- Veröffentlicht am
Wie funktionieren große Sprachmodelle?
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Das folgende Diagramm veranschaulicht die Kernarchitektur von LLMs.
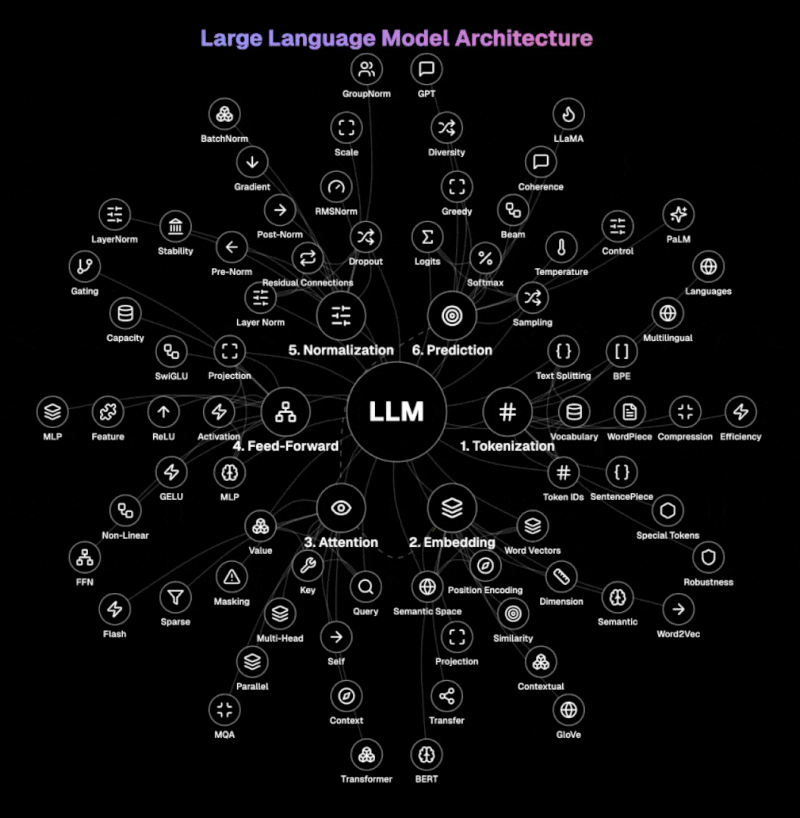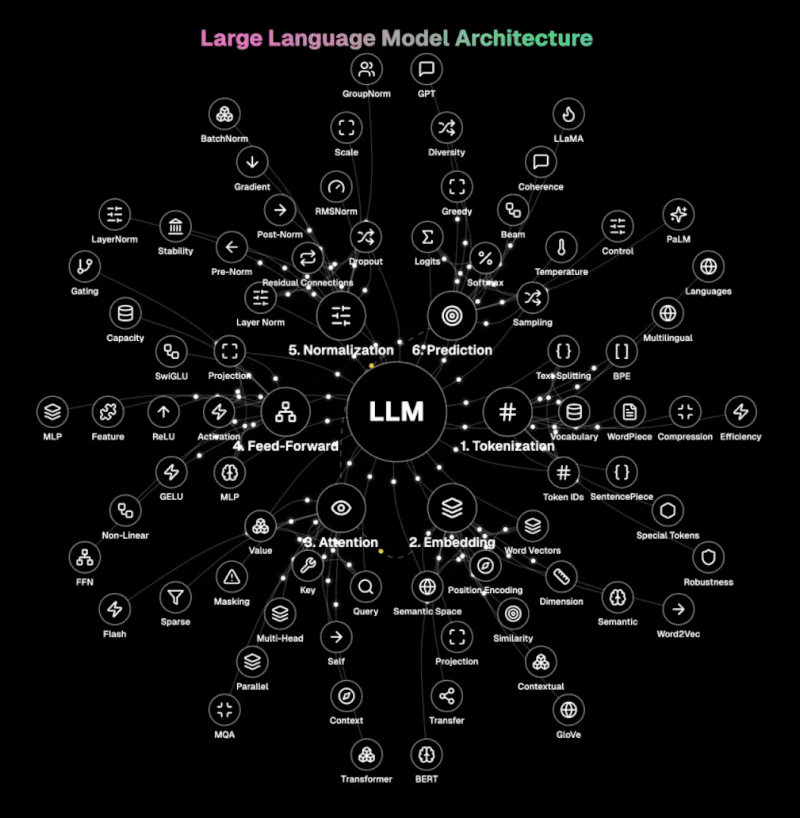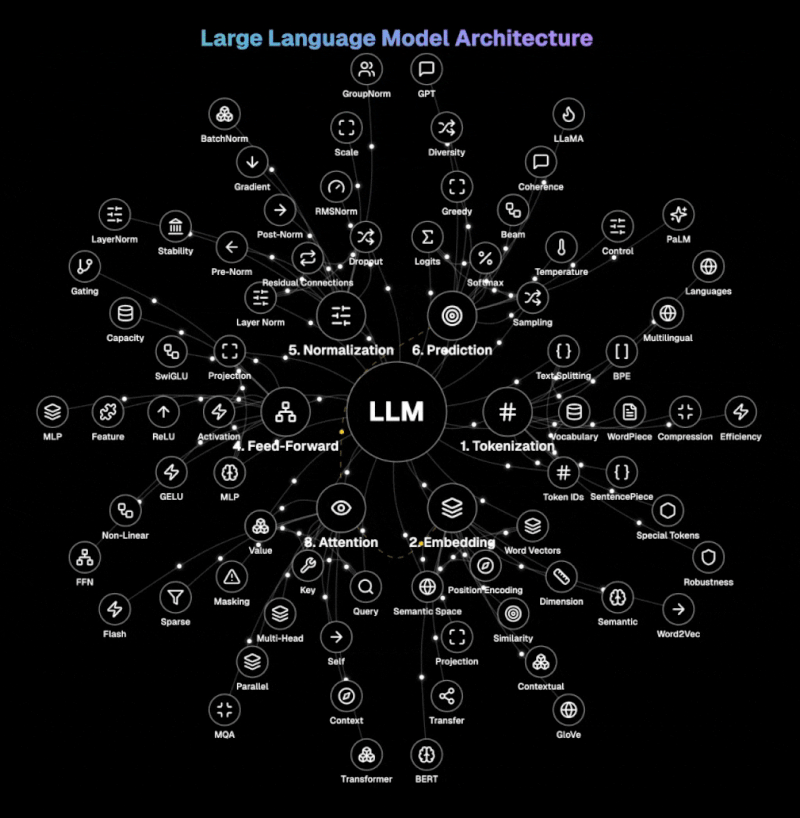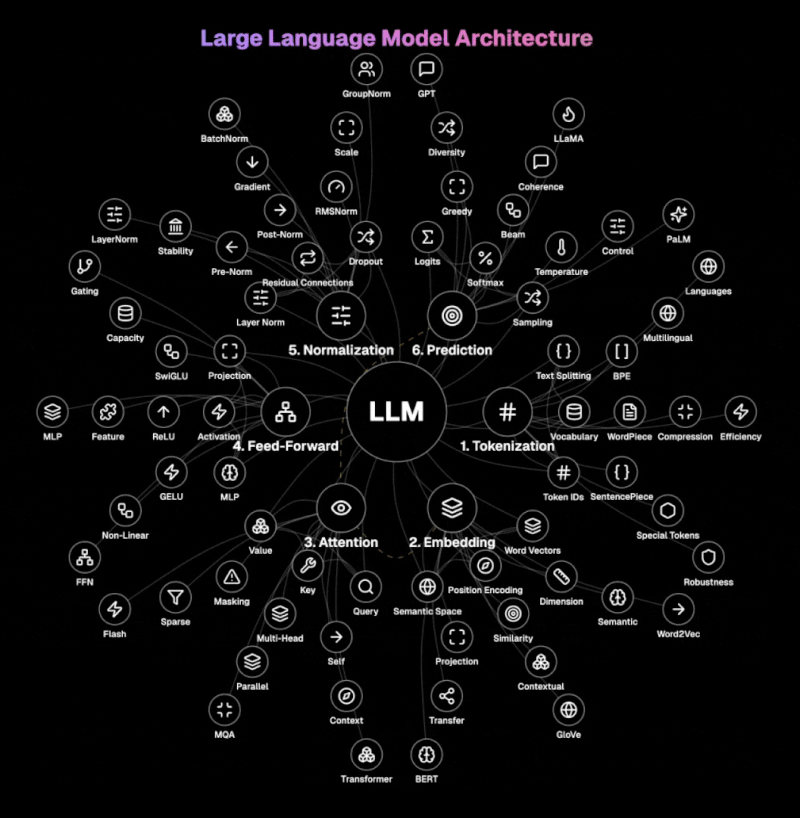
Schritt 1: Tokenisierung Das LLM zerlegt den Text in handhabbare Einheiten, sogenannte Token. Es behandelt Wörter, Subwörter oder Zeichen mithilfe von Techniken wie BPE, WordPiece oder SentencePiece. Dieser Prozess wandelt die natürliche Sprache in Token-IDs um, die das Modell verarbeiten kann, wobei spezielle Token den Anfang, das Ende oder spezielle Funktionen innerhalb des Textes markieren. Die Größe des Vokabulars und die Techniken der Token-Komprimierung sind für eine effiziente Verarbeitung von entscheidender Bedeutung.
Schritt 2: Einbettung Diese Schicht wandelt diskrete Token-IDs in reiche Vektor-Darstellungen in einem hochdimensionalen semantischen Raum um. Sie kombiniert Wortvektoren mit positionalem Encoding, um die Sequenzinformationen zu erhalten. Die Einbettungsmatrix erfasst semantische Beziehungen zwischen Wörtern, wodurch ähnliche Konzepte nahe beieinander im Vektorraum existieren können.
Schritt 3: Aufmerksamkeit Das Herz moderner LLMs, die Aufmerksamkeit bestimmt, welche Teile der Eingabe bei der Generierung jedes Ausgabe-Tokens zu fokussieren sind. Mithilfe von Abfrage-, Schlüssel- und Wertvektoren berechnet sie Relevanzwerte zwischen allen Token in der Sequenz. Die Multi-Head-Aufmerksamkeit verarbeitet Informationen parallel in verschiedenen Repräsentations-Unterräumen, wodurch verschiedene Beziehungen gleichzeitig erfasst werden. Die Selbst-Aufmerksamkeit ermöglicht es dem Modell, den gesamten Kontext zu berücksichtigen, wenn es jedes Token verarbeitet.
Schritt 4: Feed-Forward Diese Komponente wandelt die Darstellung jedes Tokens unabhängig durch ein mehrschichtiges Perzeptron (MLP) um. Sie wendet nicht-lineare Aktivierungsfunktionen wie GELU oder ReLU an, um Komplexität einzuführen, die feine Muster in den Daten erfasst. Das Feed-Forward-Netzwerk erhöht die Fähigkeit des Modells, komplexe Funktionen und Beziehungen darzustellen. Es verarbeitet Token-Darstellungen individuell und ergänzt die kontextuelle Verarbeitung des Aufmerksamkeitsmechanismus.
Schritt 5: Normalisierung Die Layer-Normalisierung standardisiert die Eingaben über die Merkmale hinweg, während residuelle Verbindungen es ermöglichen, dass Informationen direkt durch das Netzwerk fließen. Pre-Norm- und Post-Norm-Architekturen bieten unterschiedliche Stabilitäts-Leistungs-Kompromisse. Dropout verhindert Überanpassung, indem es während des Trainings zufällig Neuronen deaktiviert, wodurch das Modell redundante Darstellungen entwickeln muss.
Schritt 6: Vorhersage Der letzte Schritt wandelt die verarbeiteten Darstellungen in Wahrscheinlichkeiten über das Vokabular um. Er generiert Logits (Rohwerte) für jedes mögliche nächste Token, die mithilfe der Softmax-Funktion in Wahrscheinlichkeiten umgewandelt werden. Die Temperatur-Stichprobe kontrolliert die Zufälligkeit bei der Generierung, wobei niedrigere Temperaturen deterministischere Ausgaben erzeugen. Dekodier-Strategien wie gierig, Strahlensuche oder Nukleus-Stichprobe bestimmen, wie das Modell Token während der Generierung auswählt.
Was LLMs von traditionellen Sprachverarbeitungssystemen unterscheidet, ist ihre autoregressive Natur. Dies erzeugt einen schrittweisen Generierungsprozess anstelle der Erzeugung ganzer Antworten auf einmal.
In Ihrer Meinung: Welche architektonische Komponente verursacht Halluzinationen in LLMs?
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA