- Diterbitkan pada
Mengapa kita terus berbicara tentang token di LLM, bukan kata-kata?
- Penulis

- Nama
- AbnAsia.org
- @steven_n_t
"Mengapa kita terus berbicara tentang ""token"" di LLM, bukan kata-kata? Akan jauh lebih efisien jika memecah kata menjadi sub-kata (token) untuk performa model!
Strategi khas yang digunakan di sebagian besar LLM modern sejak GPT-1 adalah strategi Byte Pair Encoding (BPE). Idenya adalah menggunakan, sebagai token, unit sub-kata yang sering muncul dalam data pelatihan. Algoritmanya bekerja sebagai berikut:
Kita mulai dengan tokenisasi tingkat karakter
kami menghitung frekuensi pasangan
Kami menggabungkan pasangan yang paling sering
Kami ulangi prosesnya sampai kamusnya sebesar yang kami inginkan
Ukuran kamus menjadi hyperparameter yang bisa kita sesuaikan berdasarkan data pelatihan kita. Misalnya, GPT-1 memiliki ukuran kamus ~40K gabungan, GPT-2, GPT-3, dan ChatGPT memiliki ukuran kamus ~50K, dan Llama 3 128K."
Harap dicatat bahwa versi bahasa Prancis dari AI didukung dan karena itu mungkin terjadi kesalahan kecil. 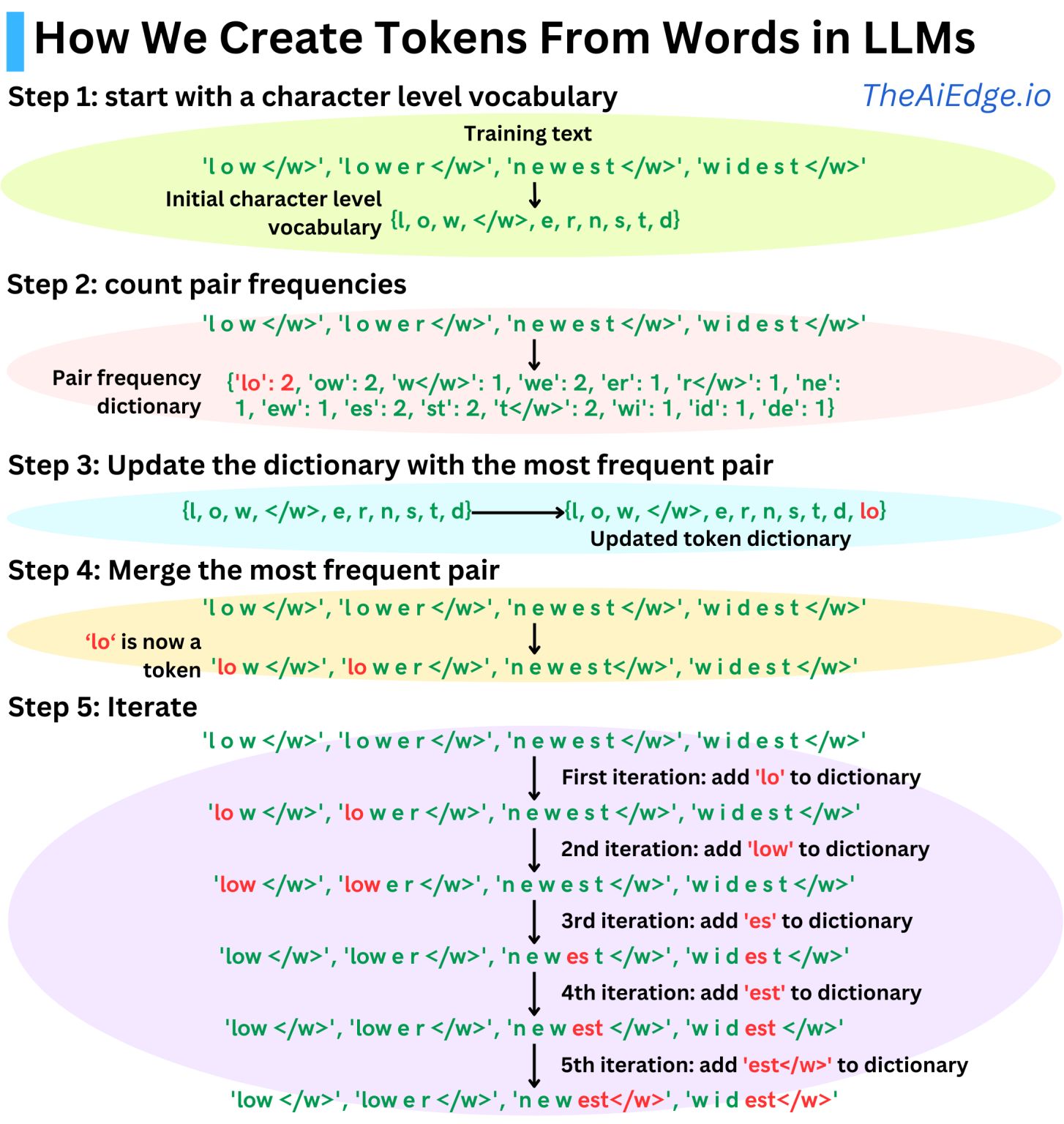
Penulis
Ai Base Network (ABN), ABN ASIA didirikan oleh orang-orang dengan akar yang kuat di dunia akademis, dengan pengalaman kerja di Amerika Serikat, Belanda, Hungaria, Jepang, Korea Selatan, Singapura, dan Vietnam. ABN Asia adalah tempat di mana akademik dan teknologi bertemu dengan peluang. Dengan solusi terdepan kami dan layanan pengembangan perangkat lunak yang kompeten, kami membantu bisnis untuk meningkatkan level dan bersaing di panggung global. Komitmen kami: Lebih Cepat. Lebih Baik. Lebih handal. Dalam kebanyakan kasus: Lebih murah juga.
Jangan ragu untuk menghubungi kami jika Anda membutuhkan layanan IT, konsultasi digital, solusi perangkat lunak siap pakai, atau jika Anda ingin mengirimkan permintaan proposal (RFP). Anda dapat menghubungi kami di [email protected]. Kami siap membantu Anda dengan semua kebutuhan teknologi Anda.

© ABN ASIA