- Publié le
Comment construiriez-vous le moteur de recherche d'images de Google ?
- Auteurs

- Nom
- AbnAsia.org
- @steven_n_t
Google Photos devient-il trop restrictif pour vous ?
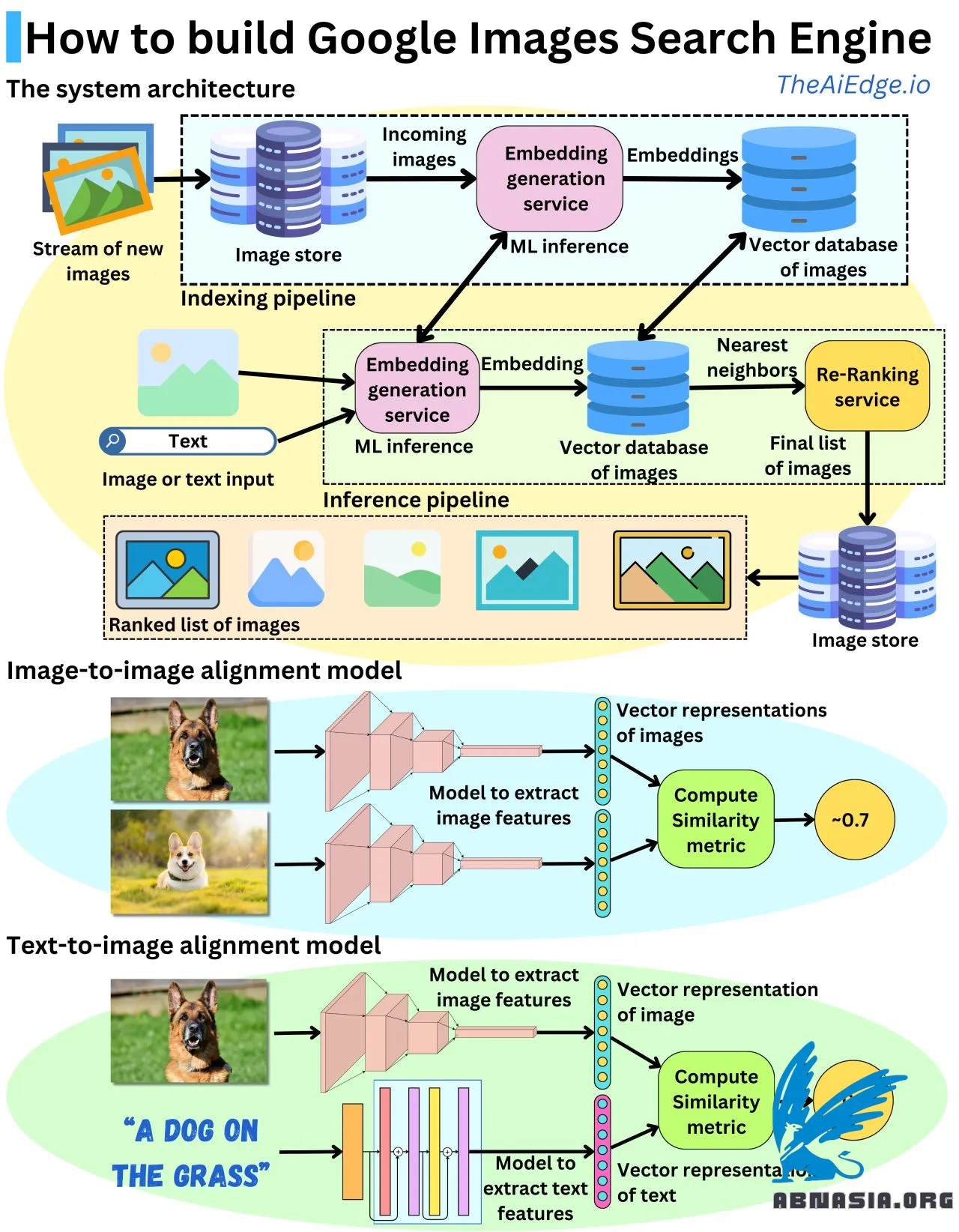
Google Image est un moteur de recherche où nous saisissons un texte ou une requête d'image et nous sommes présentés avec une liste classée d'images associées. Si nous utilisons un texte comme entrée, nous voulons nous assurer que les images sont bien décrites par le texte, et si nous utilisons une image comme entrée, nous voulons nous assurer de présenter les images les plus similaires.
Nous pouvons formuler ce problème comme un problème de classement. Nous avons besoin d'un modèle qui prend en entrée deux images et renvoie un score de similarité. En utilisant ce modèle, nous pouvons ensuite classer les images en fonction de ce score de similarité. Une approche de modélisation typique consiste à utiliser des modèles qui peuvent apprendre une représentation vectorielle (incrustation) des images et calculer une métrique de similarité sur ces vecteurs. Nous avons besoin d'un modèle qui puisse extraire les caractéristiques d'image pour apprendre une représentation vectorielle des images, et nous avons besoin d'un modèle qui puisse extraire les caractéristiques de texte pour apprendre une représentation vectorielle des entrées de texte. Nous devons co-entraîner les modèles d'image et de texte afin que les représentations vectorielles soient alignées sémantiquement.
Pour assurer une récupération rapide, nous devons avoir un moyen de stocker les images existantes et de rechercher rapidement des images similaires. Puisque nous codons les images dans leurs représentations vectorielles, il semble logique d'indexer les images dans une base de données vectorielle. Le pipeline d'indexation convertit les images d'origine en leurs représentations vectorielles et les indexe dans une base de données vectorielle.
Lorsqu'un utilisateur saisit une requête de texte ou d'image, nous devons renvoyer une liste d'images. Le service de génération d'incrustation génère une incrustation codée de la requête d'entrée. La requête d'incrustation est envoyée à la base de données vectorielle qui renvoie les plus proches voisins de la requête. Le service de re-classement est principalement utilisé pour re-classement des plus proches voisins en utilisant un meilleur modèle que le modèle de génération d'incrustation. Il pourrait être utilisé pour personnaliser le classement en fonction de l'utilisateur spécifique en utilisant des données spécifiques à l'utilisateur. La liste résultante est une liste d'identifiants d'image, et elle est ensuite envoyée au magasin d'images pour récupérer les images réelles à renvoyer à l'utilisateur.
Veuillez noter que la version française est assistée par Ai, des erreurs mineures peuvent donc exister.
Auteur
Ai Base Network (ABN), ABN ASIA a été fondée par des personnes ayant des racines profondes dans le milieu académique, avec une expérience professionnelle aux États-Unis, aux Pays-Bas, en Hongrie, au Japon, en Corée du Sud, à Singapour et au Vietnam. ABN ASIA est l'endroit où l'académie et la technologie rencontrent l'opportunité. Avec nos solutions de pointe et nos services de développement logiciel compétents, nous aidons les entreprises à se développer et à s'imposer sur la scène mondiale. Notre engagement : Plus vite. Mieux. Plus fiable. Dans la plupart des cas : moins cher également.
N'hésitez pas à nous contacter chaque fois que vous avez besoin de services informatiques, de conseils en matière de numérique, de solutions logicielles prêtes à l'emploi, ou si vous souhaitez nous envoyer des demandes de propositions (RFP). Vous pouvez nous contacter à l'adresse [email protected]. Nous sommes prêts à vous aider avec tous vos besoins technologiques.

© ABN ASIA