- Veröffentlicht am
Wie LLMs Texte generieren?
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Es ist keineswegs eine triviale Aufgabe.
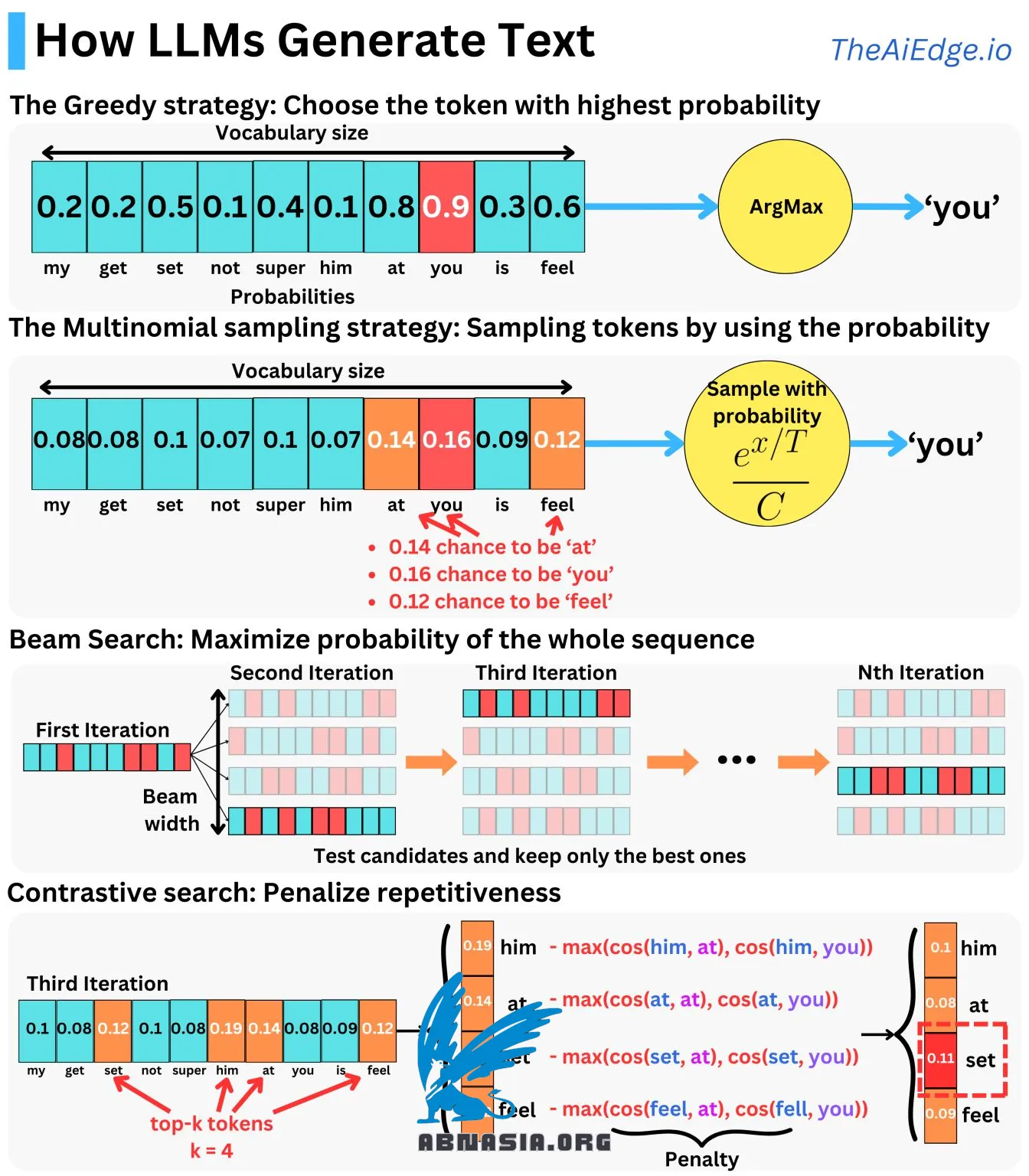
Das Generieren von Texten ist keineswegs eine triviale Aufgabe! LLMs sind optimiert, um die Wahrscheinlichkeit des nächsten Tokens vorherzusagen, aber wie generieren wir mit diesem Wissen Texte?
Der naive Ansatz besteht darin, den von dem Modell generierten Wahrscheinlichkeitsvektor zu verwenden, das Wort mit der höchsten Wahrscheinlichkeit auszuwählen und autoregressiv vorzugehen. Dies ist der gierige Ansatz, aber dieser tendiert dazu, wiederholte Sätze zu generieren, die degenerieren, wenn sie zu lang sind. Ein anderer Ansatz besteht darin, die von dem Modell generierten Wahrscheinlichkeiten zu verwenden und eine Stichprobenerhebung der Wörter basierend auf diesen Wahrscheinlichkeiten durchzuführen. Typischerweise verwenden wir einen Temperaturparameter, um den Zufallsgrad dieses Prozesses anzupassen. Dies ermöglicht es, weniger wiederholte und kreativere Sätze zu generieren.
Aber diese beiden Techniken haben ein Problem. Wenn wir einen Satz generieren, möchten wir die Wahrscheinlichkeit der gesamten Ausgabesequenz maximieren und nicht nur das nächste Token:
P(Ausgabesequenz | Prompt)
Glücklicherweise können wir diese Wahrscheinlichkeit als Produkt der Wahrscheinlichkeiten zur Vorhersage des nächsten Tokens ausdrücken:
P(Token 1, .., Token N | Prompt) = P(Token 1| Prompt) x ... P(Token N | Prompt, Token 1, ..., Token N - 1)
Aber das genaue Lösen dieses Problems ist ein NP-schweres Problem. Stattdessen können wir das Problem approximieren, indem wir bei jedem Schritt k Kandidatentoken auswählen, diese testen und die k Sequenzen beibehalten, die die Wahrscheinlichkeit der gesamten Sequenz maximieren. Am Ende wählen wir einfach die Sequenz mit der höchsten Wahrscheinlichkeit aus. Dies wird als Beam-Search-Generierung bezeichnet und kann mit dem gierigen und dem multinomialen Ansatz kombiniert werden.
Ein weiterer Ansatz ist die kontrastive Suche, bei der wir zusätzliche Metriken wie Flüssigkeit oder Vielfalt berücksichtigen. Bei jedem Schritt wählen wir Kandidatentoken aus, bestrafen die Wahrscheinlichkeiten mit einer Ähnlichkeitsmetrik der zuvor generierten Token und wählen die Token aus, die den neuen Score maximieren.
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA