- Diterbitkan pada
4 strategi pelatihan multi-GPU dijelaskan secara visual.
- Penulis

- Nama
- AbnAsia.org
- @steven_n_t
Secara default, model deep learning hanya menggunakan satu GPU untuk pelatihan, bahkan jika beberapa GPU tersedia. Berikut adalah sebuah solusi.
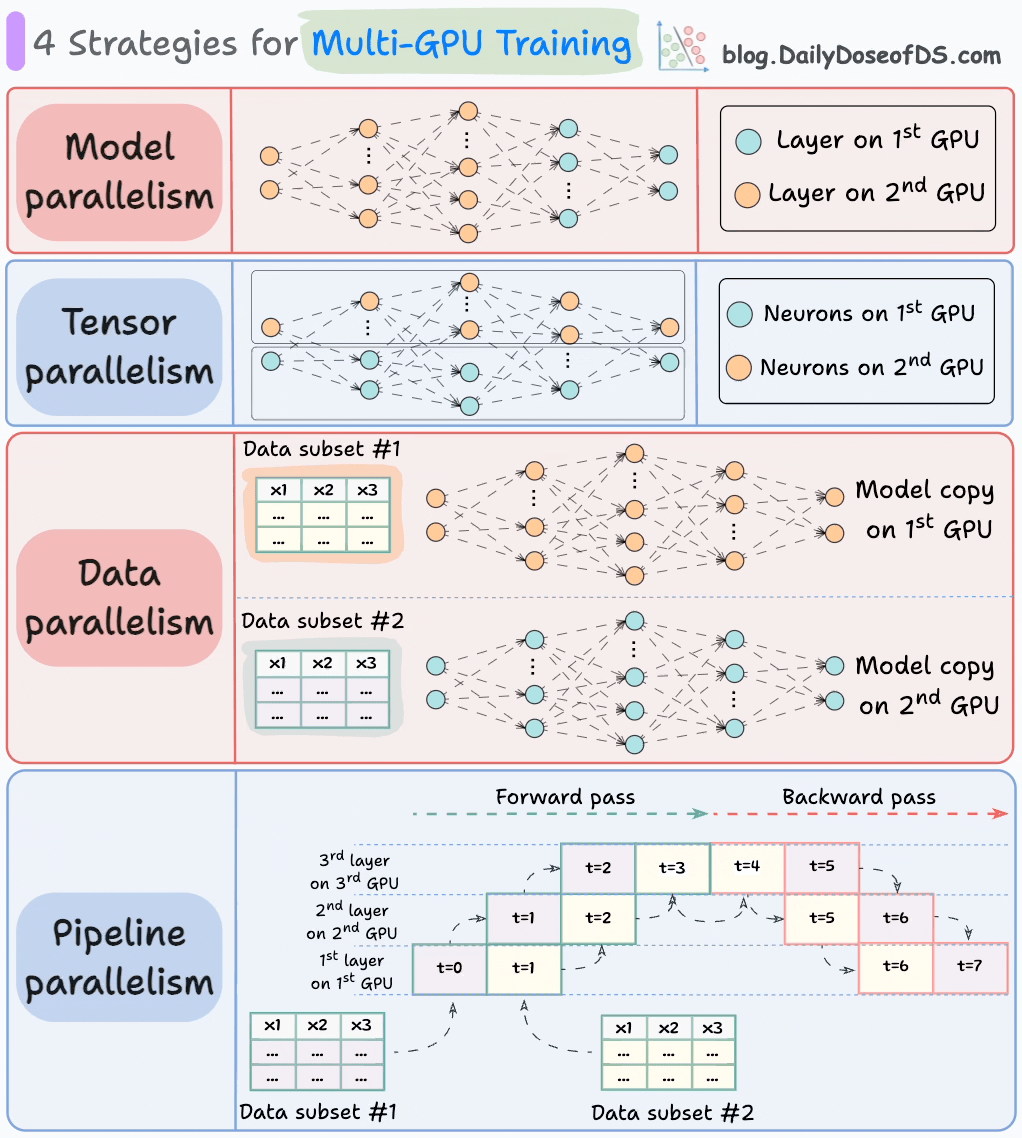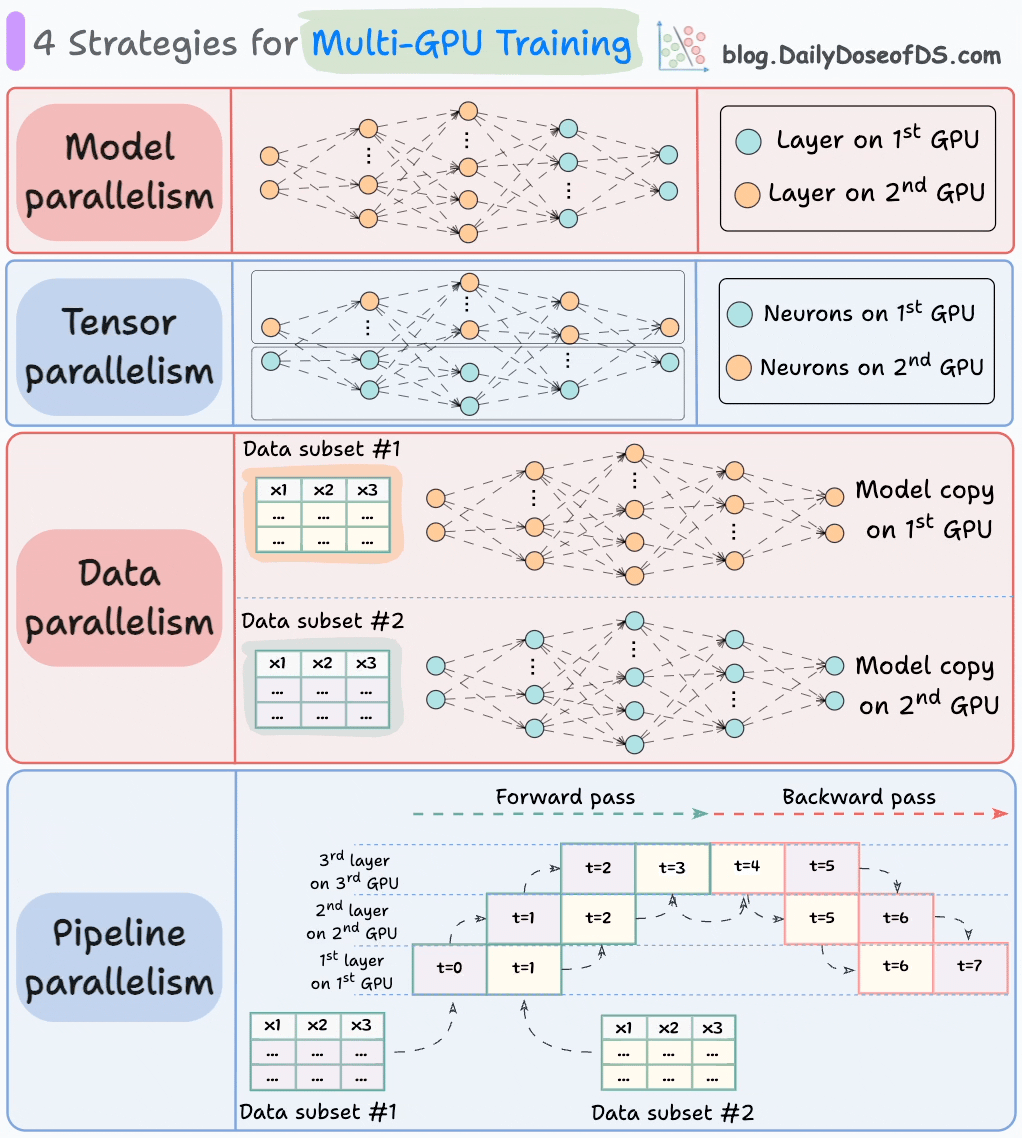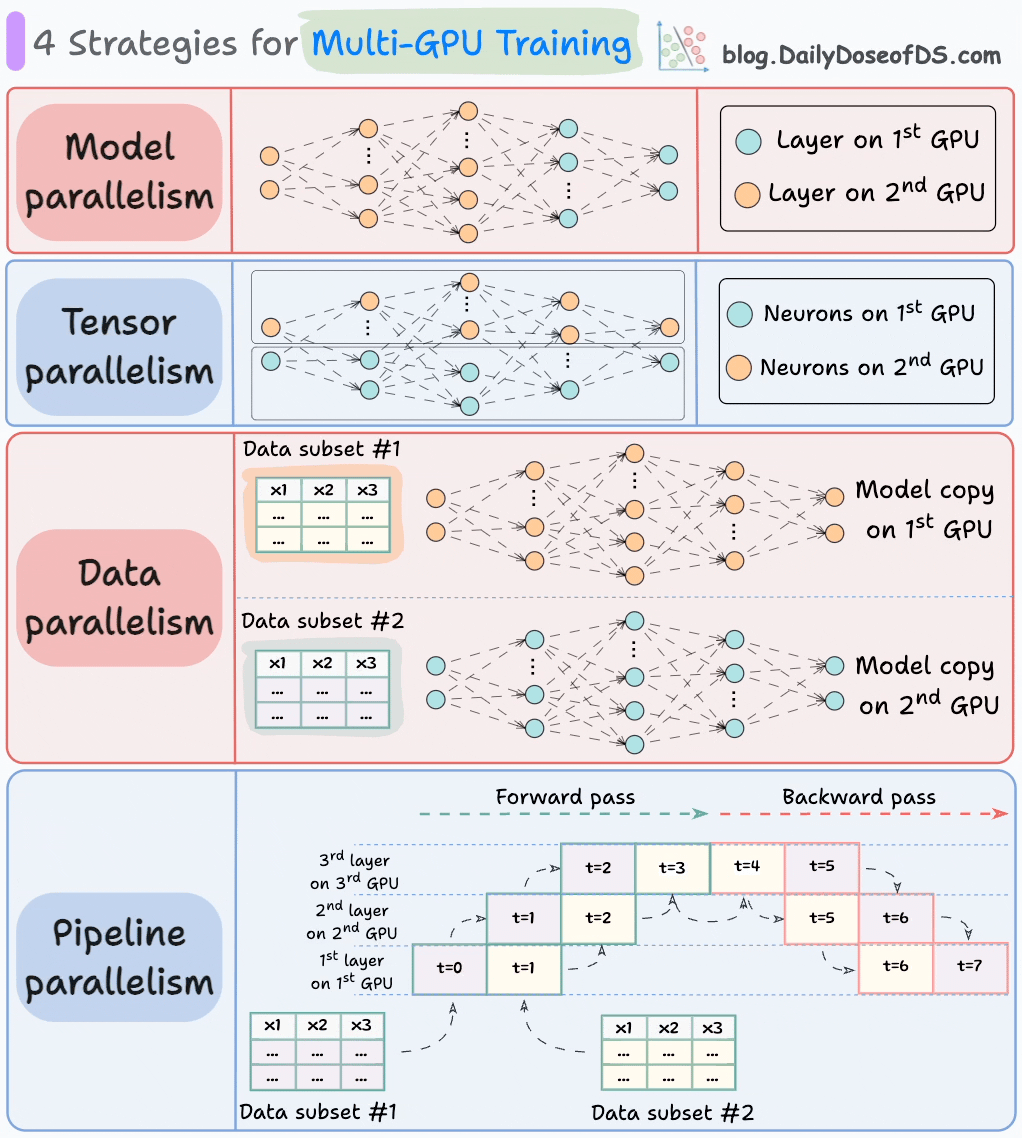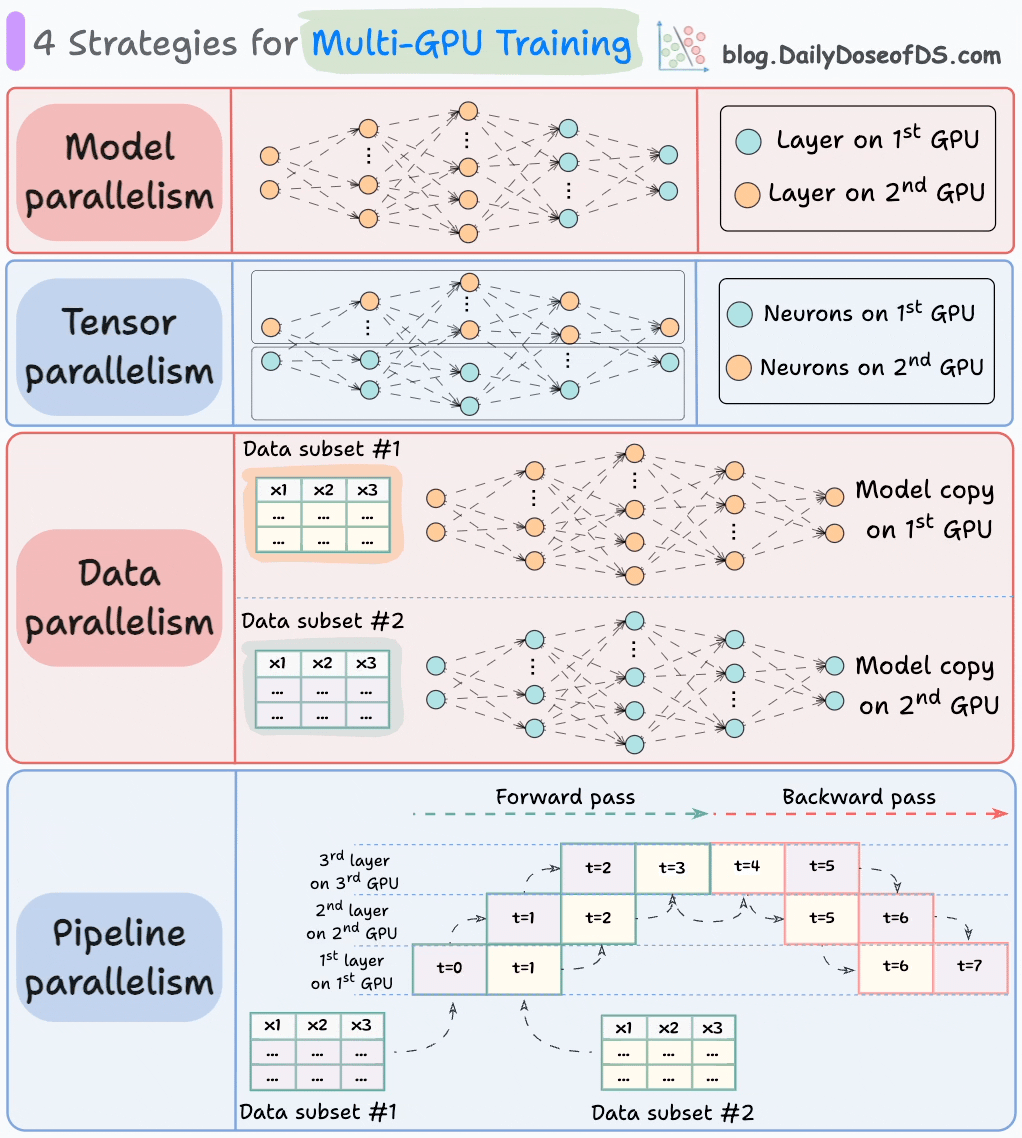
Cara ideal untuk melanjutkan (terutama dalam pengaturan big-data) adalah dengan mendistribusikan beban kerja pelatihan di seluruh beberapa GPU.
Grafik di bawah ini menggambarkan empat strategi umum untuk pelatihan multi-GPU:
- Paralelisme model
- Bagian-bagian yang berbeda (atau lapisan) dari model ditempatkan pada GPU yang berbeda.
- Berguna untuk model yang sangat besar yang tidak muat pada satu GPU.
- Namun, paralelisme model juga memperkenalkan hambatan yang parah karena memerlukan aliran data antara GPU ketika aktivasi dari satu GPU dipindahkan ke GPU lain.
- Paralelisme tensor
- Mendistribusikan dan memproses operasi tensor individu di seluruh perangkat atau prosesor yang berbeda.
- Berdasarkan pada gagasan bahwa operasi tensor yang besar, seperti perkalian matriks, dapat dibagi menjadi operasi tensor yang lebih kecil, dan setiap operasi yang lebih kecil dapat dieksekusi pada perangkat atau prosesor yang terpisah.
- Strategi paralelisme seperti itu secara inheren dibangun ke dalam implementasi standar PyTorch dan kerangka kerja pembelajaran dalam lainnya, tetapi menjadi lebih menonjol dalam pengaturan yang didistribusikan.
- Paralelisme data
- Mereplikasi model di seluruh GPU.
- Bagi data yang tersedia menjadi batch yang lebih kecil, dan setiap batch diproses oleh GPU yang terpisah.
- Pembaruan (atau gradien) dari setiap GPU kemudian diakumulasikan dan digunakan untuk memperbarui parameter model pada setiap GPU.
- Paralelisme pipa
Ini sering dianggap sebagai kombinasi dari paralelisme data dan paralelisme model.
Jadi masalah dengan paralelisme model standar adalah bahwa GPU pertama tetap tidak aktif ketika data sedang dipropagasi melalui lapisan yang tersedia di GPU kedua:
Paralelisme pipa menangani hal ini dengan memuat batch mikro-data berikutnya setelah GPU pertama selesai dengan perhitungan pada batch mikro-data pertama dan mentransfer aktivasi ke lapisan yang tersedia di GPU kedua.
Prosesnya terlihat seperti ini:
↳ Batch mikro-data pertama melewati lapisan pada GPU pertama.
↳ GPU kedua menerima aktivasi pada batch mikro-data pertama dari GPU pertama.
↳ Sementara GPU kedua melewati data melalui lapisan, batch mikro-data lain dimuat pada GPU pertama.
↳ Dan prosesnya berlanjut.
- Penggunaan GPU meningkat secara drastis dengan cara ini. Hal ini terlihat dari animasi di bawah di mana multi-GPU digunakan pada timestamp yang sama (lihat t=1, t=2, t=5, dan t=6).
Harap dicatat bahwa versi bahasa Indonesia didukung oleh AI dan karena itu mungkin terjadi kesalahan kecil.
Penulis
Ai Base Network (ABN), ABN ASIA didirikan oleh orang-orang dengan akar yang kuat di dunia akademis, dengan pengalaman kerja di Amerika Serikat, Belanda, Hungaria, Jepang, Korea Selatan, Singapura, dan Vietnam. ABN Asia adalah tempat di mana akademik dan teknologi bertemu dengan peluang. Dengan solusi terdepan kami dan layanan pengembangan perangkat lunak yang kompeten, kami membantu bisnis untuk meningkatkan level dan bersaing di panggung global. Komitmen kami: Lebih Cepat. Lebih Baik. Lebih handal. Dalam kebanyakan kasus: Lebih murah juga.
Jangan ragu untuk menghubungi kami jika Anda membutuhkan layanan IT, konsultasi digital, solusi perangkat lunak siap pakai, atau jika Anda ingin mengirimkan permintaan proposal (RFP). Anda dapat menghubungi kami di [email protected]. Kami siap membantu Anda dengan semua kebutuhan teknologi Anda.

© ABN ASIA