- Published on
Data Pipeline Overview
- Authors

- Name
- AbnAsia.org
- @steven_n_t
What a Modern Data Pipeline Looks Like
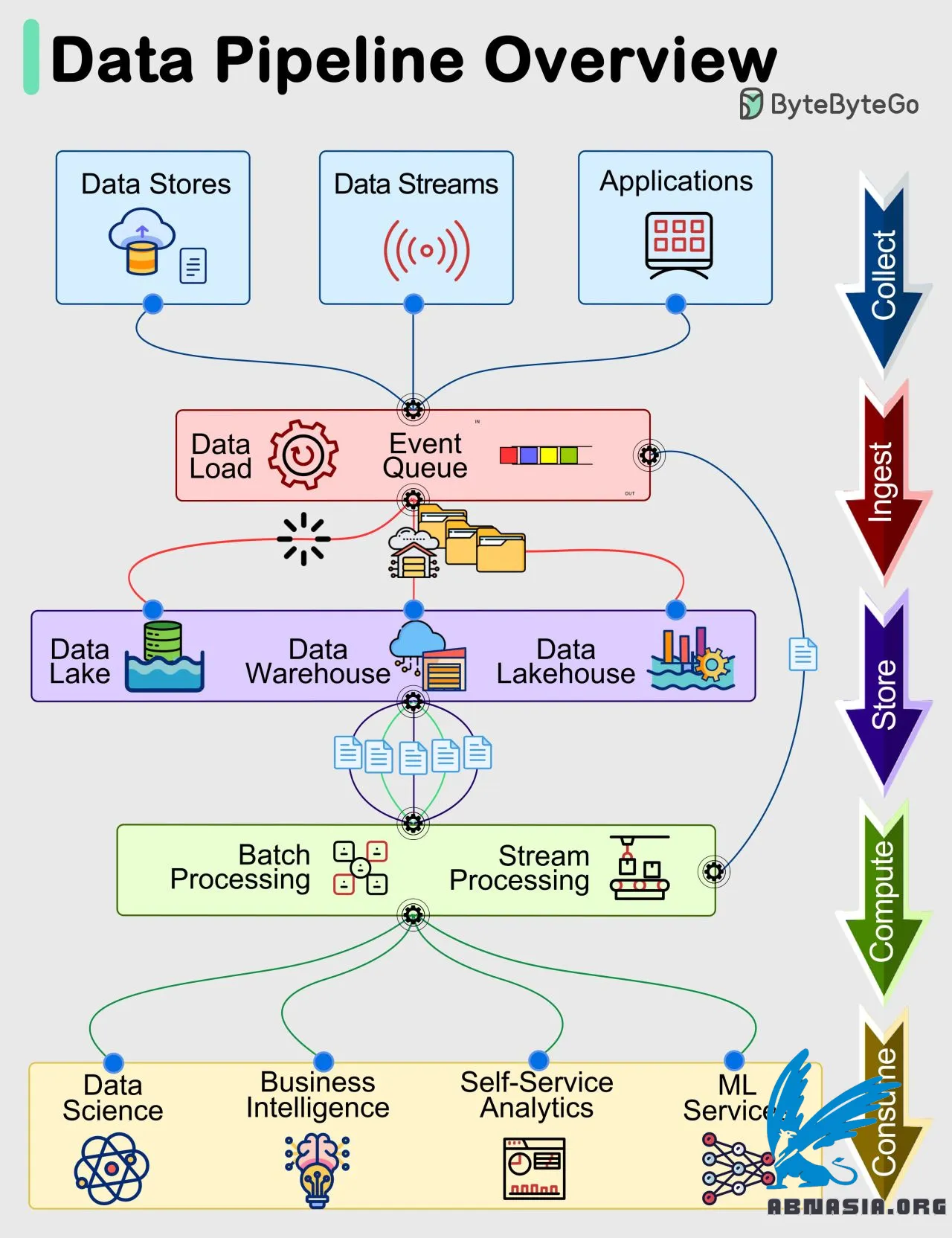
A data pipeline typically has 5 stages:
- Collect:
Data is acquired from data stores, data streams, and applications.
- Ingest:
During ingestion, data is loaded into systems and organized within event queues.
- Store:
Post ingestion, organized data is stored in data warehouses, data lakes, and data lakehouses. It is also stored in databases and other systems.
- Compute:
Data undergoes aggregation, cleansing, and manipulation to conform to company standards. This includes format conversion, data compression, and partitioning. Both batch and stream processing are used, with stream processing also tapping into the ingestion phase directly for efficiency for many workloads.
- Consume:
Processed data is made available for consumption through analytics, visualization, operational data stores, decision engines, user-facing applications, dashboards, data science, machine learning, business intelligence, and self-service analytics.
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA