- 公開日
データベースを使用して LLM を拡張するのは素晴らしいことですが、そのアプローチには大きな欠陥があります。
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
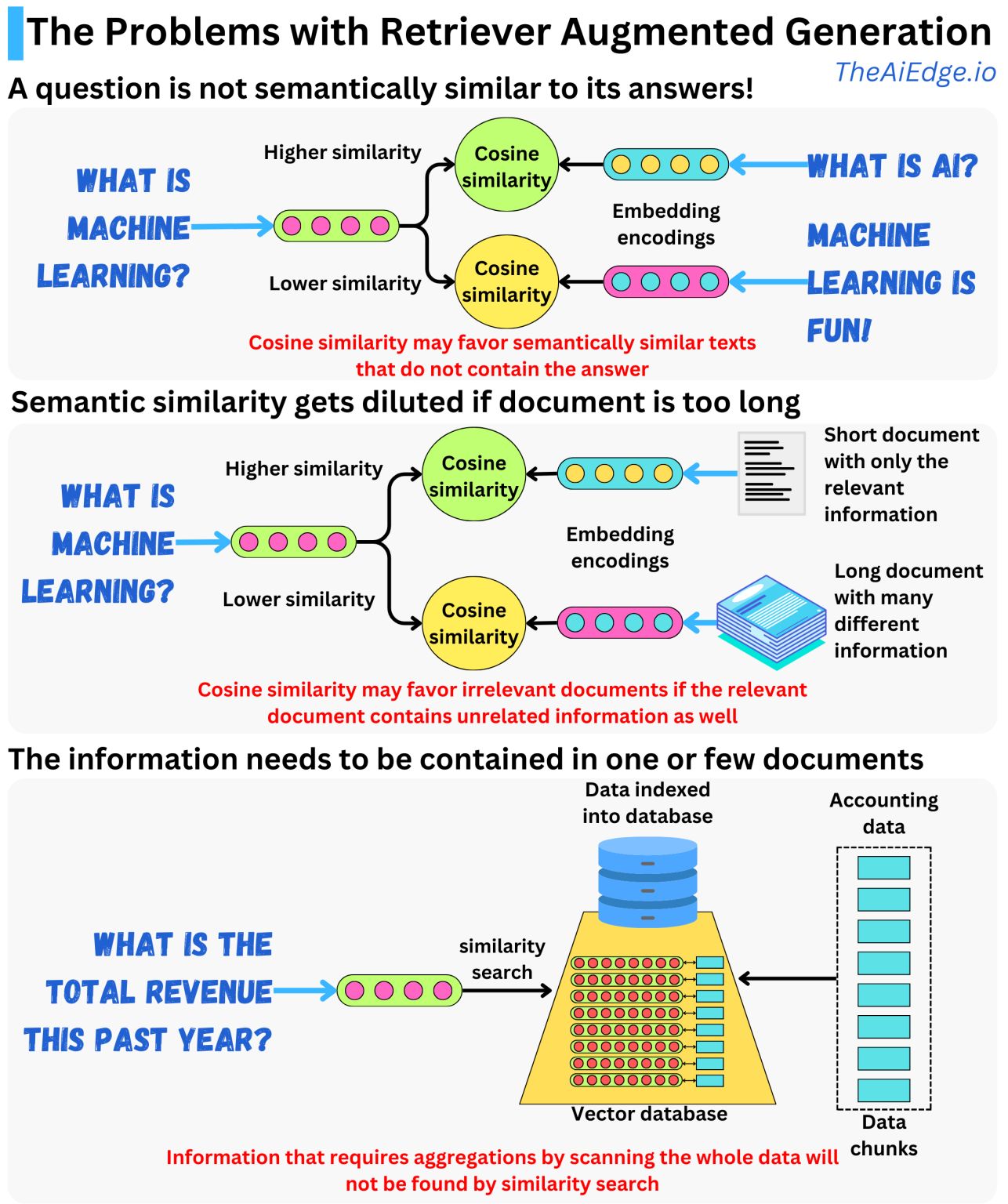
RAG の考え方は、LLM に公開するデータをエンコードして埋め込みにし、そのデータをベクトル データベースにインデックス付けすることです。 ユーザーが質問すると、それはエンベディングに変換され、それを使用してデータベース内で同様のエンベディングを検索できます。 同様の埋め込みが見つかったら、関連データを使用してプロンプトを構築し、LLM が質問に答えるためのコンテキストを提供します。 ここでの類似性は通常、コサイン類似性メトリックを使用して測定されます。
最初の問題は、通常、質問はその回答と意味的に類似していないことです。 少なくとも、質問と同じ単語を含む文書や、質問に答えるための関連情報を提供せずに同じ文脈で使用される文書を検索で取得することは可能です。 検索では質問に最も類似したドキュメントが取得されるため、データによっては、無関係なドキュメントが多すぎると、実際に回答を含むドキュメントよりも高いコサイン類似度が示される場合があります。
公平を期すために言うと、コサイン類似性が高いということは、トランスフォーマーとの意味上の類似性に正確に変換されるわけではありません。 コサイン類似性が高いと、トレーニング データの同じサブテキスト内の 2 つの異なる用語の高度な共起も捕捉できます。これは、特定の質問とそれに関連する回答でよく起こります。
別の問題は、データのインデックス付け方法に関連している可能性があります。 データが大きなテキストの塊に分割されている場合、各塊の中に複数の異なる関連性のない情報が含まれる可能性があります。 そのデータに対して類似性検索を実行すると、関連情報が希薄になり、代わりに無関係なドキュメントが検索で返される可能性があります。 各テキストで展開される概念の「独自性」を高めるために、各チャンクに含まれる段落が数個以下になるようにデータを分割することが重要です。
RAG アプローチでは、LLM に尋ねる質問の種類を制限することが非常に重要です。 データベース全体のデータを集約する必要がある質問をした場合、答えは間違っている可能性が高くなりますが、LLM はそれを知ることができません。 適切な情報が 1 つまたは少数のドキュメントにローカルにある場合は、類似性検索で見つかる可能性があります。 ただし、答えを見つけるためにすべてのドキュメントをスキャンする必要がある情報の場合、類似性検索では見つけられません。 それぞれの文書に日付が付いていると想像してください。「最も古い文書は何ですか?」と尋ねます。 その場合、データベース全体をスキャンする場合にのみ答えを知ることができ、類似性検索は役に立ちません。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私たちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA