- Publié le
Float32, Float16 ou BFloat16 !
- Auteurs

- Nom
- AbnAsia.org
- @steven_n_t
Pourquoi est-ce important pour le Deep Learning ?
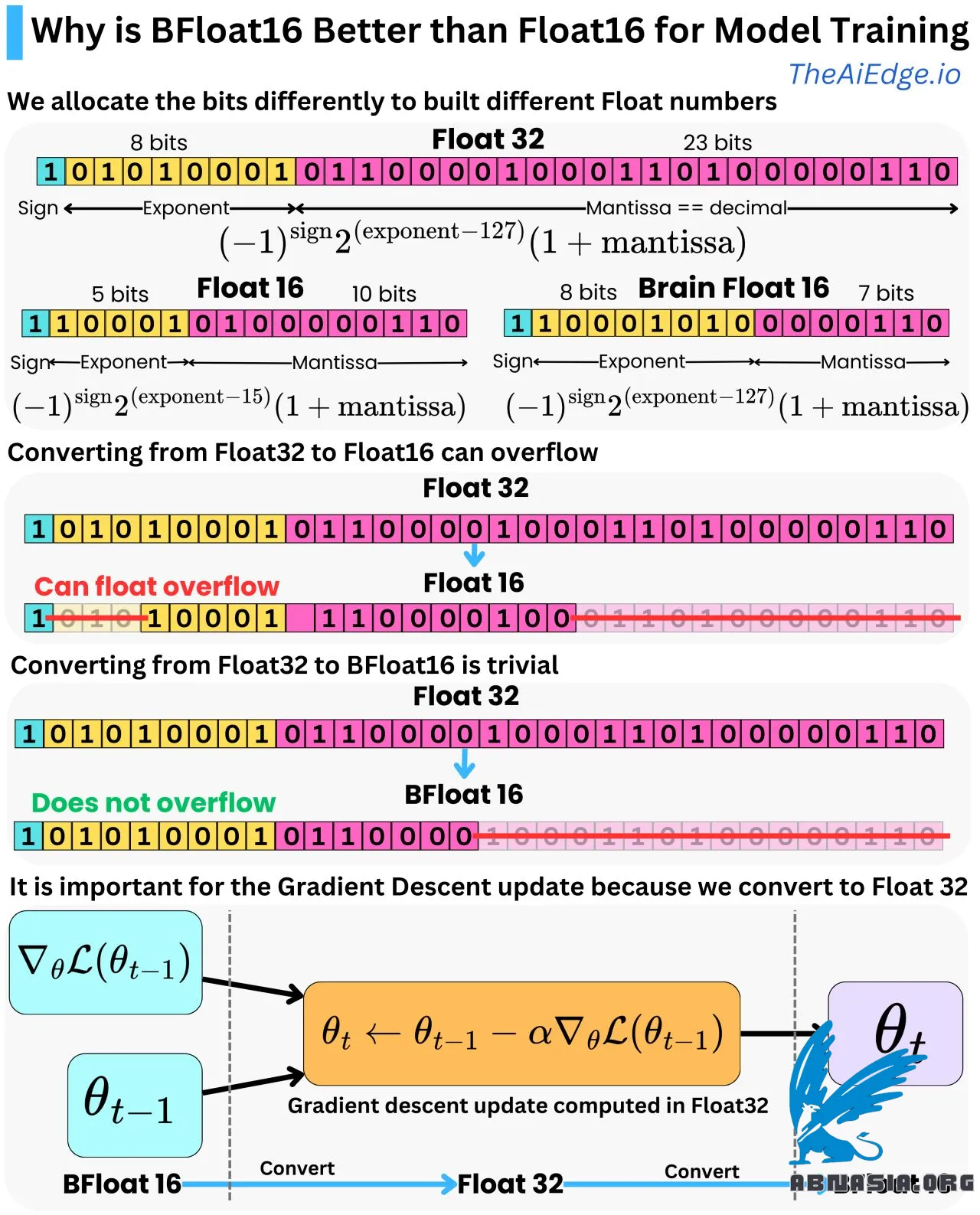
Ce sont simplement des niveaux de précision différents. Float32 est un moyen de représenter un nombre à virgule flottante avec 32 bits (1 ou 0), et Float16 / BFloat16 est un moyen de représenter le même nombre avec seulement 16 bits. Avec Float32, nous allouons le premier bit pour représenter le signe, les 8 bits suivants pour représenter l'exposant, et les 23 bits suivants pour représenter les décimales (également appelées mantisse). Nous pouvons passer de la représentation binaire à la représentation décimale en utilisant la formule simple :
Float32 = (-1)^signe * 2^(exposant - 127) * (1 + mantisse)
Et cela peut varier entre -3,4e^38 et 3,4e^38.
Float16 utilise 1 bit pour le signe, 5 bits pour l'exposant et 10 bits pour la mantisse avec la formule :
Float16 = (-1)^signe * 2^(exposant - 15) * (1 + mantisse)
Et la plage est comprise entre -6,55e^4 et 6,55e^4 (c'est-à-dire une plage beaucoup plus petite !). Pour convertir de Float32 à Float16, vous n'avez besoin que de supprimer les chiffres qui ne peuvent pas tenir dans les 5 et 10 bits alloués pour l'exposant et la mantisse. Pour la mantisse, vous créez simplement une erreur d'arrondi, mais si le nombre Float32 est supérieur à 6,55e^4, vous créerez une erreur de débordement de virgule flottante ! Il est donc tout à fait possible d'obtenir des erreurs de conversion de Float32 à Float16.
Brain Float 16 (BFloat16) est une autre représentation de virgule flottante en 16 bits. Nous offrons moins de précision décimale, mais autant de plage que Float32. Nous avons 8 bits pour l'exposant et 7 bits pour la mantisse avec la même formule de conversion :
BFloat16 = (-1)^signe * 2^(exposant - 127) * (1 + mantisse)
Donnant la même plage que Float32 [-3,4e^38 et 3,4e^38]. La conversion de Float32 à BFloat16 est donc triviale, car vous n'avez besoin que de réduire la mantisse.
C'est très important pour l'apprentissage profond, car dans l'algorithme de rétropropagation, les paramètres du modèle sont mis à jour par un optimiseur de descente de gradient (par exemple, Adam), et les calculs sont effectués avec une précision Float32 pour garantir moins d'erreurs d'arrondi. Les paramètres du modèle et les gradients sont généralement stockés en mémoire en Float16 pour réduire la pression sur la mémoire, nous devons donc convertir entre Float16 et Float32. BFloat16 est un bon choix, car il empêche les erreurs de débordement de virgule flottante tout en conservant suffisamment de précision pour les passes avant et arrière de l'algorithme de rétropropagation.
Veuillez noter que la version française est assistée par Ai, des erreurs mineures peuvent donc exister.
Auteur
Ai Base Network (ABN), ABN ASIA a été fondée par des personnes ayant des racines profondes dans le milieu académique, avec une expérience professionnelle aux États-Unis, aux Pays-Bas, en Hongrie, au Japon, en Corée du Sud, à Singapour et au Vietnam. ABN ASIA est l'endroit où l'académie et la technologie rencontrent l'opportunité. Avec nos solutions de pointe et nos services de développement logiciel compétents, nous aidons les entreprises à se développer et à s'imposer sur la scène mondiale. Notre engagement : Plus vite. Mieux. Plus fiable. Dans la plupart des cas : moins cher également.
N'hésitez pas à nous contacter chaque fois que vous avez besoin de services informatiques, de conseils en matière de numérique, de solutions logicielles prêtes à l'emploi, ou si vous souhaitez nous envoyer des demandes de propositions (RFP). Vous pouvez nous contacter à l'adresse [email protected]. Nous sommes prêts à vous aider avec tous vos besoins technologiques.

© ABN ASIA