- 公開日
機械学習: 専門家の混合アーキテクチャ
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
最近では、まばたきするだけで、20 の新しい機械学習テクニックやツールについて学ぶ必要があります。 Mixture of Experts アーキテクチャは決して新しい手法ではありませんが、現在では LLM をスケーリングするためのデフォルトの戦略となっています。私は数年前にそれについて読んだとき、「おそらく重要ではないまた別の LLM 論文」として却下したことを覚えています。さて、今が重要です!ほとんどの大規模な LLM は、今後その戦略を使用する可能性があります。
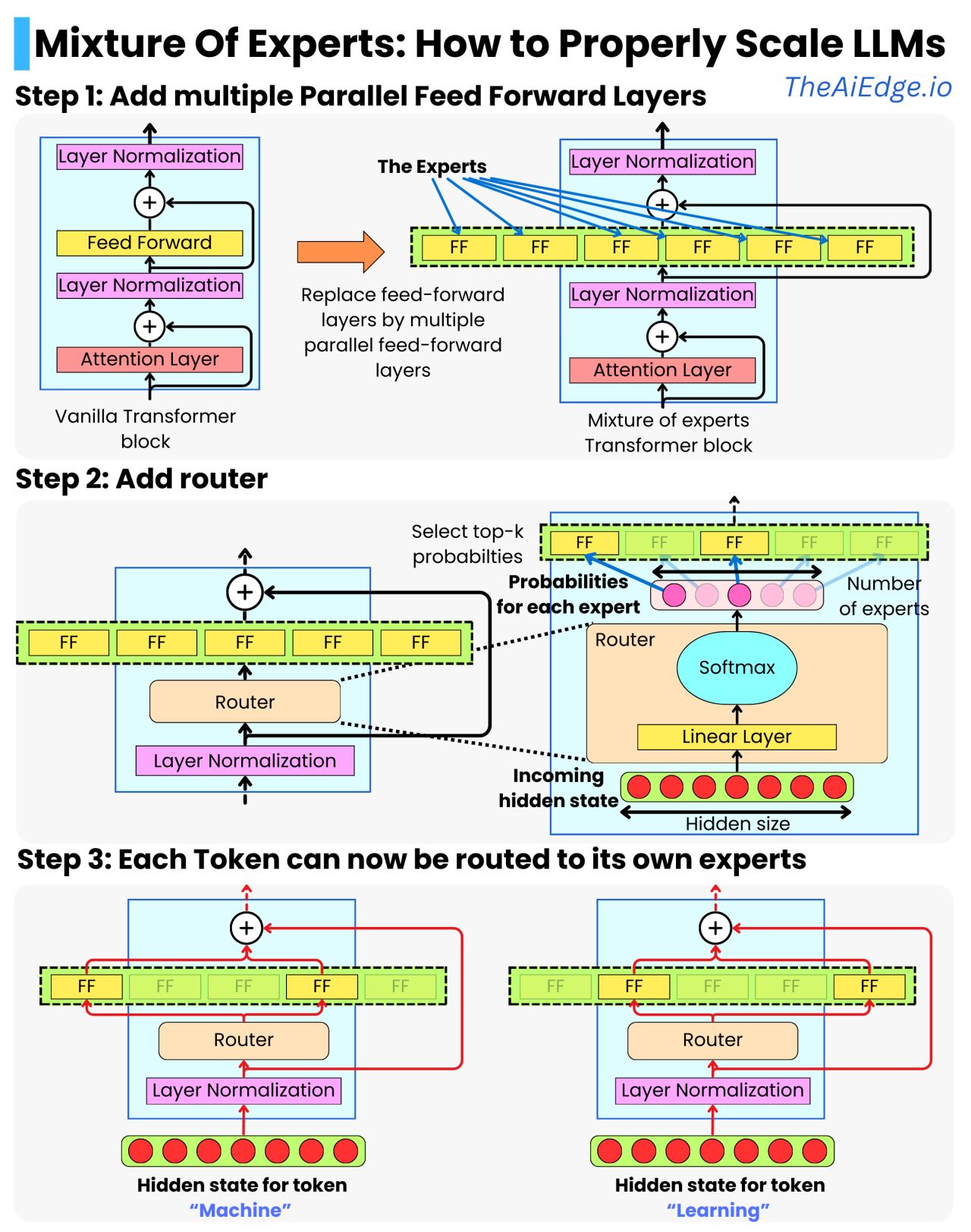
一般的なトランスフォーマー ブロックは、注目層、正規化層、フィードフォワード層、および別の層の正規化が連続したものです。変圧器を拡張する戦略は、変圧器ブロックを次々に追加することでした。 MoE のアイデアは、各ブロックに並列フィードフォワード レイヤーをさらに追加することで「水平に」スケーリングすることです。それが「専門家」なのです。
エキスパート層の前にルーターを追加して、各トークンが少数のエキスパートのみを通過するようにします。たとえば、64 人の専門家を配置できますが、トークンの非表示状態はそのうちの 2 つだけを通過します。これにより、計算負荷、つまり推論時のレイテンシを最小限に抑えながら、多様な学習が保証されます。
ルーターは、隠れ状態を取得し、エキスパートの数と同じ数のエントリを含むベクトルを生成する単なる線形層です。ソフトマックス変換を使用すると、各エキスパートの確率が得られます。これらの確率を使用して上位 k 個の専門家を選択し、選択した専門家の出力の加重平均を構築できるようになりました。たとえば、上位 2 人の専門家を取り上げると、次のようになります。
新しい状態 = P(FFN_1) * FFN_1 (非表示状態) + P(FFN_2) * FFN_2 (非表示状態)
上位 2 人のエキスパートだけを使用した場合でも、新しい出力の非表示状態は、エキスパートのさまざまな組み合わせによって学習された、より豊富な情報セットを表すことができます。これにより、モデルの計算を複数の GPU マシンに分散する非常に自然な方法も提供されます。各マシンは複数のエキスパートを保持でき、異なるエキスパートの計算は異なるマシン上で並行して実行できます。
ただし、MoE モデルのトレーニングはトレーニングの不安定性を多く引き起こすため、簡単ではありません。 1 つの困難は、各専門家が関連する統計パターンを学習するのに十分なデータを確実に参照できるようにすることです。典型的な戦略は、損失関数に項を追加して、専門家間でバランスのとれたデータ負荷を提供することです。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私たちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA