- Diterbitkan pada
OpenAi O1: Tolok ukur yang sangat bagus
- Penulis

- Nama
- AbnAsia.org
- @steven_n_t
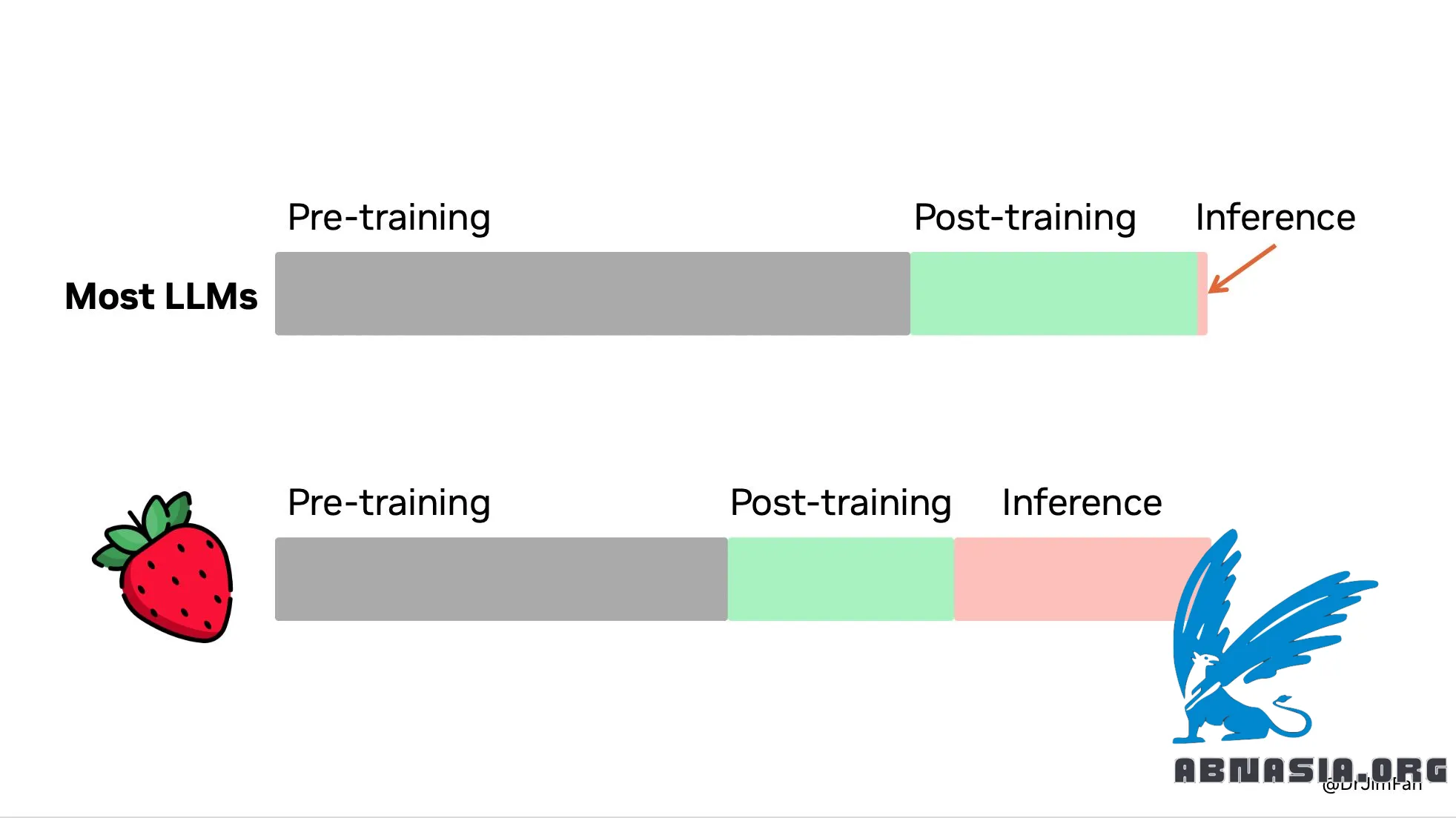
"OpenAI Stroberi (o1) sudah keluar! Kami akhirnya melihat paradigma penskalaan waktu inferensi dipopulerkan dan diterapkan dalam produksi. Seperti yang dikatakan Sutton dalam Pelajaran Pahit, hanya ada 2 teknik yang dapat diskalakan tanpa batas dengan komputasi: pembelajaran & penelusuran. Saatnya mengalihkan fokus ke hal terakhir.
Anda tidak memerlukan model yang besar untuk melakukan penalaran. Banyak parameter yang didedikasikan untuk menghafal fakta, agar dapat bekerja dengan baik dalam tolok ukur seperti trivia QA. Dimungkinkan untuk memfaktorkan penalaran dari pengetahuan, yaitu ""inti penalaran"" kecil yang mengetahui cara memanggil alat seperti browser dan pemverifikasi kode. Komputasi pra-pelatihan mungkin menurun.
Sejumlah besar komputasi dialihkan untuk menyajikan inferensi, bukan sebelum/pasca pelatihan. LLM adalah simulator berbasis teks. Dengan menerapkan banyak kemungkinan strategi dan skenario dalam simulator, model tersebut pada akhirnya akan menghasilkan solusi yang baik. Prosesnya adalah masalah yang dipelajari dengan baik seperti pencarian pohon monte carlo (MCTS) AlphaGo.
OpenAI pasti sudah mengetahui hukum penskalaan inferensi sejak lama, yang baru-baru ini ditemukan oleh akademisi. Dua makalah diterbitkan di Arxiv dengan selang waktu seminggu bulan lalu:
Monyet Bahasa Besar: Penskalaan Inferensi Komputasi dengan Pengambilan Sampel Berulang. Coklat dkk. menemukan bahwa DeepSeek-Coder meningkat dari 15,9% dengan satu sampel menjadi 56% dengan 250 sampel di SWE-Bench, mengalahkan Sonnet-3.5.
Penskalaan Komputasi Waktu Uji LLM Secara Optimal Bisa Lebih Efektif dibandingkan Parameter Model Penskalaan. Snell dkk. menemukan bahwa PaLM 2-S mengalahkan model 14x lebih besar pada MATEMATIKA dengan penelusuran waktu pengujian.
Memproduksi o1 jauh lebih sulit daripada memenuhi standar akademis. Untuk mengatasi masalah di alam liar, bagaimana memutuskan kapan harus berhenti mencari? Apa fungsi hadiahnya? Kriteria keberhasilan? Kapan memanggil alat seperti penerjemah kode di loop? Bagaimana cara memperhitungkan biaya komputasi dari proses CPU tersebut? Postingan penelitian mereka tidak banyak berbagi.
Stroberi dengan mudah menjadi roda gila data. Jika jawabannya benar, seluruh jejak pencarian menjadi kumpulan data mini berisi contoh pelatihan, yang berisi imbalan positif dan negatif.
Hal ini pada gilirannya meningkatkan inti penalaran untuk versi GPT masa depan, mirip dengan bagaimana jaringan nilai AlphaGo - yang digunakan untuk mengevaluasi kualitas setiap posisi dewan - meningkat seiring MCTS menghasilkan data pelatihan yang lebih banyak dan lebih baik."
Harap dicatat bahwa versi bahasa Indonesia didukung oleh AI dan karena itu mungkin terjadi kesalahan kecil.
Penulis
Ai Base Network (ABN), ABN ASIA didirikan oleh orang-orang dengan akar yang kuat di dunia akademis, dengan pengalaman kerja di Amerika Serikat, Belanda, Hungaria, Jepang, Korea Selatan, Singapura, dan Vietnam. ABN Asia adalah tempat di mana akademik dan teknologi bertemu dengan peluang. Dengan solusi terdepan kami dan layanan pengembangan perangkat lunak yang kompeten, kami membantu bisnis untuk meningkatkan level dan bersaing di panggung global. Komitmen kami: Lebih Cepat. Lebih Baik. Lebih handal. Dalam kebanyakan kasus: Lebih murah juga.
Jangan ragu untuk menghubungi kami jika Anda membutuhkan layanan IT, konsultasi digital, solusi perangkat lunak siap pakai, atau jika Anda ingin mengirimkan permintaan proposal (RFP). Anda dapat menghubungi kami di [email protected]. Kami siap membantu Anda dengan semua kebutuhan teknologi Anda.

© ABN ASIA