- Publié le
Incroyable nouveau modèle de Chine : Kimi k1.5 : mise à l'échelle de l'apprentissage par renforcement avec les LLM.
- Auteurs

- Nom
- AbnAsia.org
- @steven_n_t
🚀 Présentation de Kimi k1.5 --- un modèle multi-modal de niveau o1
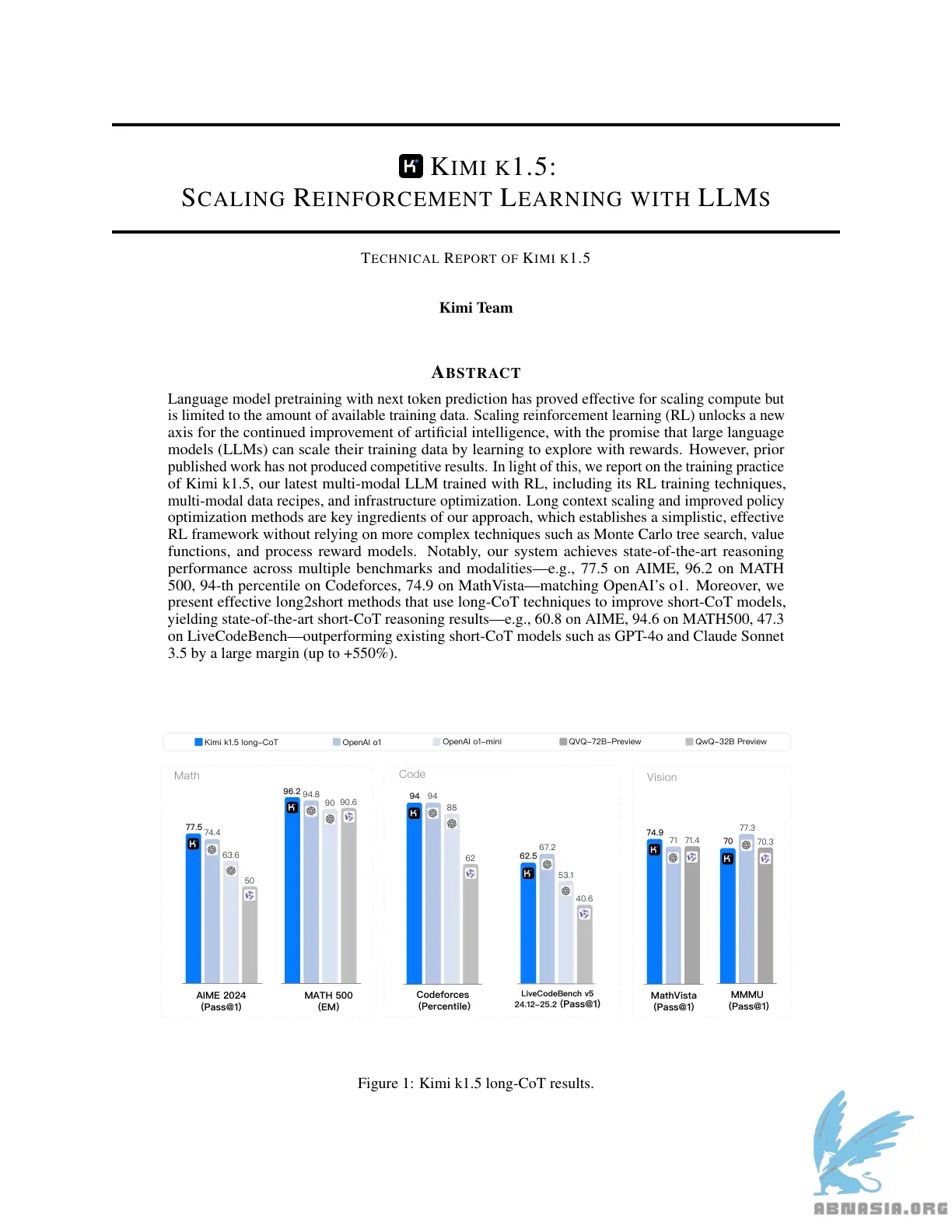

Performances Sota de short-CoT, surpassant GPT-4o et Claude Sonnet 3.5 sur 📐AIME, 📐MATH-500, 💻 LiveCodeBench avec une grande marge (jusqu'à +550%)
Les performances Long-CoT correspondent à o1 sur plusieurs modalités (👀MathVista, 📐AIME, 💻Codeforces, etc)
Le pré-entraînement de modèle de langage avec la prédiction du prochain jeton s'est avéré efficace pour mettre à l'échelle le calcul, mais est limité à la quantité de données de formation disponibles. La mise à l'échelle de l'apprentissage par renforcement (RL) débloque un nouvel axe pour l'amélioration continue de l'intelligence artificielle, avec la promesse que les grands modèles de langage (LLM) peuvent mettre à l'échelle leurs données de formation en apprenant à explorer avec des récompenses. Cependant, les travaux publiés précédemment n'ont pas produit de résultats compétitifs. À cette lumière, nous rendons compte de la pratique de formation de Kimi k1.5, notre dernier LLM multi-modal entraîné avec RL, y compris ses techniques d'entraînement RL, ses recettes de données multi-modales et son optimisation d'infrastructure. La mise à l'échelle du contexte long et les méthodes d'optimisation de stratégie améliorées sont des ingrédients clés de notre approche, qui établit un cadre RL simple et efficace sans s'appuyer sur des techniques plus complexes telles que la recherche arborescente de Monte Carlo, les fonctions de valeur et les modèles de récompense de processus. Notamment, notre système atteint des performances de raisonnement de pointe sur plusieurs références et modalités --- par exemple, 77,5 sur AIME, 96,2 sur MATH 500, 94e percentile sur Codeforces, 74,9 sur MathVista --- en correspondant avec o1 d'OpenAI. De plus, nous présentons des méthodes long2short efficaces qui utilisent des techniques long-CoT pour améliorer les modèles short-CoT, obtenant des résultats de raisonnement short-CoT de pointe --- par exemple, 60,8 sur AIME, 94,6 sur MATH500, 47,3 sur LiveCodeBench --- surpassant les modèles short-CoT existants tels que GPT-4o et Claude Sonnet 3.5 avec une grande marge (jusqu'à +550%).
Il y a quelques ingrédients clés dans la conception et la formation de k1.5.
Mise à l'échelle du contexte long. Nous mettons à l'échelle la fenêtre de contexte de RL à 128k et observons une amélioration continue des performances avec une augmentation de la longueur de contexte. Une idée clé derrière notre approche est d'utiliser des rebondissements partiels pour améliorer l'efficacité de formation --- c'est-à-dire, échantillonnage de nouvelles trajectoires en réutilisant un grand morceau de trajectoires précédentes, en évitant le coût de régénérer les nouvelles trajectoires à partir de zéro. Notre observation identifie la longueur de contexte comme une dimension clé de la mise à l'échelle continue de RL avec les LLM.
Optimisation de stratégie améliorée. Nous dérivons une formulation de RL avec long-CoT et employons une variante de la descente en ligne de miroir pour une optimisation de stratégie robuste. Cet algorithme est encore amélioré par notre stratégie d'échantillonnage efficace, la pénalité de longueur et l'optimisation de la recette de données.
Cadre simple. La mise à l'échelle du contexte long, combinée avec les méthodes d'optimisation de stratégie améliorées, établit un cadre RL simple pour l'apprentissage avec les LLM. Puisque nous sommes capables de mettre à l'échelle la longueur de contexte, les CoT appris présentent les propriétés de planification, de réflexion et de correction. Une augmentation de la longueur de contexte a un effet d'augmentation du nombre d'étapes de recherche. En conséquence, nous montrons que des performances solides peuvent être atteintes sans s'appuyer sur des techniques plus complexes telles que la recherche arborescente de Monte Carlo, les fonctions de valeur et les modèles de récompense de processus.
Multimodalités. Notre modèle est entraîné conjointement sur des données textuelles et visuelles, ce qui lui permet de raisonner conjointement sur les deux modalités.
Veuillez noter que la version française est assistée par Ai, des erreurs mineures peuvent donc exister.
Auteur
Ai Base Network (ABN), ABN ASIA a été fondée par des personnes ayant des racines profondes dans le milieu académique, avec une expérience professionnelle aux États-Unis, aux Pays-Bas, en Hongrie, au Japon, en Corée du Sud, à Singapour et au Vietnam. ABN ASIA est l'endroit où l'académie et la technologie rencontrent l'opportunité. Avec nos solutions de pointe et nos services de développement logiciel compétents, nous aidons les entreprises à se développer et à s'imposer sur la scène mondiale. Notre engagement : Plus vite. Mieux. Plus fiable. Dans la plupart des cas : moins cher également.
N'hésitez pas à nous contacter chaque fois que vous avez besoin de services informatiques, de conseils en matière de numérique, de solutions logicielles prêtes à l'emploi, ou si vous souhaitez nous envoyer des demandes de propositions (RFP). Vous pouvez nous contacter à l'adresse [email protected]. Nous sommes prêts à vous aider avec tous vos besoins technologiques.

© ABN ASIA