- 公開日
チャットボットランキング:異なるタスク、異なる勝者
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
Chatbot Arenaが、数学やコーディング、創作的な文章などのカテゴリ別の評価やスタイル調整を公開していることはあまり知られていません。
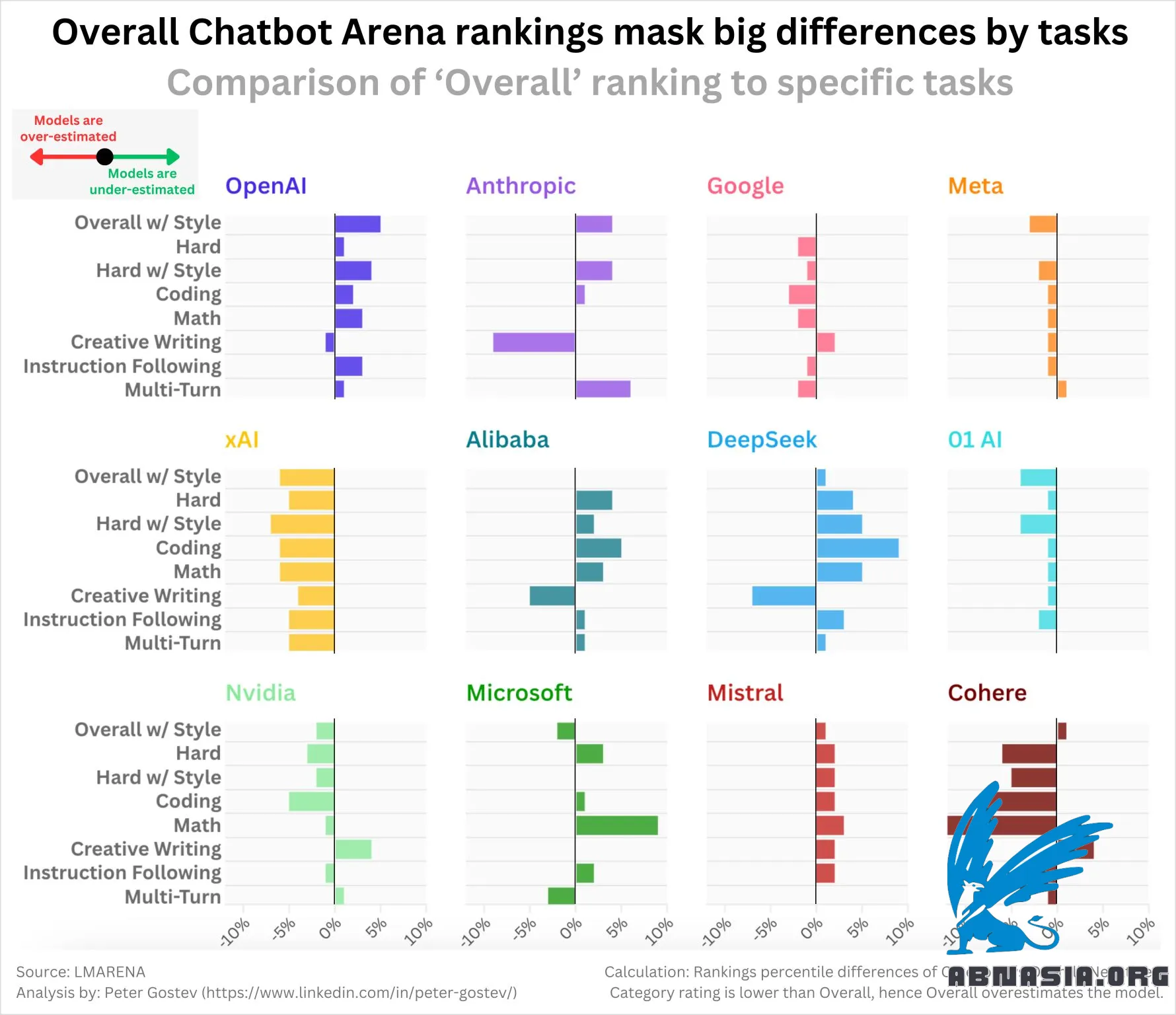
モデルが特定のタスクに対してどのような「核となる」パフォーマンスを示すかを確認できることになる。
私は、特定のラボがさまざまなタスクに対して「総合」評価で過小評価または過大評価される傾向があるかどうかを調査したかった。結果は正直、期待していたものとは違った。
OpenAIのモデルはほとんど過小評価されている(つまり、個々の評価を見ると強い)
xAI、Google、Meta、01(ラボ、モデルではない)、Cohere、Nvidiaはすべて過大評価されている
DeepSeek、Mistral、Alibaba(Qwenモデル)は過小評価されている
Anthropicは混合 - 創造的な文章の過大評価は興味深い
ヒントとして、最も優れたモデルを確認したい場合は、「ハードスタイルコントロール」を見てみることをお勧めします - そこではSonnet 3.6、o1-preview、Google-Exp-1121が並んで1位で、自分の直感に合った最も優れたモデルをよりよく表している。
注:日本語の翻訳では、原文の意味をできるだけ保つようにしましたが、文の構造や表現を少し変更する必要がありました。
日本語版は Ai 支援を使用しているため、小さな間違いが存在する可能性があることをご了承ください。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私たちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA