- Publié le
OpenAi O1 : Très bon benchmark
- Auteurs

- Nom
- AbnAsia.org
- @steven_n_t
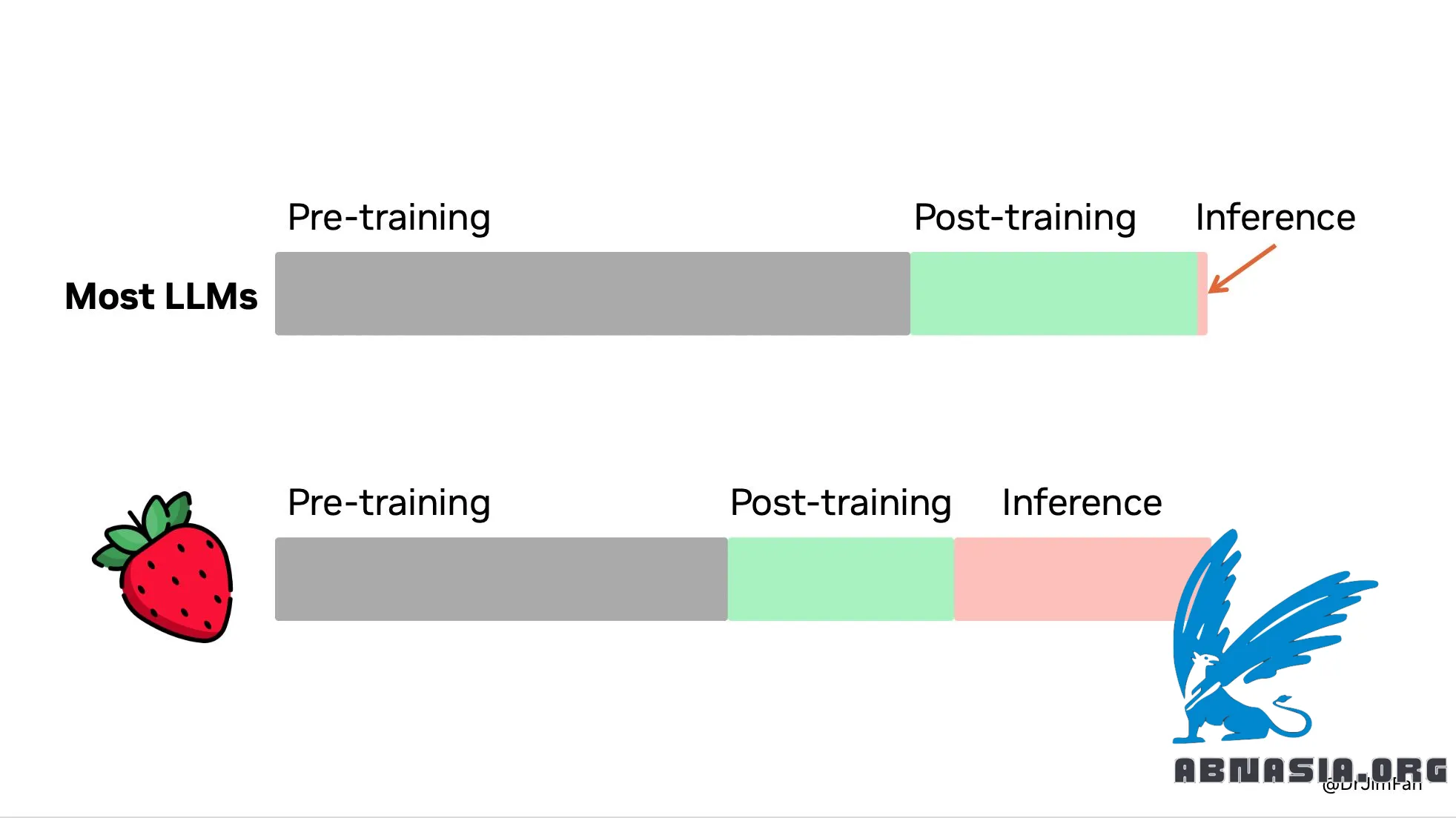
"OpenAI Strawberry (o1) est sorti ! Nous voyons enfin le paradigme de la mise à l'échelle du temps d'inférence popularisé et déployé en production. Comme Sutton l'a dit dans Bitter Lesson, il n'existe que deux techniques qui évoluent indéfiniment avec le calcul : l'apprentissage et la recherche. Il est temps de se concentrer sur ce dernier.
Vous n'avez pas besoin d'un énorme modèle pour effectuer un raisonnement. De nombreux paramètres sont dédiés à la mémorisation de faits, afin de bien performer dans des benchmarks comme le quiz QA. Il est possible de déduire le raisonnement à partir de la connaissance, c'est-à-dire d'un petit « noyau de raisonnement » qui sait appeler des outils comme le navigateur et le vérificateur de code. Le calcul pré-entraînement peut être diminué.
Une énorme quantité de calcul est transférée vers l'inférence plutôt que vers la pré/post-formation. Les LLM sont des simulateurs basés sur du texte. En déployant de nombreuses stratégies et scénarios possibles dans le simulateur, le modèle finira par converger vers de bonnes solutions. Le processus est un problème bien étudié comme la recherche dans les arbres de Monte Carlo (MCTS) d'AlphaGo.
OpenAI doit avoir compris la loi de mise à l'échelle d'inférence il y a longtemps, que le monde universitaire vient tout juste de découvrir. Deux articles ont été publiés sur Arxiv à une semaine d'intervalle le mois dernier :
Large Language Monkeys : mise à l'échelle du calcul d'inférence avec échantillonnage répété. Brown et coll. constate que DeepSeek-Coder passe de 15,9 % avec un échantillon à 56 % avec 250 échantillons sur SWE-Bench, battant Sonnet-3.5.
La mise à l'échelle optimale du calcul du temps de test LLM peut être plus efficace que la mise à l'échelle des paramètres du modèle. Snell et coll. constate que PaLM 2-S bat un modèle 14x plus grand sur MATH avec recherche au moment du test.
La production de o1 est beaucoup plus difficile que de fixer les critères académiques. En cas de problèmes de raisonnement dans la nature, comment décider quand arrêter la recherche ? Quelle est la fonction de récompense ? Critère de réussite ? Quand appeler des outils comme un interpréteur de code dans la boucle ? Comment prendre en compte le coût de calcul de ces processus CPU ? Leur message de recherche ne partageait pas grand-chose.
Strawberry devient facilement un volant de données. Si la réponse est correcte, l'ensemble de la trace de recherche devient un mini ensemble de données d'exemples de formation, qui contiennent à la fois des récompenses positives et négatives.
Cela améliore à son tour le cœur du raisonnement pour les futures versions de GPT, de la même manière que le réseau de valeurs d'AlphaGo - utilisé pour évaluer la qualité de chaque poste au conseil d'administration - s'améliore à mesure que MCTS génère des données de formation de plus en plus raffinées."
Veuillez noter que la version française est assistée par Ai, des erreurs mineures peuvent donc exister.
Auteur
Ai Base Network (ABN), ABN ASIA a été fondée par des personnes ayant des racines profondes dans le milieu académique, avec une expérience professionnelle aux États-Unis, aux Pays-Bas, en Hongrie, au Japon, en Corée du Sud, à Singapour et au Vietnam. ABN ASIA est l'endroit où l'académie et la technologie rencontrent l'opportunité. Avec nos solutions de pointe et nos services de développement logiciel compétents, nous aidons les entreprises à se développer et à s'imposer sur la scène mondiale. Notre engagement : Plus vite. Mieux. Plus fiable. Dans la plupart des cas : moins cher également.
N'hésitez pas à nous contacter chaque fois que vous avez besoin de services informatiques, de conseils en matière de numérique, de solutions logicielles prêtes à l'emploi, ou si vous souhaitez nous envoyer des demandes de propositions (RFP). Vous pouvez nous contacter à l'adresse [email protected]. Nous sommes prêts à vous aider avec tous vos besoins technologiques.

© ABN ASIA