- Veröffentlicht am
Warum reden wir in LLMs immer wieder über Token statt über Worte?
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
"Warum reden wir in LLMs immer wieder von „Tokens statt von Worten? Es ist viel effizienter, die Wörter für die Modellleistung in Unterwörter (Tokens) aufzuteilen!
Die typische Strategie, die in den meisten modernen LLMs seit GPT-1 verwendet wird, ist die Byte Pair Encoding (BPE)-Strategie. Die Idee besteht darin, Unterworteinheiten, die häufig in den Trainingsdaten vorkommen, als Token zu verwenden. Der Algorithmus funktioniert wie folgt:
Wir beginnen mit einer Tokenisierung auf Charakterebene
Wir zählen die Paarfrequenzen
Wir führen das häufigste Paar zusammen
Wir wiederholen den Vorgang, bis das Wörterbuch so groß ist, wie wir es haben möchten
Die Größe des Wörterbuchs wird zu einem Hyperparameter, den wir basierend auf unseren Trainingsdaten anpassen können. Beispielsweise hat GPT-1 eine Wörterbuchgröße von ca. 40 KB, GPT-2, GPT-3 und ChatGPT haben eine Wörterbuchgröße von ca. 50 KB und Llama 3 128 KB."
Bitte beachten Sie, dass die französische Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können. 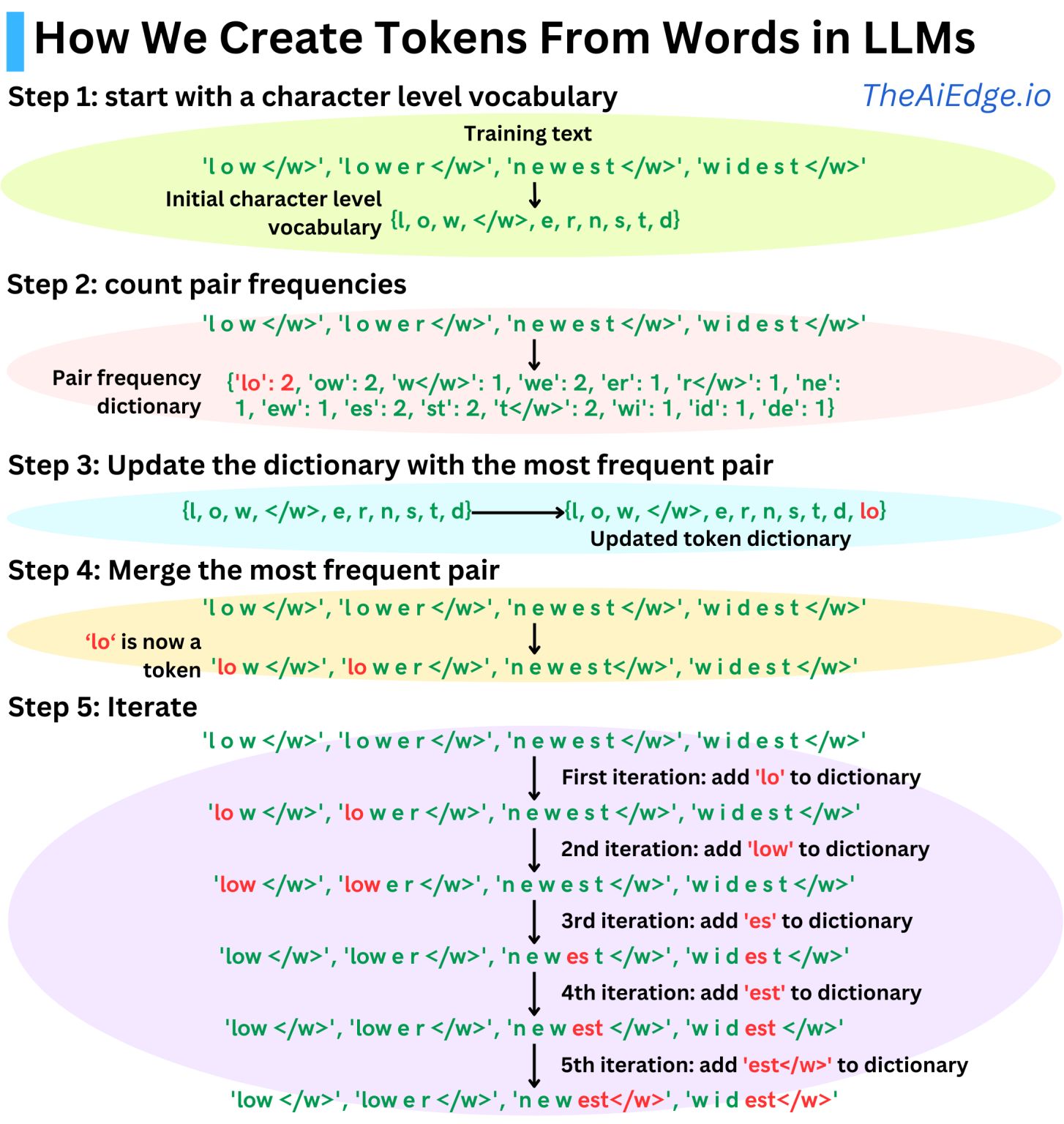
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA