- Veröffentlicht am
Was zählt bei Transformern?
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Was zählt bei Transformers? ist ein interessantes Papier, das herausfindet, dass man tatsächlich die Hälfte der Aufmerksamkeitsebenen in LLMs wie Llama entfernen kann, ohne die Modellierungsleistung merklich zu reduzieren.
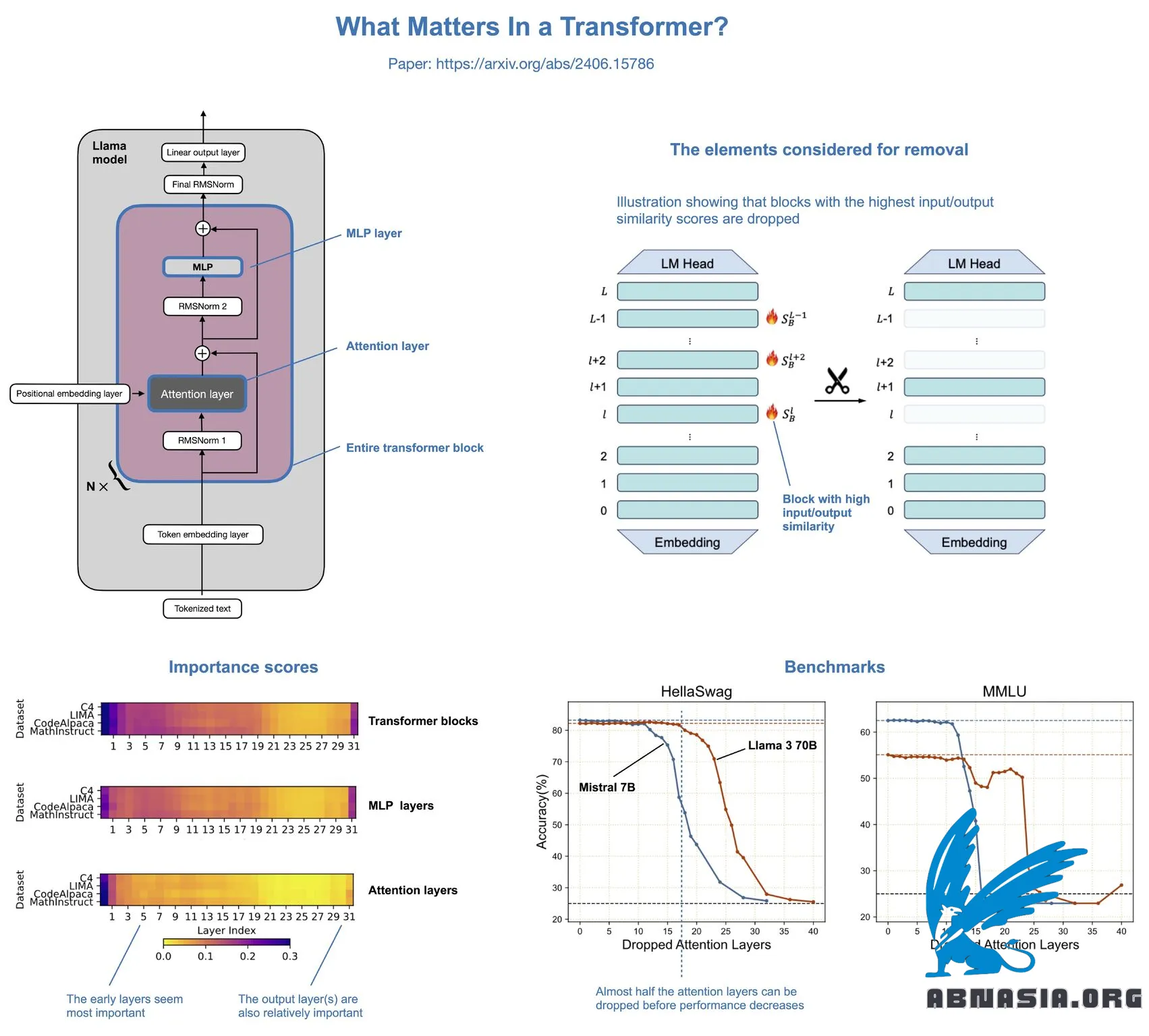
Das Konzept ist relativ einfach. Die Autoren entfernen Aufmerksamkeitsschichten, MLP-Schichten oder ganze Transformer-Blöcke:
Das Entfernen ganzer Transformer-Blöcke führt zu einer erheblichen Leistungsverschlechterung.
Das Entfernen von MLP-Schichten resultiert in einer erheblichen Leistungsverschlechterung.
Das Entfernen von Aufmerksamkeitsschichten verursacht fast keine Leistungsverschlechterung!
Bei Llama 2 70B führt das Entfernen der Hälfte der Aufmerksamkeitsschichten (was zu einer 48-prozentigen Geschwindigkeitssteigerung führt) nur zu einem Rückgang der Modellbenchmarks um 2,4 %. Der Autor hat kürzlich auch Ergebnisse von Llama 3 in den Artikel aufgenommen, die ähnlich sind.
Die Aufmerksamkeitsschichten wurden nicht zufällig entfernt, sondern auf der Grundlage eines kosinusbasierten Ähnlichkeitsscores: Wenn die Eingabe und Ausgabe sehr ähnlich sind, ist die Schicht redundant und kann entfernt werden.
Dies ist ein super faszinierendes Ergebnis und könnte potenziell mit verschiedenen Modellkomprimierungstechniken (wie Pruning und Quantisierung) kombiniert werden, um kumulative Effekte zu erzielen.
Darüber hinaus werden die Schichten in einem einzigen Schritt entfernt (im Gegensatz zu einem iterativen Verfahren) und keine (Neu-)Schulung ist erforderlich, nachdem die Schichten entfernt wurden. Eine (Neu-)Schulung des Modells nach dem Entfernen könnte jedoch potenziell sogar einige der verlorenen Leistung wiederherstellen.
Insgesamt handelt es sich um eine sehr einfache, aber sehr interessante Studie. Es scheint, dass es in größeren Architekturen viel rechnerische Redundanz gibt.
Ein großer Kritikpunkt dieser Studie ist jedoch, dass der Fokus hauptsächlich auf akademischen Benchmarks (HellaSwag, MMLU usw.) liegt. Es ist unklar, wie gut die Modelle auf Benchmarks abschneiden, die die Konversationsleistung messen.
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA