- Published on
What is Retrieval-Augmented Generation (RAG)?
- Authors

- Name
- AbnAsia.org
- @steven_n_t
RAG is the process of optimizing an LLM's output to reference a specific knowledge base that may not have been part of its training data before generating a response.
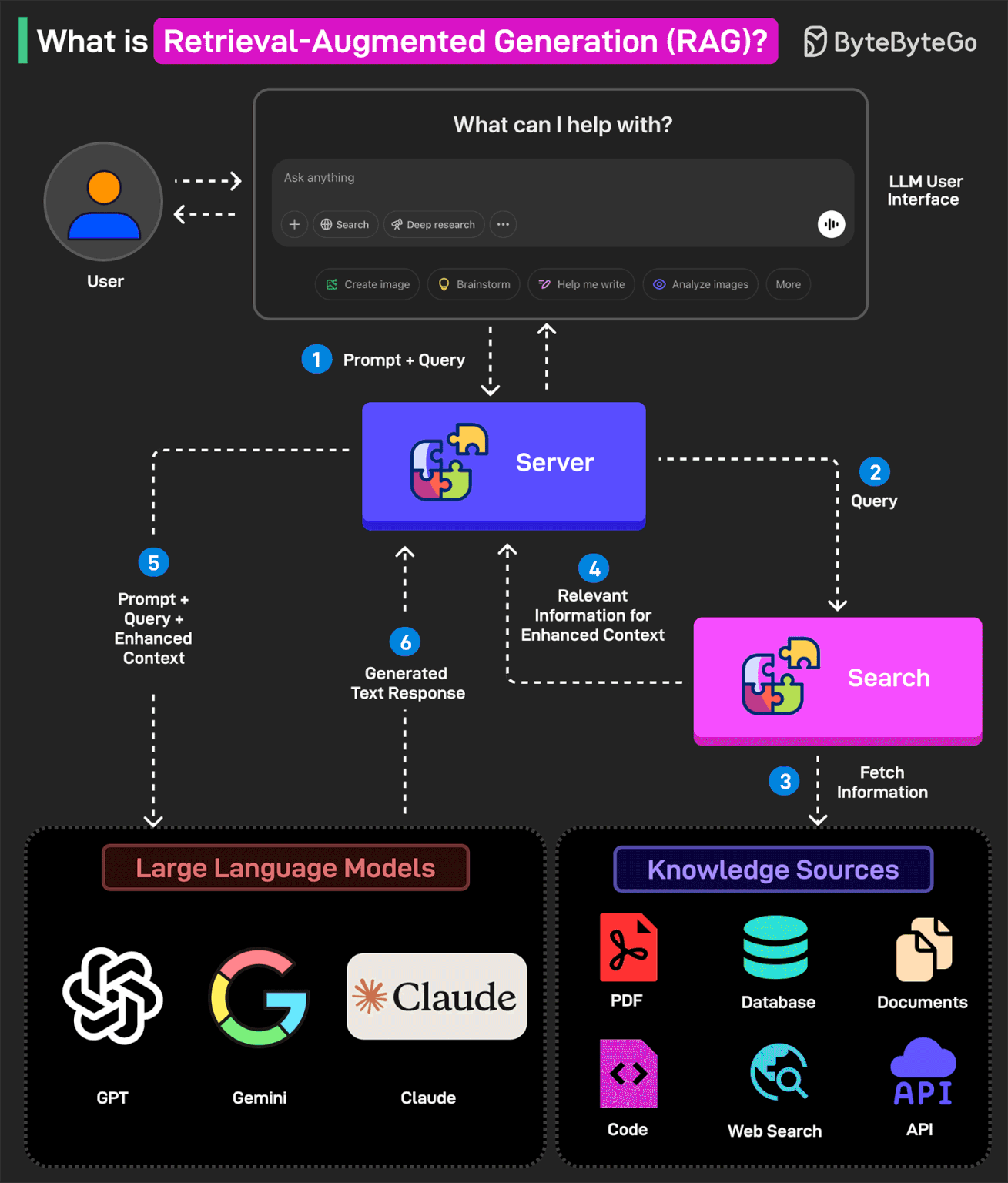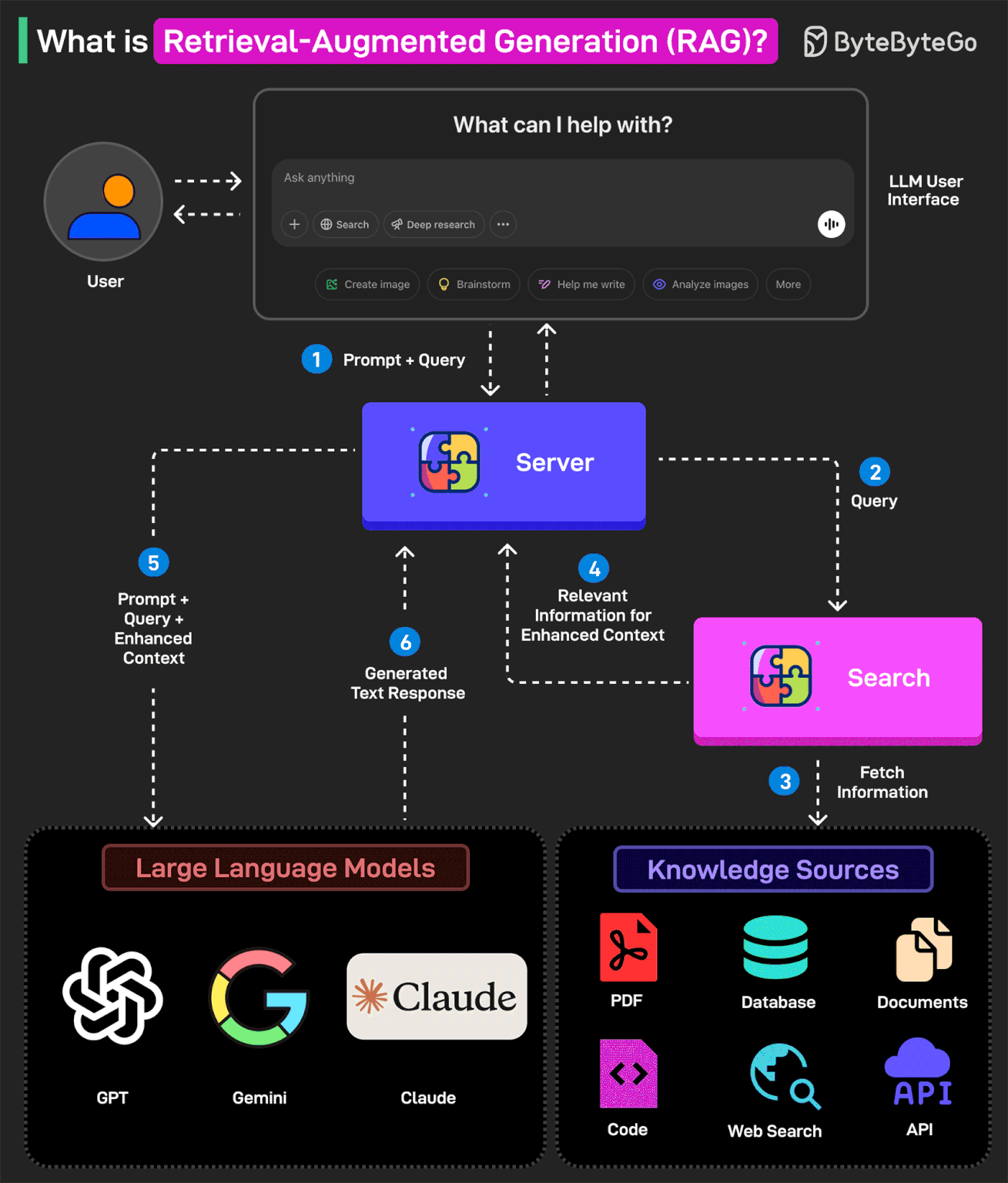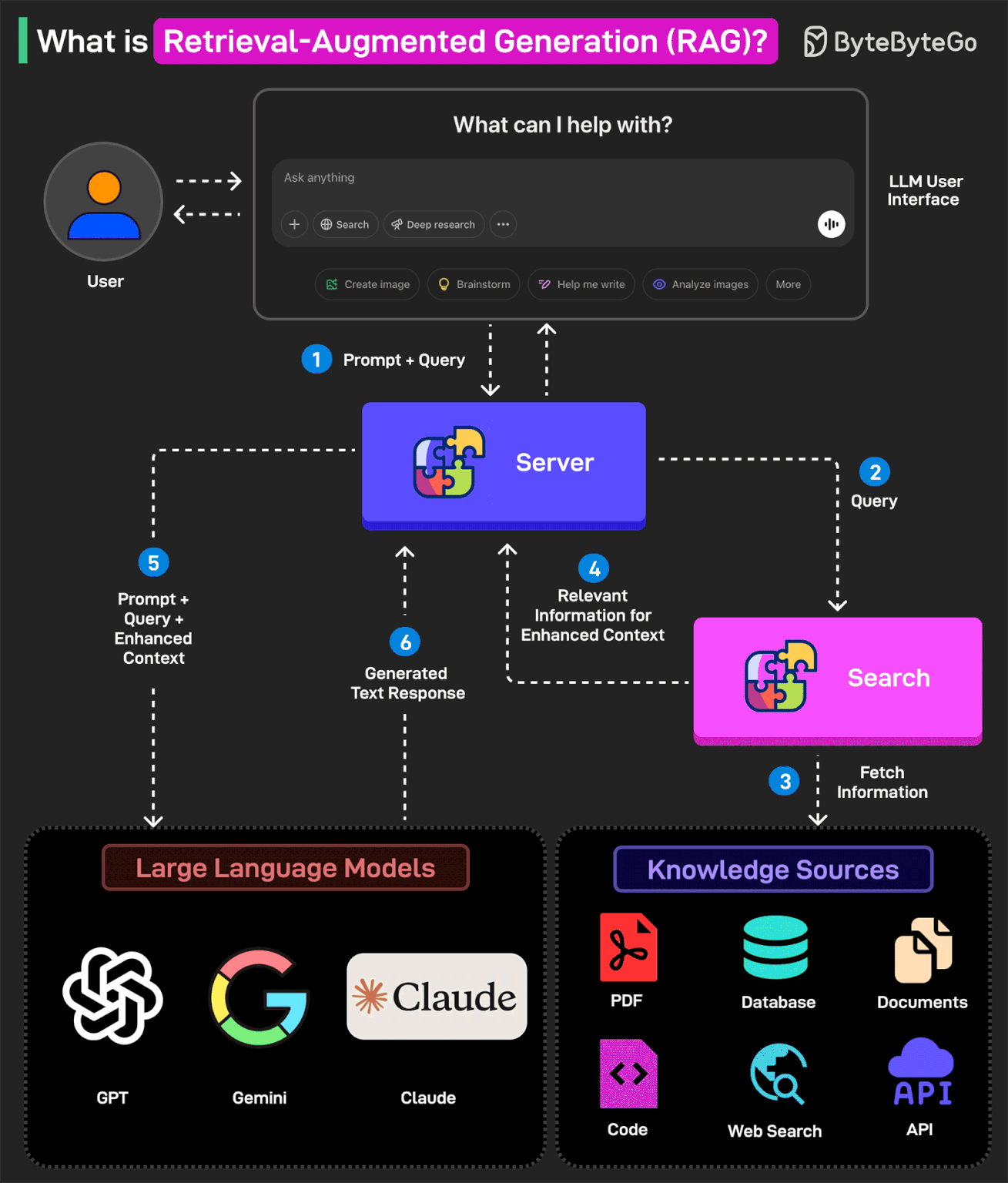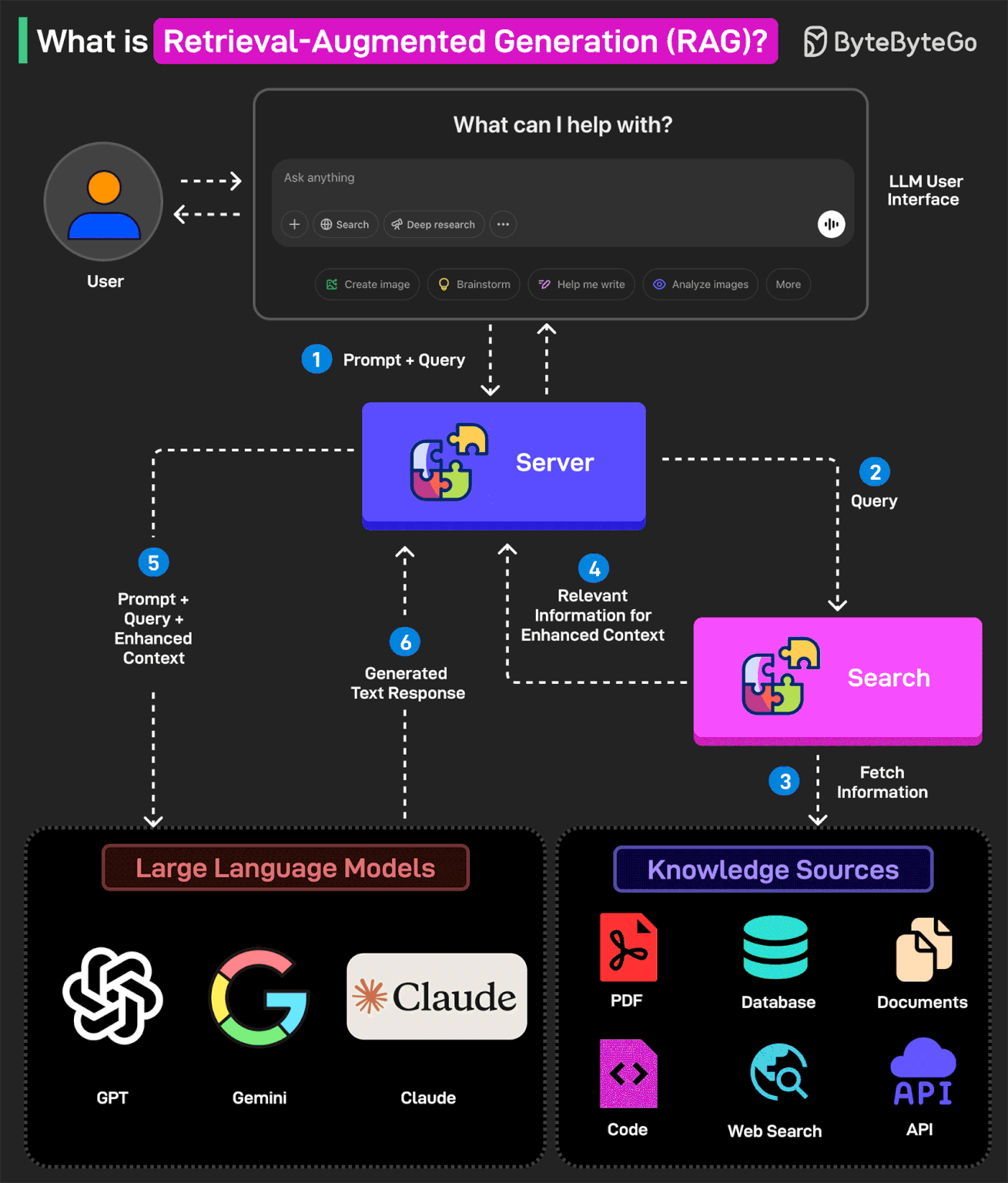
In other words, RAG helps extend the powerful capabilities of LLMs to specific domains or knowledge bases without the need for additional training.
Here’s how RAG works:
1 - The user writes a query prompt in the LLM’s user interface. This query is passed to the backend server where it is converted to a vector representation.
2 - The query is sent to a search system.
3 - This search system can refer to various knowledge sources such as PDFs, Web Search, Code-bases, Documents, Database, or APIs to fetch relevant information to answer the query.
4 - The fetched information is sent back to the RAG model.
5 - The model augments the original user input by adding the fetched information to the context and sending it to the LLM endpoint. Various LLM options are Open AI’s GPT, Claude Sonnet, Google Gemini, and so on.
6 - The LLM generates an answer based on the enhanced context and provides a response to the user.
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA