- Publié le
Modèles d'apprentissage automatique : Méthodes de compression de modèles
- Auteurs

- Nom
- AbnAsia.org
- @steven_n_t
Pourquoi ? Parce qu'ils sont beaucoup trop grands maintenant.
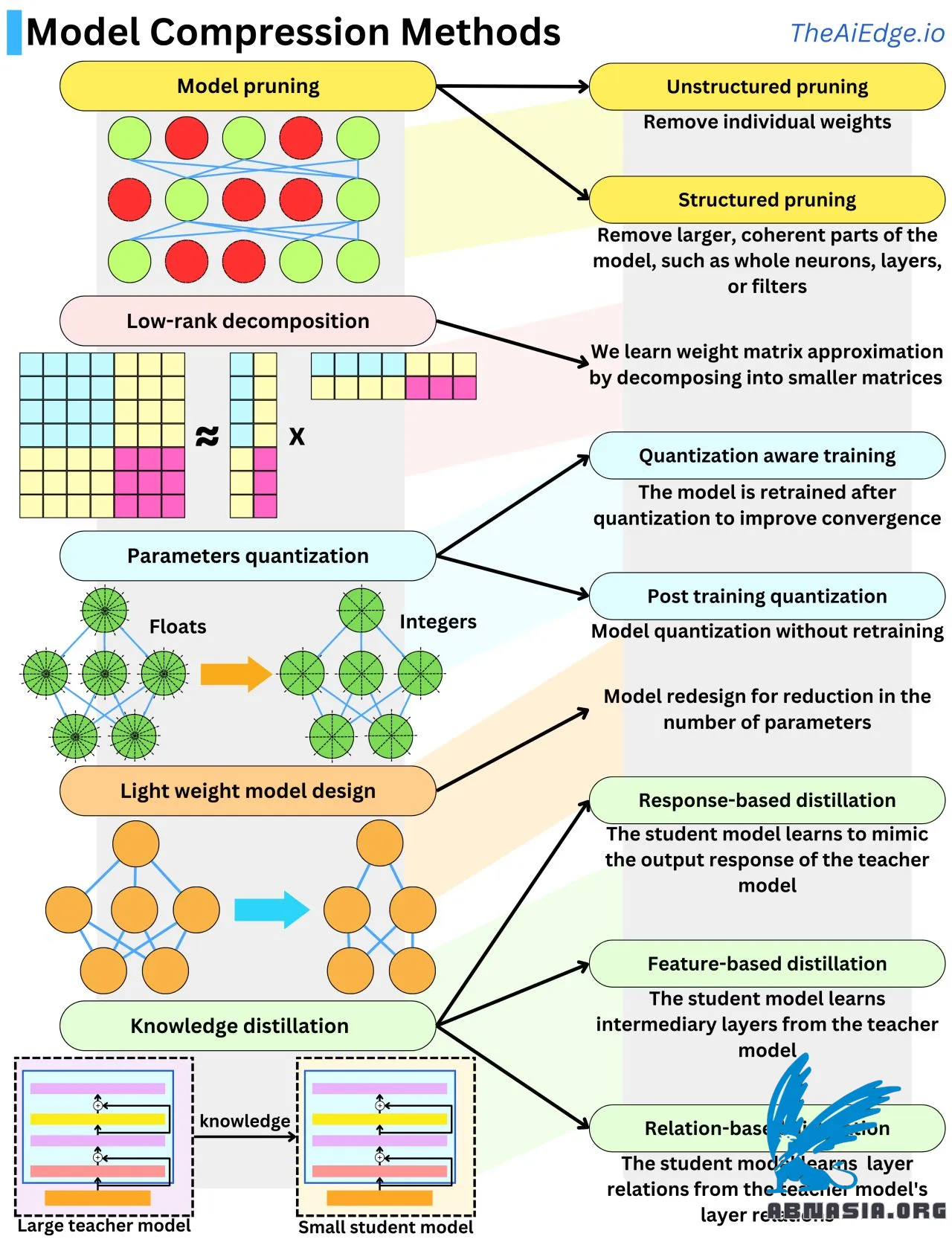
Il n'y a pas si longtemps, les plus grands modèles d'apprentissage automatique avec lesquels la plupart des gens avaient affaire atteignaient tout juste quelques GB en taille mémoire. Maintenant, chaque nouveau modèle génératif qui sort est entre 1 milliard et 1 billion de paramètres ! Pour se faire une idée de l'échelle, un paramètre flottant, c'est 32 bits ou 4 octets (ou 2 octets avec Float16), donc ces nouveaux modèles peuvent atteindre entre 4 GB et 4 To en mémoire, chacun fonctionnant sur du matériel coûteux. Et pendant l'algorithme de rétropropagation, ces modèles peuvent avoir besoin d'autant de mémoire, voire dix fois plus. En raison de l'augmentation massive de l'échelle, il y a eu beaucoup de recherches pour réduire la taille du modèle tout en maintenant les performances. Il existe 5 principales techniques pour compresser la taille du modèle.
L'élagage du modèle consiste à supprimer les poids non importants du réseau. Le jeu consiste à comprendre ce que signifie "important" dans ce contexte. Une approche typique consiste à mesurer l'impact de chaque poids sur la fonction de perte. Cela peut être fait facilement en regardant le gradient et la dérivée seconde de la fonction de perte. Une autre façon de le faire est d'utiliser la régularisation L1 ou L2 et de se débarrasser des poids de faible amplitude. Supprimer des neurones entiers, des couches ou des filtres est appelé "élagage structuré" et est plus efficace en termes de vitesse d'inférence.
La quantification du modèle consiste à diminuer la précision des paramètres, généralement en passant de flottant (32 bits) à entier (8 bits). C'est une compression du modèle 4 fois. La quantification des paramètres tend à faire dévier le modèle de son point de convergence, il est donc typique de le réajuster avec des données de formation supplémentaires pour maintenir les performances du modèle élevées. Nous appelons cela "formation consciente de la quantification". Lorsque nous évitons cette dernière étape, on l'appelle "quantification après formation", et des modifications heuristiques supplémentaires peuvent être effectuées sur les poids pour aider les performances.
La décomposition de bas rang vient du fait que les matrices de poids des réseaux de neurones peuvent être approximées par des produits de matrices de basse dimension. Une matrice N x N peut être approximativement décomposée en un produit de 2 matrices N x 1. C'est un gain de complexité spatiale O(N^2) -> O(N) !
La distillation des connaissances consiste à transférer des connaissances d'un modèle à un autre, généralement d'un grand modèle à un plus petit. Lorsque le modèle étudiant apprend à produire des réponses de sortie similaires, c'est la distillation basée sur les réponses. Lorsque le modèle étudiant apprend à reproduire des couches intermédiaires similaires, c'est la distillation basée sur les caractéristiques. Lorsque le modèle étudiant apprend à reproduire l'interaction entre les couches, c'est la distillation basée sur les relations.
La conception de modèle léger consiste à utiliser des connaissances provenant de résultats empiriques pour concevoir des architectures plus efficaces. C'est probablement l'une des méthodes les plus utilisées dans la recherche sur les LLM.
Veuillez noter que la version française est assistée par Ai, des erreurs mineures peuvent donc exister.
Auteur
Ai Base Network (ABN), ABN ASIA a été fondée par des personnes ayant des racines profondes dans le milieu académique, avec une expérience professionnelle aux États-Unis, aux Pays-Bas, en Hongrie, au Japon, en Corée du Sud, à Singapour et au Vietnam. ABN ASIA est l'endroit où l'académie et la technologie rencontrent l'opportunité. Avec nos solutions de pointe et nos services de développement logiciel compétents, nous aidons les entreprises à se développer et à s'imposer sur la scène mondiale. Notre engagement : Plus vite. Mieux. Plus fiable. Dans la plupart des cas : moins cher également.
N'hésitez pas à nous contacter chaque fois que vous avez besoin de services informatiques, de conseils en matière de numérique, de solutions logicielles prêtes à l'emploi, ou si vous souhaitez nous envoyer des demandes de propositions (RFP). Vous pouvez nous contacter à l'adresse [email protected]. Nous sommes prêts à vous aider avec tous vos besoins technologiques.

© ABN ASIA