden Sie die Einbettung E, um die Vektor-Datenbank abzufragen und relevanten Kontext (C) abzurufen.
Übergeben Sie die hypothetische Antwort H + abgerufenen Kontext C + Abfrage Q an das LLM, um eine Antwort zu erzeugen.
Fertig!
Natürlich wird die generierte hypothetische Antwort wahrscheinlich halluzinierte Details enthalten.
Dies beeinträchtigt die Leistung jedoch nicht schwerwiegend aufgrund des Contriever-Modells - einem, das einbettet.
Genauer gesagt ist dieses Modell mit kontrastivem Lernen trainiert und fungiert auch als nahezu verlustfreier Kompressor, dessen Aufgabe es ist, die halluzinierten Details des gefälschten Dokuments zu filtern.
Dies erzeugt eine Vektor-Einbettung, die erwartungsgemäß ähnlicher zu den Einbettungen der tatsächlichen Dokumente ist als die Frage zu den echten Dokumenten.
Mehrere Studien haben gezeigt, dass HyDE die Abrufleistung im Vergleich zum traditionellen Einbettungsmodell verbessert.
Dies geschieht jedoch auf Kosten erhöhter Latenz und einer stärkeren Nutzung von LLM.
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA