- Published on
Modelos de Aprendizaje Automático: Métodos de Compresión de Modelos
- Authors

- Name
- AbnAsia.org
- @steven_n_t
¿Por qué? Porque ahora son demasiado grandes.
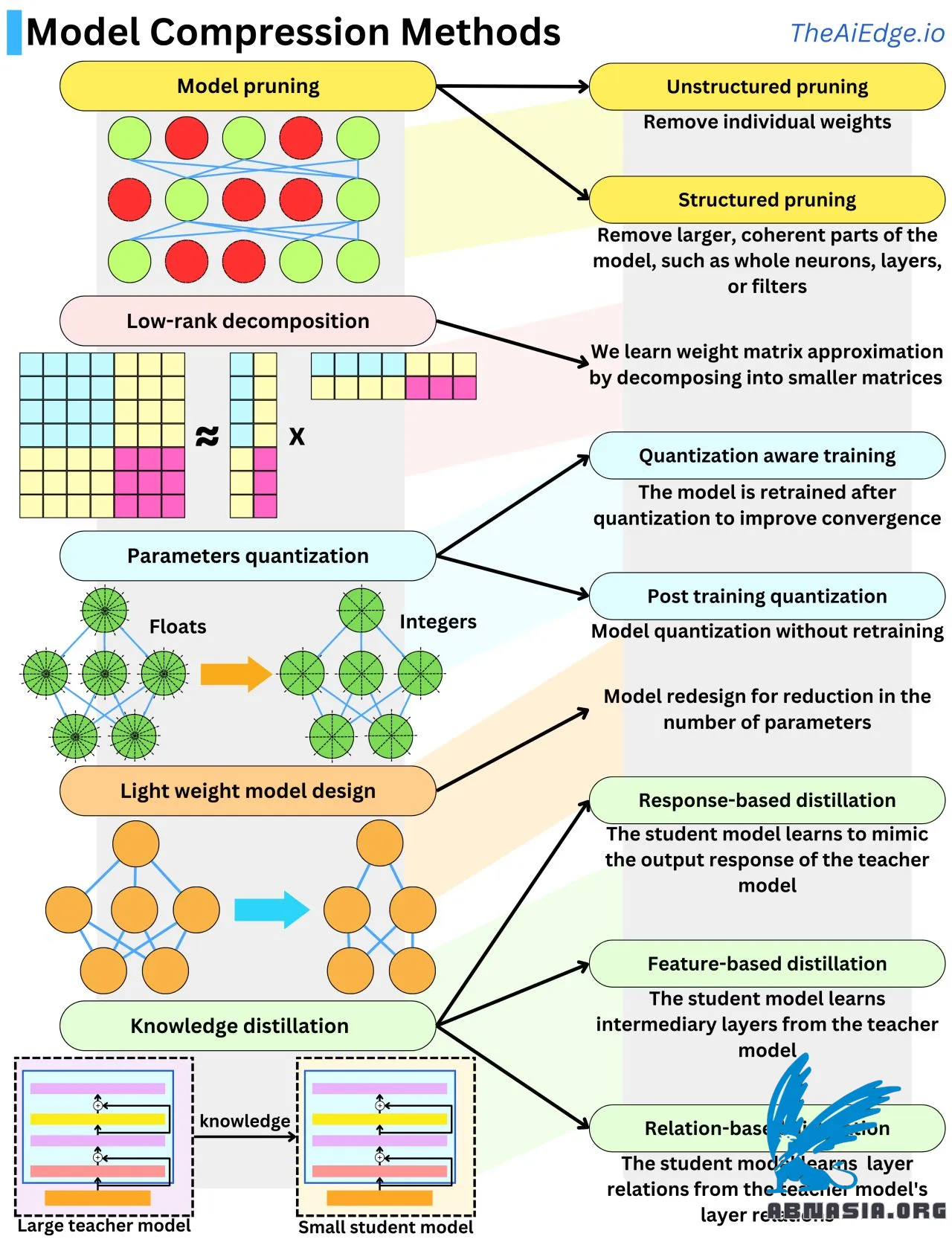
Hace no mucho tiempo, los modelos de aprendizaje automático más grandes con los que la mayoría de las personas trataban apenas alcanzaban unos pocos GB en tamaño de memoria. Ahora, cada nuevo modelo generativo que sale es de entre 1 mil millones y 1 billón de parámetros. Para tener una idea de la escala, un parámetro flotante, que son 32 bits o 4 bytes (o 2 bytes con Float16), por lo que estos nuevos modelos pueden escalar entre 4 GB y 4 TB en memoria, cada uno ejecutándose en hardware costoso. Y durante el algoritmo de retropropagación, estos modelos pueden necesitar hasta 10 veces esta cantidad de memoria. Debido al aumento de escala masivo, ha habido bastante investigación para reducir el tamaño del modelo sin afectar el rendimiento. Hay 5 técnicas principales para comprimir el tamaño del modelo.
La poda del modelo se trata de eliminar pesos no importantes de la red. El juego es entender qué significa "importante" en ese contexto. Un enfoque típico es medir el impacto en la función de pérdida de cada peso. Esto se puede hacer fácilmente mirando el gradiente y la segunda derivada de la función de pérdida. Otra forma de hacerlo es utilizar la regularización L1 o L2 y deshacerse de los pesos de baja magnitud. Eliminar neuronas enteras, capas o filtros se llama "poda estructurada" y es más eficiente cuando se trata de velocidad de inferencia.
La cuantización del modelo se trata de disminuir la precisión de los parámetros, típicamente moviéndose de flotante (32 bits) a entero (8 bits). Eso es una compresión del modelo 4 veces. La cuantización de los parámetros tiende a hacer que el modelo se desvíe de su punto de convergencia, por lo que es típico afinarlo con datos de entrenamiento adicionales para mantener el rendimiento del modelo alto. A esto lo llamamos "entrenamiento consciente de la cuantización". Cuando evitamos este último paso, se llama "cuantización posterior al entrenamiento", y se pueden realizar modificaciones heurísticas adicionales a los pesos para ayudar al rendimiento.
La descomposición de rango bajo proviene del hecho de que las matrices de pesos de las redes neuronales pueden ser aproximadas por productos de matrices de baja dimensión. Una matriz N x N puede ser aproximadamente descompuesta en un producto de 2 matrices N x 1. ¡Eso es una ganancia de complejidad espacial O(N^2) -> O(N)!
La destilación del conocimiento se trata de transferir conocimiento de un modelo a otro, típicamente de un modelo grande a uno más pequeño. Cuando el modelo estudiante aprende a producir respuestas de salida similares, eso es destilación basada en respuestas. Cuando el modelo estudiante aprende a reproducir capas intermedias similares, se llama destilación basada en características. Cuando el modelo estudiante aprende a reproducir la interacción entre capas, se llama destilación basada en relaciones.
El diseño de modelos ligeros se trata de utilizar conocimientos de resultados empíricos para diseñar arquitecturas más eficientes. Eso probablemente sea uno de los métodos más utilizados en la investigación de LLM.
Autor
Ai Base Network (ABN), ABN ASIA fue fundada por personas con profundas raíces en la academia y experiencia laboral en EE.UU., Holanda, Hungría, Japón, Corea del Sur, Singapur y Vietnam. ABN Asia es donde la academia y la tecnología encuentran oportunidades. Con nuestras soluciones innovadoras y servicios competentes de desarrollo de software, estamos ayudando a las empresas a mejorar y a enfrentarse al mercado global. Nuestro compromiso: Más rápido. Mejor. Más confiable. En la mayoría de los casos: también más económico.
No dudes en contactarnos siempre que necesites servicios de TI, consultoría digital, soluciones de software listas para usar, o si deseas enviarnos solicitudes de propuestas (RFPs). Puedes contactarnos en [email protected]. Estamos listos para ayudarte con todas tus necesidades tecnológicas.

© ABN ASIA