- Published on
Why do we keep talking about tokens in LLMs instead of words?
- Authors

- Name
- AbnAsia.org
- @steven_n_t
"Why do we keep talking about ""tokens"" in LLMs instead of words? It happens to be much more efficient to break the words into sub-words (tokens) for model performance!
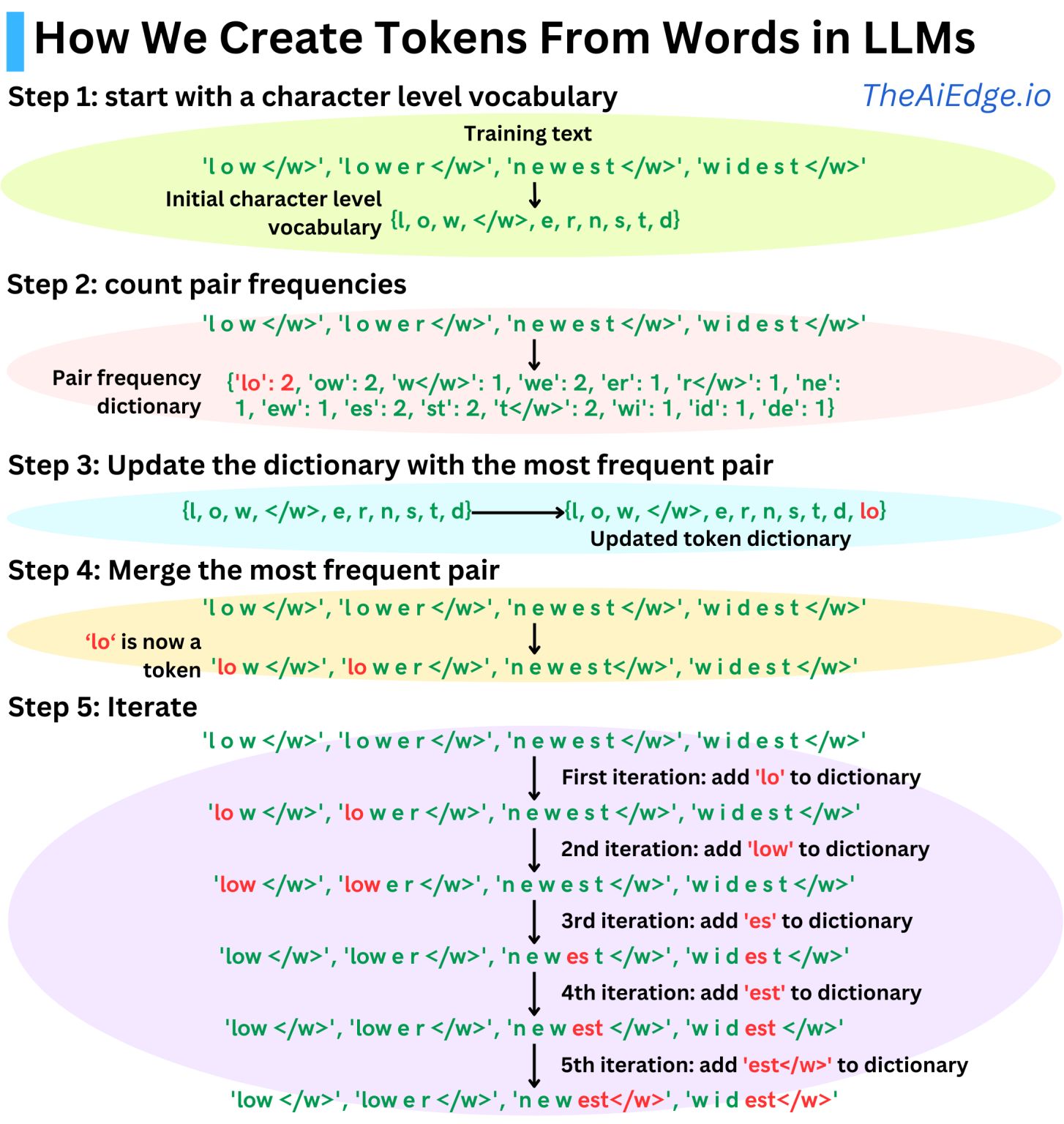
The typical strategy used in most modern LLMs since GPT-1 is the Byte Pair Encoding (BPE) strategy. The idea is to use, as tokens, sub-word units that appear often in the training data. The algorithm works as follows:
We start with a character-level tokenization
we count the pair frequencies
We merge the most frequent pair
We repeat the process until the dictionary is as big as we want it to be
The size of the dictionary becomes a hyperparameter that we can adjust based on our training data. For example, GPT-1 has a dictionary size of ~40K merges, GPT-2, GPT-3, and ChatGPT have a dictionary size of ~50K, and Llama 3 128K."
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA