- 公開日
大規模言語モデルはどのように機能するのか?
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
以下の図は、LLMのコアアーキテクチャを示している。
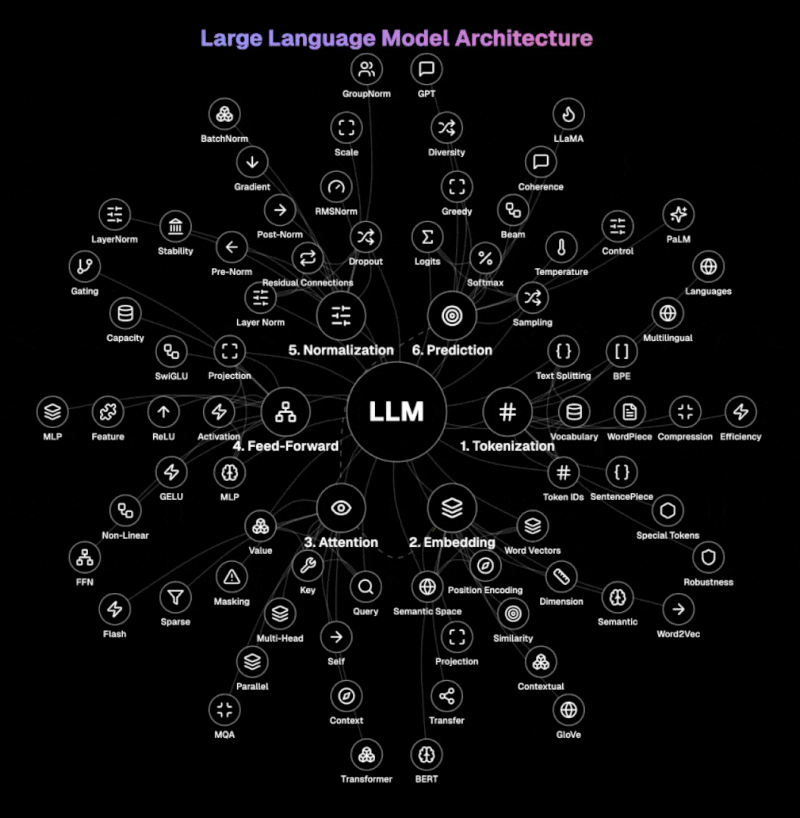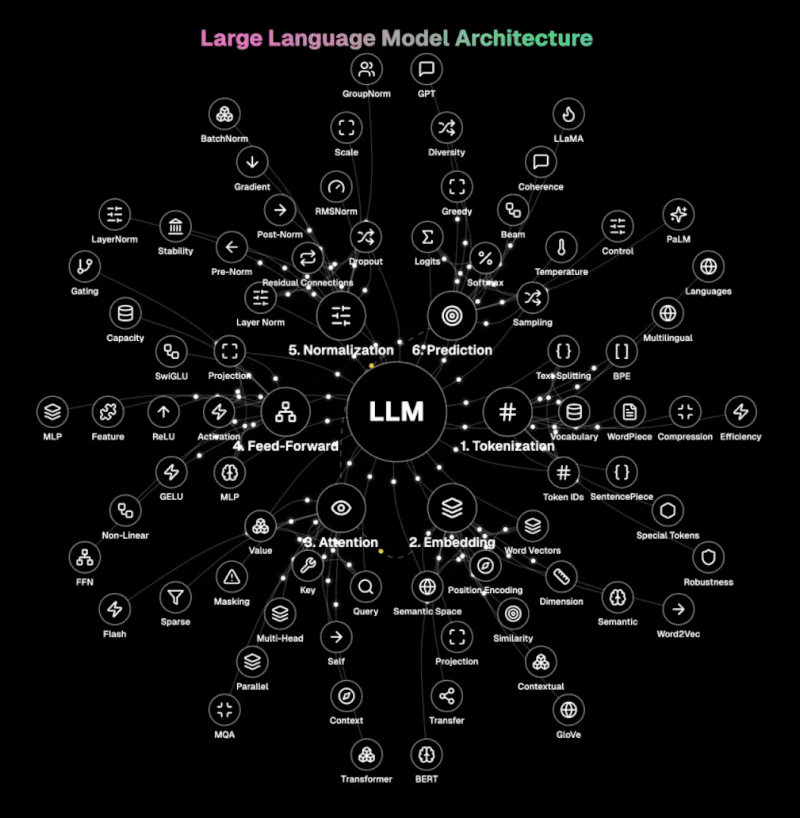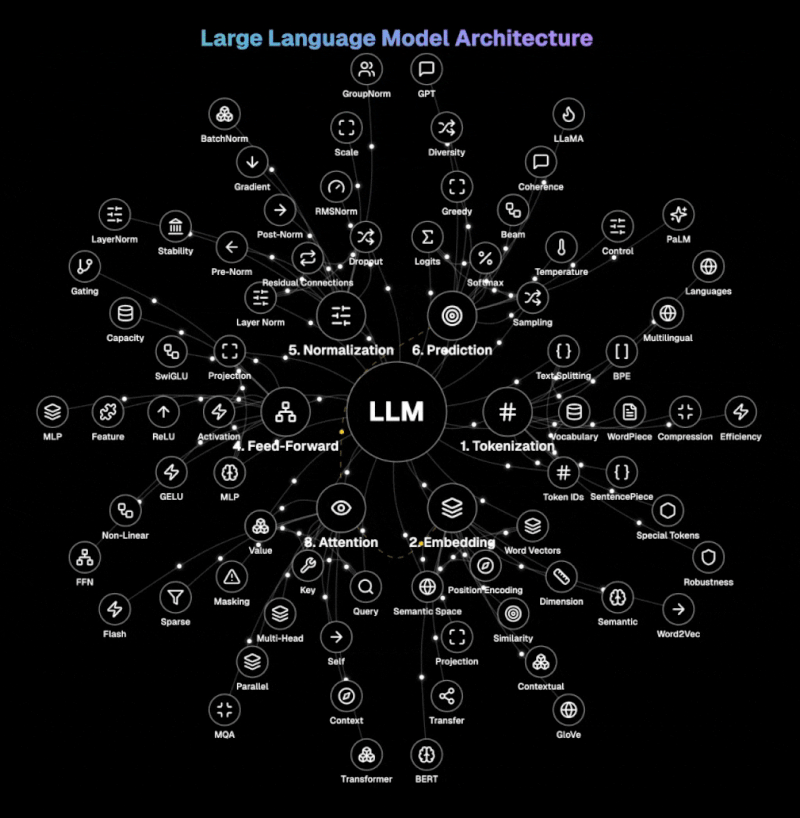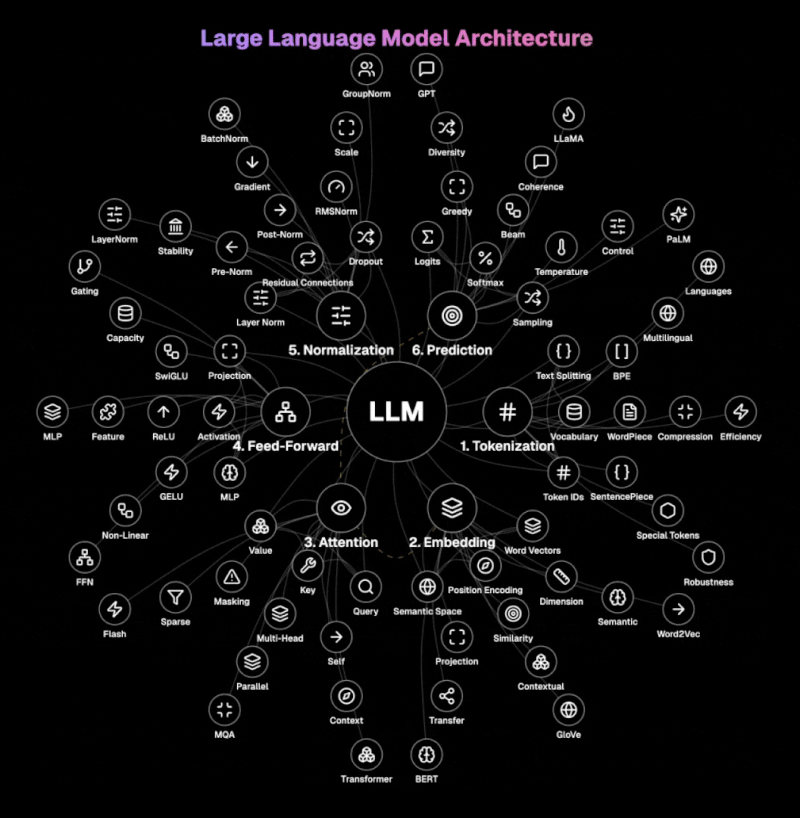
ステップ 1: トークン化 LLM は、テキストを処理可能な単位であるトークンに分割します。BPE、WordPiece、または SentencePiece などのテクニークを使用して、単語、サブワード、または文字を処理します。このプロセスにより、自然言語はモデルが処理できるトークン ID に変換され、特殊トークンはテキスト内の開始、終了、または特殊な機能をマークします。語彙サイズとトークン圧縮テクニークは、効率的な処理に重要です。
ステップ 2: 埋め込み この層は、離散的なトークン ID を高次元の意味空間における豊富なベクトル表現に変換します。単語ベクトルと位置情報を組み合わせてシーケンス情報を保存します。埋め込みマトリックスは、単語間の意味関係を捉え、類似した概念がベクトル空間内で近くに存在できるようにします。
ステップ 3: 注意 近代的な LLM の核である注意は、出力トークンを生成する際に、入力のどの部分に焦点を当てるかを決定します。クエリ、キー、値ベクトルを使用して、シーケンス内のすべてのトークン間の関連性スコアを計算します。マルチヘッド注意は、さまざまな表現サブ空間を並列に処理して、さまざまな関係を同時に捉えます。セルフ注意により、モデルは各トークンを処理する際に、全体のコンテキストを考慮できます。
ステップ 4: フィードフォワード このコンポーネントは、多層パーセプトロン (MLP) を介して、各トークンの表現を独立して変換します。GELU または ReLU などの非線形活性化関数を適用して、データ内の微妙なパターンを捉える複雑さを導入します。フィードフォワード ネットワークは、複雑な関数と関係を表現するモデルの能力を高めます。各トークンの表現を個別に処理して、注意メカニズムのコンテキスト処理を補完します。
ステップ 5: 正規化 レイヤー正規化は、機能間で入力を標準化しますが、残差接続により、情報がネットワークを直接流れることができます。事前正規化と事後正規化アーキテクチャは、安定性とパフォーマンスのトレードオフを提供します。ドロップアウトは、トレーニング中にランダムにニューロンを無効にすることで過学習を防ぎ、モデルが冗長な表現を開発することを強制します。
ステップ 6: 予測 最終的なステップでは、処理された表現を語彙上の確率に変換します。各可能な次のトークンのロジット (生のスコア) を生成し、ソフトマックス関数を使用して確率に変換します。温度サンプリングは、生成におけるランダム性を制御し、低い温度ではより決定的な出力が生成されます。貪欲、ビーム検索、または核サンプリングなどのデコーディング戦略は、モデルが生成中にトークンを選択する方法を決定します。
LLM を従来の言語処理システムと異なるものにするのは、その自己回帰的な性質です。これにより、ステップバイステップの生成プロセスが作成され、すべての応答を一度に生成するのではなく、生成されます。
あなたの見解では、LLM のどのアーキテクチャ コンポーネントが幻覚を引き起こしますか。
日本語版は Ai 支援を使用しているため、小さな間違いが存在する可能性があることをご了承ください。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私ちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA