- Published on
Asombroso nuevo modelo de China: Kimi k1.5: Escalando el aprendizaje por refuerzo con LLM.
- Authors

- Name
- AbnAsia.org
- @steven_n_t
🚀 Presentamos Kimi k1.5 --- un modelo multi-modal de nivel o1
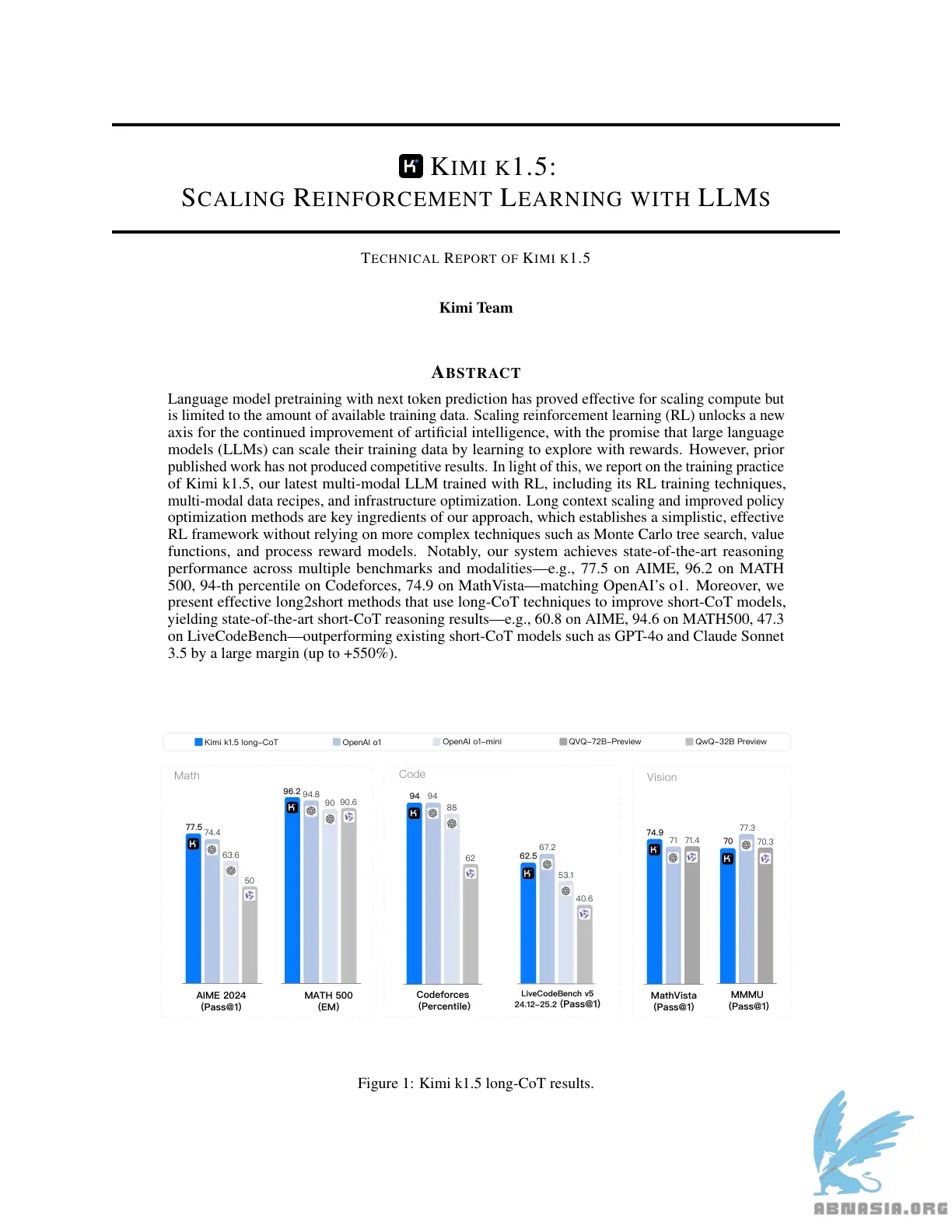

Rendimiento de Sota short-CoT, superando a GPT-4o y Claude Sonnet 3.5 en 📐AIME, 📐MATH-500, 💻 LiveCodeBench por un amplio margen (hasta +550%)
El rendimiento de Long-CoT coincide con o1 en múltiples modalidades (👀MathVista, 📐AIME, 💻Codeforces, etc)
El preentrenamiento de modelos de lenguaje con predicción de token siguiente ha demostrado ser efectivo para escalar el cómputo, pero está limitado a la cantidad de datos de entrenamiento disponibles. La escalada del aprendizaje por refuerzo (RL) desbloquea un nuevo eje para la mejora continua de la inteligencia artificial, con la promesa de que los grandes modelos de lenguaje (LLM) pueden escalar sus datos de entrenamiento aprendiendo a explorar con recompensas. Sin embargo, los trabajos publicados anteriormente no han producido resultados competitivos. En este sentido, informamos sobre la práctica de entrenamiento de Kimi k1.5, nuestro último LLM multi-modal entrenado con RL, incluyendo sus técnicas de entrenamiento de RL, recetas de datos multi-modales y optimización de infraestructura. La escalada de contexto largo y los métodos de optimización de política mejorados son ingredientes clave de nuestro enfoque, que establece un marco de RL simplista y efectivo sin depender de técnicas más complejas como la búsqueda de árbol de Monte Carlo, las funciones de valor y los modelos de recompensa de proceso. Destacamos que nuestro sistema logra un rendimiento de razonamiento de estado del arte en múltiples benchmarks y modalidades---por ejemplo, 77,5 en AIME, 96,2 en MATH 500, 94 percentil en Codeforces, 74,9 en MathVista---coincidiendo con o1 de OpenAI. Además, presentamos métodos efectivos de largo a corto que utilizan técnicas de contexto largo para mejorar los modelos de contexto corto, lo que produce resultados de razonamiento de contexto corto de estado del arte---por ejemplo, 60,8 en AIME, 94,6 en MATH500, 47,3 en LiveCodeBench---superando a los modelos de contexto corto existentes como GPT-4o y Claude Sonnet 3.5 por un amplio margen (hasta +550%).
Hay algunos ingredientes clave sobre el diseño y el entrenamiento de k1.5.
Escalada de contexto largo. Escalamos la ventana de contexto de RL a 128k y observamos una mejora continua del rendimiento con una longitud de contexto aumentada. Una idea clave detrás de nuestro enfoque es utilizar despliegues parciales para mejorar la eficiencia del entrenamiento---es decir, muestrear nuevas trayectorias reutilizando un gran trozo de trayectorias anteriores, evitando el costo de regenerar las nuevas trayectorias desde cero. Nuestra observación identifica la longitud del contexto como una dimensión clave de la escalada continua de RL con LLM.
Optimización de política mejorada. Derivamos una formulación de RL con contexto largo y empleamos una variante de descenso de espejo en línea para una optimización de política robusta. Este algoritmo se mejora aún más con nuestra estrategia de muestreo efectiva, penalización de longitud y optimización de la receta de datos.
Marco simplista. La escalada de contexto largo, combinada con los métodos de optimización de política mejorados, establece un marco de RL simplista para el aprendizaje con LLM. Dado que podemos escalar la longitud del contexto, los CoT aprendidos exhiben las propiedades de planificación, reflexión y corrección. Un aumento en la longitud del contexto tiene el efecto de aumentar el número de pasos de búsqueda. Como resultado, mostramos que se puede lograr un rendimiento sólido sin depender de técnicas más complejas como la búsqueda de árbol de Monte Carlo, las funciones de valor y los modelos de recompensa de proceso.
Multi-modalidades. Nuestro modelo se entrena conjuntamente en texto y datos de visión, lo que tiene la capacidad de razonar conjuntamente sobre las dos modalidades.
Autor
Ai Base Network (ABN), ABN ASIA fue fundada por personas con profundas raíces en la academia y experiencia laboral en EE.UU., Holanda, Hungría, Japón, Corea del Sur, Singapur y Vietnam. ABN Asia es donde la academia y la tecnología encuentran oportunidades. Con nuestras soluciones innovadoras y servicios competentes de desarrollo de software, estamos ayudando a las empresas a mejorar y a enfrentarse al mercado global. Nuestro compromiso: Más rápido. Mejor. Más confiable. En la mayoría de los casos: también más económico.
No dudes en contactarnos siempre que necesites servicios de TI, consultoría digital, soluciones de software listas para usar, o si deseas enviarnos solicitudes de propuestas (RFPs). Puedes contactarnos en [email protected]. Estamos listos para ayudarte con todas tus necesidades tecnológicas.

© ABN ASIA