- Veröffentlicht am
Wie Tinder auf 1,6 Milliarden Swipes pro Tag skalierte
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
"Es war einmal ein Student namens Kenji in Okinawa, Japan.
Kenji; Tinder-Architektur Er zieht für ein höheres Studium nach Australien.
Doch eines Tages trennt sich seine Freundin von ihm.
Deshalb war er traurig.
Er hört von einer Plattform zur Vernetzung von Menschen namens Tinder.
Obwohl er introvertiert ist, beschließt er, es zu versuchen.
Hier ist eine vereinfachte Version der Tinder-Architektur:
Kapitel 1: Die Trennung überwinden Kenji erstellt ein Tinder-Profil und fügt zusätzliche Informationen hinzu.

Sie speichern die Benutzerinformationen in einer Schlüsselwertdatenbank wie Amazon DynamoDB. Und verwenden Sie Dynamo Streams, um Änderungen an einer Tabelle automatisch an verschiedene Stellen zu übertragen.
Außerdem werden die Benutzerinformationen zur Nachrichtenwarteschlange hinzugefügt, um den Standortindex zu aktualisieren. Sie nutzen den Standortindex, um Nutzer in der Nähe effizient zu finden.

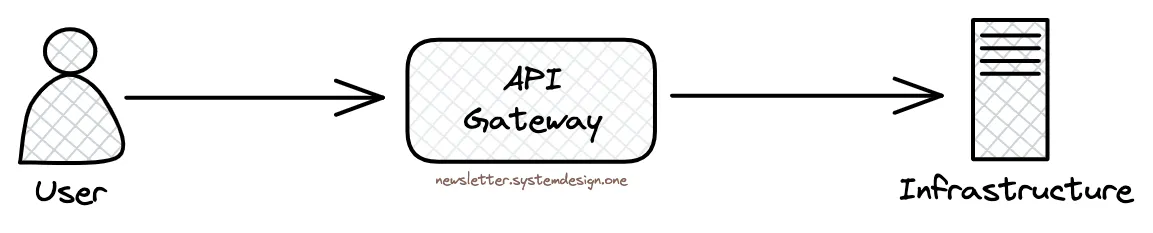
Sie stellen öffentliche APIs über ein API-Gateway bereit. Das bedeutet, dass es als zentraler Einstiegspunkt für Benutzeranfragen an die Infrastruktur fungiert. Und verwaltet Benutzerautorisierungs- und Sicherheitsregeln.
Sie betreiben rund 500 Microservices. Und verwenden Sie Service Mesh, um zwischen den Diensten zu kommunizieren. Stellen Sie sich Service Mesh als eine Netzwerkinfrastruktur zur effizienten Verwaltung der Microservices-Kommunikation vor.
Kapitel 2: Die Dame aus Okinawa Kenji werden Tinder-Profile von Menschen angezeigt, die in der Nähe wohnen.
Es ist schwierig, Personen in der Nähe nur anhand der Breiten- und Längengrade einer Person zu finden.
Außerdem unterteilen sie die Weltkarte nicht in gleichmäßig verteilte Gitter, um das Hot-Shard-Problem zu vermeiden. Denn die Gitter im Ozean werden leer sein. Während Netze in Großstädten viele Nutzer haben werden. Ein Hot Shard ist eine übermäßige Belastung einer einzelnen Partition.
Stattdessen verwenden sie die S2-Bibliothek. S2 ist ein von Google entwickeltes quadratisches hierarchisches Geoindizierungssystem.
Es handelt sich um eine stabile Bibliothek, die viele Programmiersprachen unterstützt. Anders ausgedrückt: Sie verwenden S2, um Personen in Echtzeit zu empfehlen und die Standortdatenbank zu teilen.
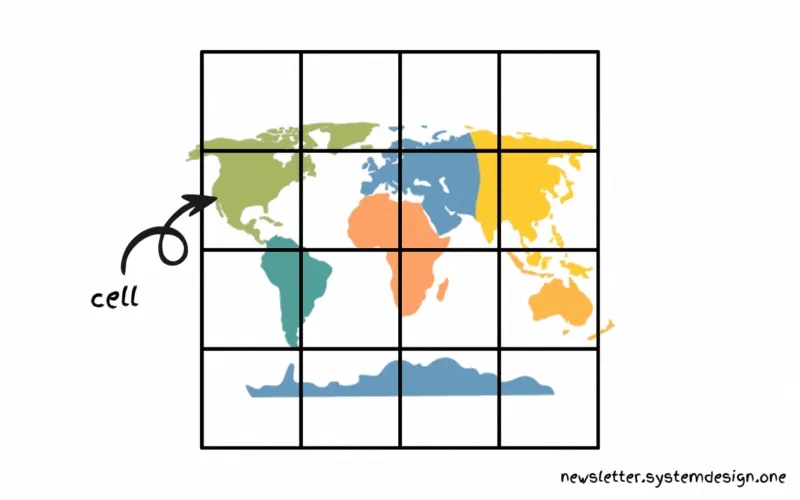
S2 unterteilt die Erdoberfläche in Zellen auf einem flachen Gitter und gibt jeder Zelle eine eindeutige Kennung mit einer 64-Bit-Ganzzahl. Mit anderen Worten: Eine kleine Zelle repräsentiert einen kleinen Bereich der Erde.
Sie speichern die Benutzer physisch näher beieinander im selben Datenbank-Shard. Dadurch wird die Notwendigkeit reduziert, viele Shards abzufragen, um Benutzer in der Nähe zu finden.
Und S2 ist hierarchisch. Das bedeutet, dass die Zellgröße zwischen Quadratzentimetern und Quadratkilometern variiert.
Außerdem unterstützt es die Suche nach einer bestimmten Zelle anhand des Breiten- und Längengrads. Und bietet die Funktionalität, die umgebenden Zellen einer bestimmten Zelle zu finden.
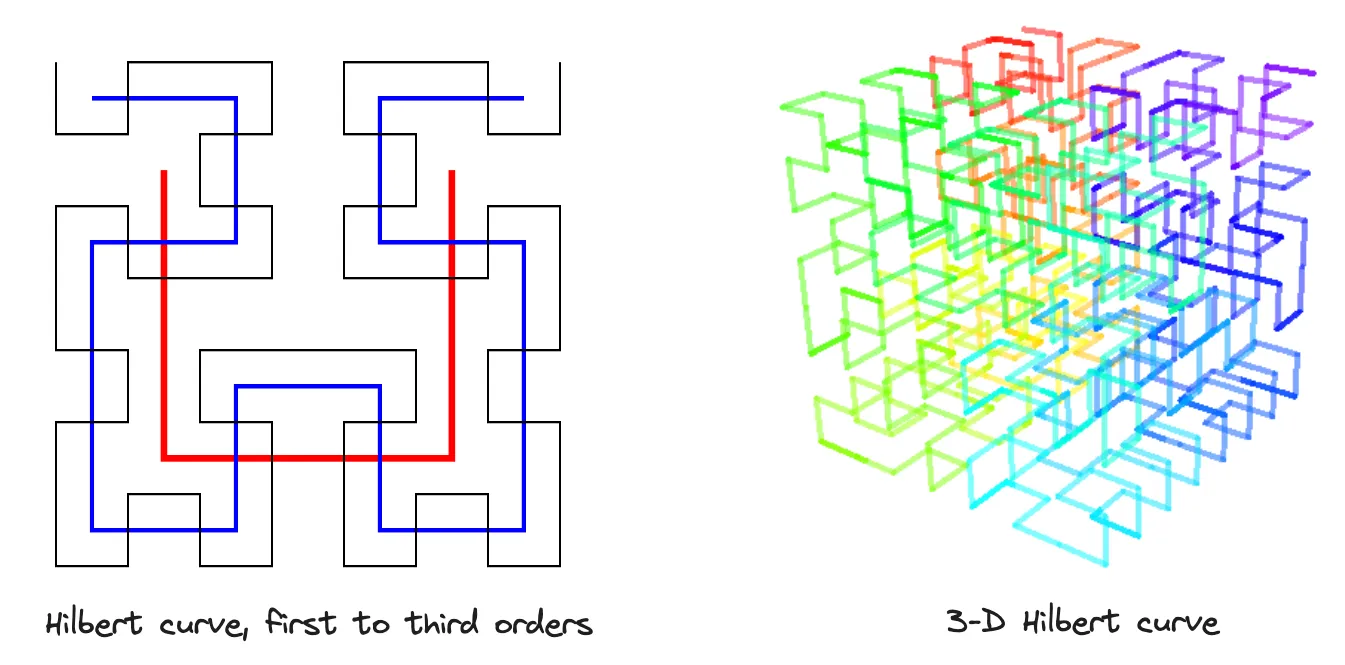
S2 basiert auf der Hilbert-Kurve. Stellen Sie sich die Hilbert-Kurve als eine Linie vor, die jeden Punkt in einem Quadrat durch Falten und Schleifen auf besondere Weise abdeckt. Während zwei Punkte, die in der Hilbert-Kurve nahe beieinander liegen, auch im physischen Raum nahe beieinander liegen. Das bedeutet, dass die räumliche Lokalität erhalten bleibt.
Jede kleine Hilbert-Kurve repräsentiert eine S2-Zelle. Während vier benachbarte Zellen eine größere Zelle bilden und ein Quadtree eine zweidimensionale Hilbert-Kurve darstellt. Ein Quadtree ist eine Baumdatenstruktur, bei der jeder Knoten genau vier untergeordnete Knoten hat.

Sie fragen den Standortindex (S2) ab, um Benutzer in der Nähe zu finden. Es gibt alle Datenbank-Shards in der Nähe eines bestimmten Speicherorts zurück. Anschließend fragen sie alle relevanten Datenbank-Shards parallel ab, um die Liste der Benutzer in diesen Shards zu erhalten.
Im Durchschnitt fragen sie drei Datenbankfragmente ab, um Benutzer in der Nähe in einem Umkreis von 160 km zu finden. Außerdem filtern sie die Ergebnisse basierend auf Benutzerpräferenzen, bevor sie Personen empfehlen.

Kenji trifft sich mit einer Frau aus Okinawa.
Doch es klappte nicht, weil sie kein Interesse an einer Fernbeziehung hatte.
Kapitel 3: Okinawa nach Sydney Kenji dachte, dass es sinnvoller wäre, auf Tinder mit jemandem in Sydney, Australien, zusammenzutreffen.
Also nutzt er Tinders Funktion namens Passport, um seinen Standort zu ändern.

Ändern des Benutzerstandorts
Sie aktualisieren den Index bei Änderungen des Benutzerstandorts. So konnten Personen vom neuen Standort den Benutzer sehen. Mit anderen Worten: Sie fügen den Benutzer zum neuen Standortindex hinzu und entfernen ihn aus dem alten Index.
Da diese Vorgänge jedoch nicht atomar sind, besteht die Gefahr von Fehlern.
Bis Kenji eines Tages das Profil auf den neuen Standort aktualisierte. Und wechselt sofort wieder zum ursprünglichen Standort. Seine Benutzerdaten deuteten jedoch immer noch auf den neuen Standort hin, da die Vorgänge nicht in der gleichen Reihenfolge ausgeführt wurden.
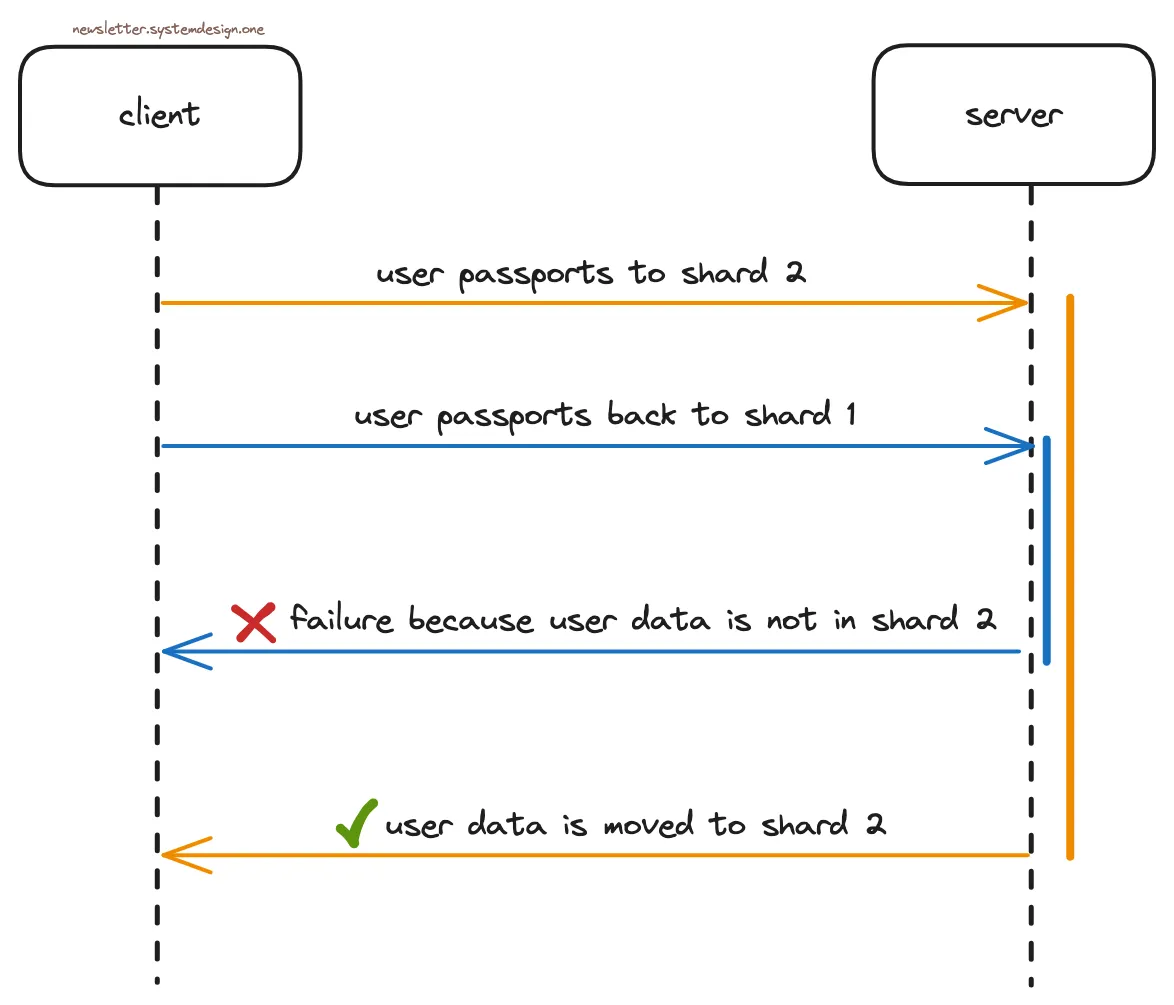 Das Problem ohne garantierte Bestellung
Das Problem ohne garantierte Bestellung
Deshalb verwenden sie Apache Kafka, um dieses Problem zu lösen. Stellen Sie sich Kafka als eine verteilte Streaming-Plattform für die Datenverarbeitung in großem Maßstab vor.
Sie haben dieselben Benutzerdaten an dieselben Kafka-Partitionen gesendet. Während Kafka-Konsumenten Sperren für die Partitionen erwerben, um Konflikte zu vermeiden. Dadurch wird eine FIFO-Warteschlangenimplementierung mit Bestellgarantien und sehr hohem Durchsatz bereitgestellt.
Außerdem überprüfen sie Kafka, damit die Verarbeitung nach einem Prozessabsturz wieder aufgenommen werden kann.
Kapitel 4: Zoe und Kenji Kenji wischte weiter auf Tinder.
Und die Tage vergingen.
 Passende Benutzer
Passende Benutzer
Sie senden Swipes an einen Datenstrom wie Amazon Kinesis. Und führen Sie Match-Worker aus, um den Datenstrom zu lesen und zu prüfen, ob es eine Übereinstimmung aus dem Likes-Cache gibt.
Während der Likes-Cache die Informationen über Personen speichert, die einem Benutzer gefallen haben.
 Benutzer über eine Übereinstimmung benachrichtigen
Benutzer über eine Übereinstimmung benachrichtigen
Sie verwenden WebSockets, um Benutzer zu benachrichtigen, wenn eine Übereinstimmung vorliegt. So entsteht ein Echtzeit-Erlebnis. WebSockets ist ein bidirektionales Echtzeit-Kommunikationsprotokoll.
 Speichern von Profilen, die einem Benutzer nicht gefallen
Speichern von Profilen, die einem Benutzer nicht gefallen
Sie legen die unerwünschten Profile einer Person in einem Datenspeicher wie Amazon S3 ab. Und nutzen Sie diese Informationen für die Datenanalyse, um Benutzerempfehlungen zu verbessern.
 Bis eines Tages. Kenji passte zu Zoe.
Bis eines Tages. Kenji passte zu Zoe.
Eine Dame aus Sydney.
Kapitel 5: Probleme sind Richtlinien Sie berechnen die eindeutige Anzahl von Benutzern, um die Auslastung eines Shards zu ermitteln. Und Benutzer innerhalb eines Shards befinden sich normalerweise in derselben Zeitzone.
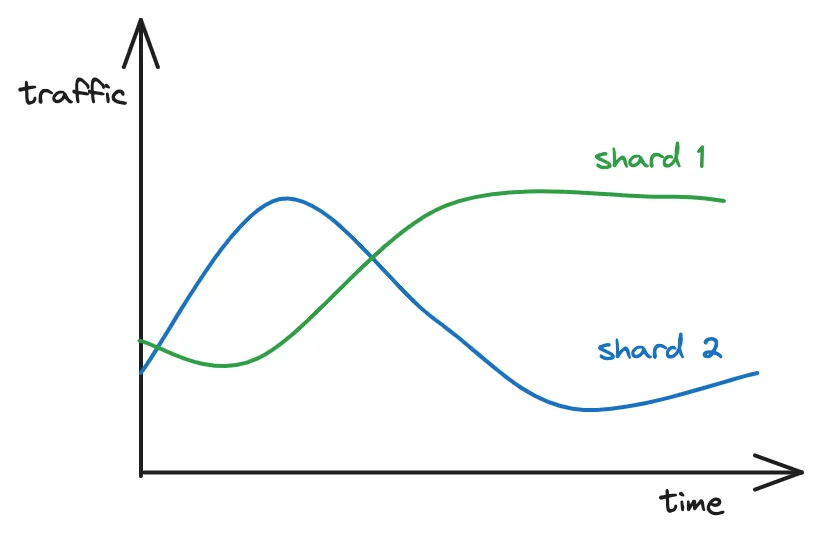 Das Verkehrsmuster zweier verschiedener Shards
Das Verkehrsmuster zweier verschiedener Shards
Aufgrund von Zeitzonenunterschieden wird wahrscheinlich ein Hot-Shard-Problem auftreten. Das bedeutet, dass der Spitzenverkehr aufgrund von Zeitunterschieden je nach Standort unterschiedlich sein wird. Und es kommt zu unausgeglichenem Datenverkehr über Shards hinweg.
Doch ein einzelner Shard in einem physischen Server würde es noch schlimmer machen. Daher weisen sie nach dem Zufallsprinzip viele Shards demselben physischen Server zu, um das Hot-Shard-Problem zu verhindern.
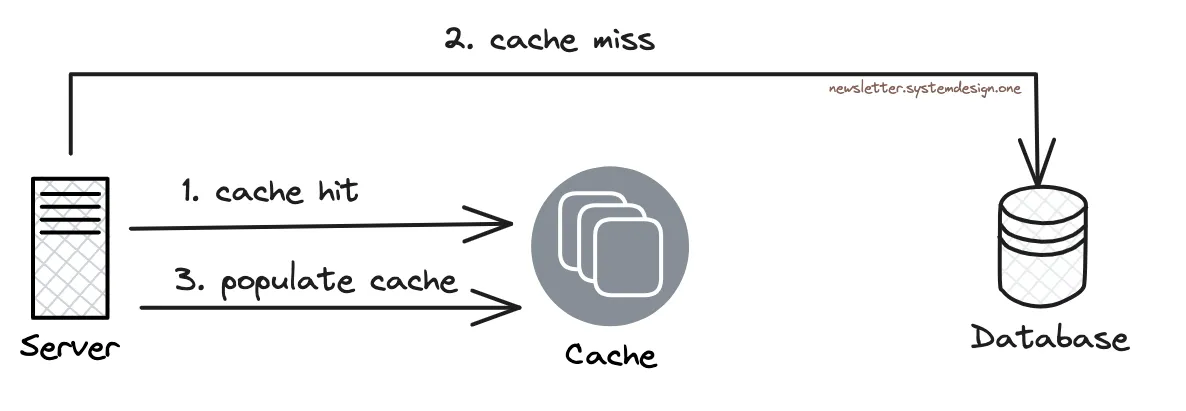 Caching zur Vermeidung von Hot-Shard-Problemen
Caching zur Vermeidung von Hot-Shard-Problemen
Auch die meisten Datenoperationen bei Tinder sind Leseoperationen. Daher verwenden sie den Redis-Cache zur Skalierung.
Sie verwenden das Cache-Aside-Muster. Mit anderen Worten: Sie überprüfen den Cache auf Daten. Und wenn es nicht vorhanden ist, greifen sie auf die Datenbank zurück. Auch der Cache wird mit den Daten aktualisiert.
Die Cache-Schicht löst also das Problem des Lesens von Hot Shards. Während sie eine Ratenbegrenzung durchführen, um das Problem des Schreibens von Hot Shards zu lösen.
Außerdem führen sie bei einem Fehler einen exponentiellen Backoff mit Jitter durch. Und führen Sie regelmäßig einen Hintergrundjob aus, um die Datenspeicher zu synchronisieren.
Tinder bleibt eine der größten Dating-Plattformen. Und wickeln täglich rund 26 Millionen Spiele ab.
 Während Kenji und Zoe glücklich bis ans Ende ihrer Tage lebten.
Während Kenji und Zoe glücklich bis ans Ende ihrer Tage lebten.
"
Bitte beachten Sie, dass die französische Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können. 
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA