- Published on
How does Notion handle 200 billion data entities?
- Authors

- Name
- AbnAsia.org
- @steven_n_t
Everything in Notion is a block—text, images, lists, database rows, and even pages.
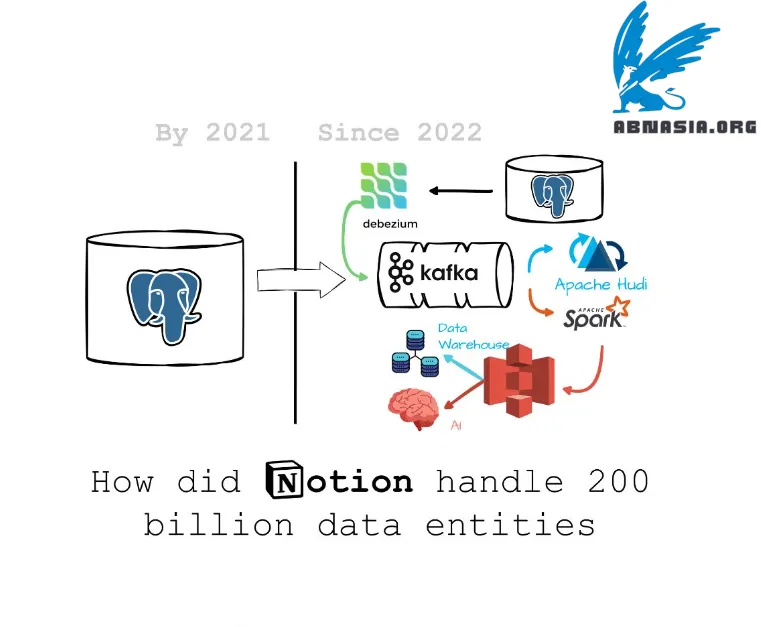
Notion's architecture is designed to support its unique data model, which revolves around "blocks"—the fundamental units of information that can represent various types of content, such as text, images, and database entries. This architecture allows for a flexible and dynamic user experience, enabling users to create and manipulate data in a highly customizable manner.
Key Features of Notion's Architecture
- Block-Based Data Model
Everything is a Block: In Notion, all content is treated as a block. Blocks are Notion's LEGOs. This includes text, images, database rows, and even entire pages. Each block has associated metadata and can be transformed or moved freely within the application67.
Flexibility: This block model allows users to organize information without strict constraints, making it easier to adapt to various use cases and workflows6.
- Database Design
Relational Database: Notion utilizes PostgreSQL as its underlying database system. Initially, it operated on a single PostgreSQL instance but has since evolved to a more complex architecture involving sharding to manage growing data loads effectively
Sharding Strategy: As of mid-2023, Notion's database architecture consists of 96 database servers partitioned into logical shards based on workspace IDs. This ensures that all blocks belonging to a specific workspace are stored together, facilitating efficient transactions and consistency1
- Scalability and Performance
Clustered Architecture: The use of clustered servers allows Notion to scale its database horizontally. Each shard is represented as a PostgreSQL schema, which helps in managing the increasing data volume while maintaining performance
API Interaction: Client applications interact with the database through a dedicated API server operating on Node.js web servers. This setup enhances performance by managing connections efficiently through connection pooling
- Data Management and Growth
Data Lake Infrastructure: Notion has implemented an ELT (Extract, Load, Transform) pipeline for data analytics and reporting purposes, utilizing tools like - Fivetran to ingest data from PostgreSQL into Snowflake for further analysis3.
- Rapid Data Growth: The volume of block data in Notion has expanded significantly—growing from over 20 billion blocks at the start of 2021 to more than 200 billion blocks by mid-2024. This growth necessitates continuous optimization of their data management strategies37.
Designing Databases in Notion
Creating databases in Notion is straightforward and involves several steps:
Create a Database Block: Users can initiate a database by typing /database in any Notion page to access various database types (inline or full-page).
Add Columns and Entries: Users can define properties for each entry in the database, including types like text, numbers, dates, etc.24.
Customize Views: Notion supports multiple views (table, board, gallery) for visualizing data according to user preferences49. Linking Databases: Users can create relationships between different databases using linked properties, enhancing the interconnectivity of their data4.
Notion's architecture combines a flexible block-based model with robust relational database management principles to create a powerful tool for organizing information. Its scalable infrastructure and user-friendly design enable users to manage complex datasets effectively while providing the necessary tools for customization and collaboration. This unique blend makes Notion suitable for both personal productivity and team collaboration scenarios.
Initially, Notion stored all the blocks in the Postgres database.
At that time, Postgres databases handle everything from online user traffic to offline analytics and machine learning.
In 2021, they started the journey with a simple ETL that used Fivetran to ingest data from Postgres to Snowflake, using 480 connectors to write 480 shards to raw Snowflake tables hourly.
But this approach had some problems when the Postgres data grew:
❌Managing 480 Fivetran connectors is a nightmare.
❌Notions users update blocks more often than add new ones. This heavy-updated pattern slows and increases the cost of Snowflake data ingestion.
❌The data consumption gets more complex and heavy (AI workloads)
In 2022, they onboarded an in-house data lake architecture that incrementally ingested data from Postgres to Kafka using Debezium, then used Apache Hudi to write from Kafka to S3.
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA