- Published on
Speed Up LLM Inference with Speculative Decoding
- Authors

- Name
- AbnAsia.org
- @steven_n_t
Remember MSN Messenger?
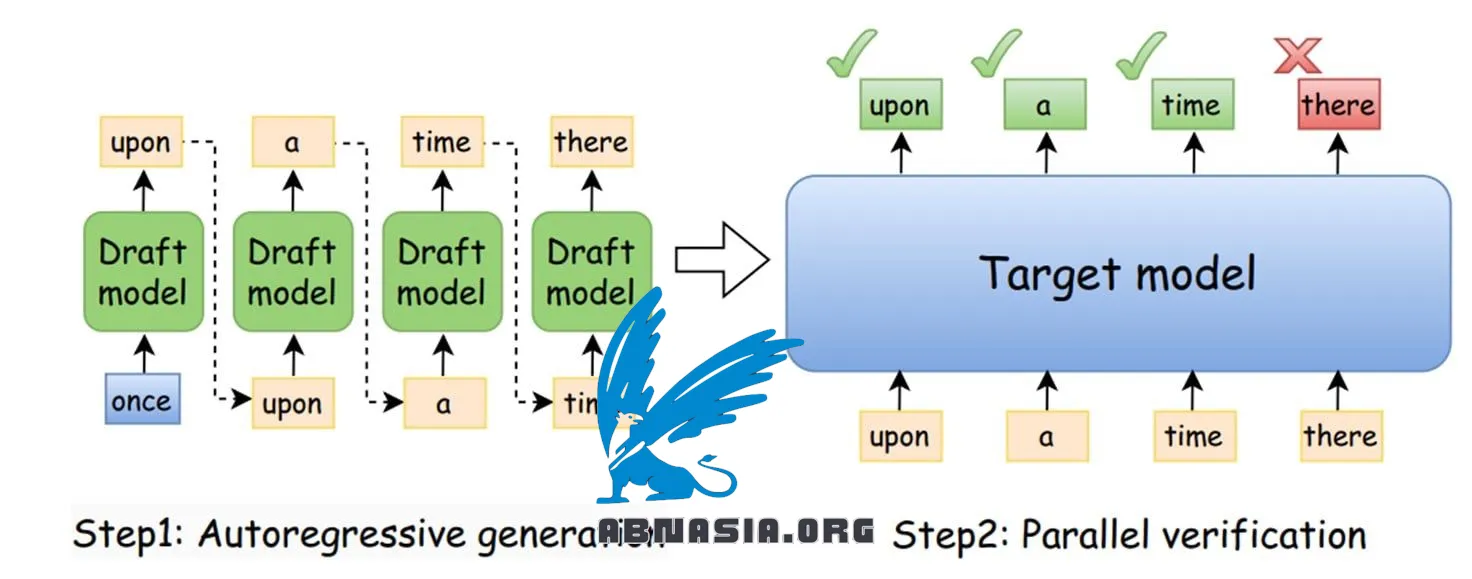
What is Speculative Decoding?
It’s a technique that uses a draft model (SLM) to work alongside the main LLM:
1️⃣ The draft model predicts the next K tokens.
2️⃣ The main LLM verifies and corrects them as needed.
3️⃣ If there’s a mismatch, the LLM continues the sequence, and the draft model restarts with updated input.
Why It Works:
• Up to 3x faster for code completion.
• Up to 2x faster for summarization, text generation, and instructions.
Pretrained Draft Models:
• Llama-3.1-8B-FastDraft-150M
• Phi-3-mini-FastDraft-50M
Why It Matters:
It makes LLMs faster, more efficient, and ready for real-world tasks.
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA