- Diterbitkan pada
Percepat Inferensi LLM dengan Dekoding Spekulatif
- Penulis

- Nama
- AbnAsia.org
- @steven_n_t
Ingat MSN Messenger?
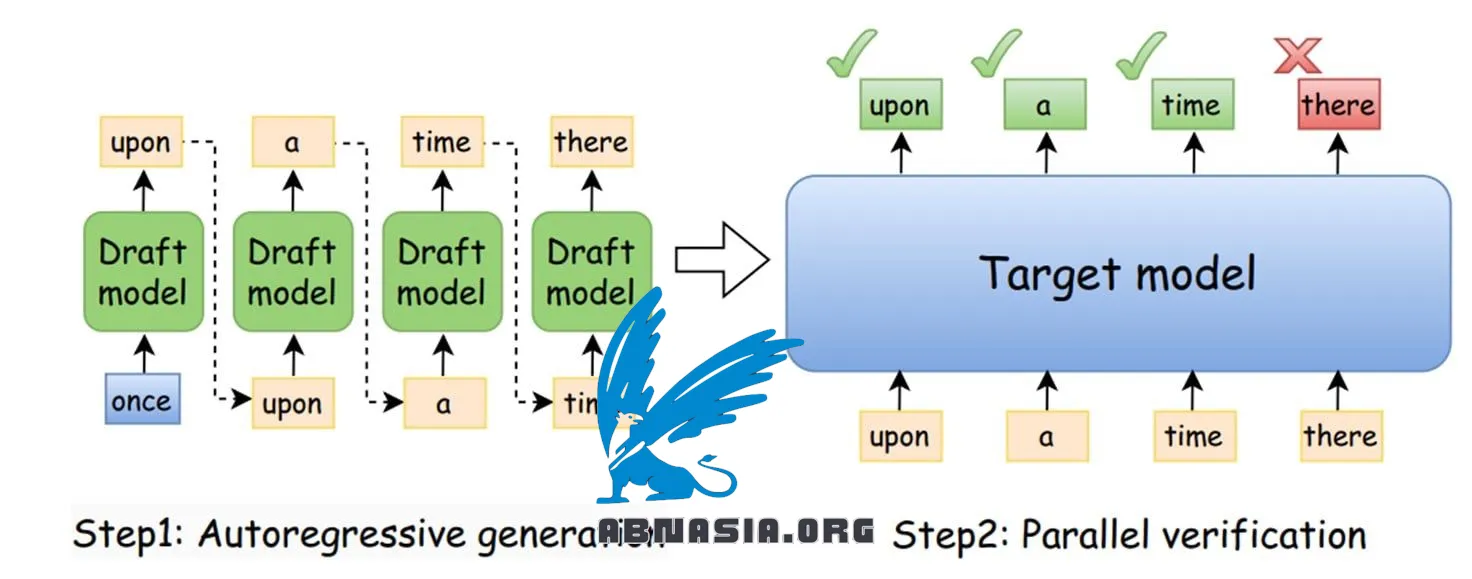
Apa itu Speculative Decoding?
Ini adalah teknik yang menggunakan model draft (SLM) untuk bekerja bersama dengan LLM utama:
1️⃣ Model draft memprediksi K token berikutnya.
2️⃣ LLM utama memverifikasi dan memperbaiki jika diperlukan.
3️⃣ Jika ada ketidakcocokan, LLM melanjutkan urutan, dan model draft memulai ulang dengan input yang diperbarui.
Mengapa Ini Berfungsi:
• Hingga 3x lebih cepat untuk penyelesaian kode.
• Hingga 2x lebih cepat untuk ringkasan, generasi teks, dan instruksi.
Model Draft Pra-Latih:
• Llama-3.1-8B-FastDraft-150M
• Phi-3-mini-FastDraft-50M
Mengapa Ini Penting:
Ini membuat LLM lebih cepat, lebih efisien, dan siap untuk tugas dunia nyata.
Harap dicatat bahwa versi bahasa Indonesia didukung oleh AI dan karena itu mungkin terjadi kesalahan kecil.
Penulis
Ai Base Network (ABN), ABN ASIA didirikan oleh orang-orang dengan akar yang kuat di dunia akademis, dengan pengalaman kerja di Amerika Serikat, Belanda, Hungaria, Jepang, Korea Selatan, Singapura, dan Vietnam. ABN Asia adalah tempat di mana akademik dan teknologi bertemu dengan peluang. Dengan solusi terdepan kami dan layanan pengembangan perangkat lunak yang kompeten, kami membantu bisnis untuk meningkatkan level dan bersaing di panggung global. Komitmen kami: Lebih Cepat. Lebih Baik. Lebih handal. Dalam kebanyakan kasus: Lebih murah juga.
Jangan ragu untuk menghubungi kami jika Anda membutuhkan layanan IT, konsultasi digital, solusi perangkat lunak siap pakai, atau jika Anda ingin mengirimkan permintaan proposal (RFP). Anda dapat menghubungi kami di [email protected]. Kami siap membantu Anda dengan semua kebutuhan teknologi Anda.

© ABN ASIA