- 公開日
LLM の推論を高速化するための推測的デコーディング
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
MSNメッセンジャーを覚えていますか?
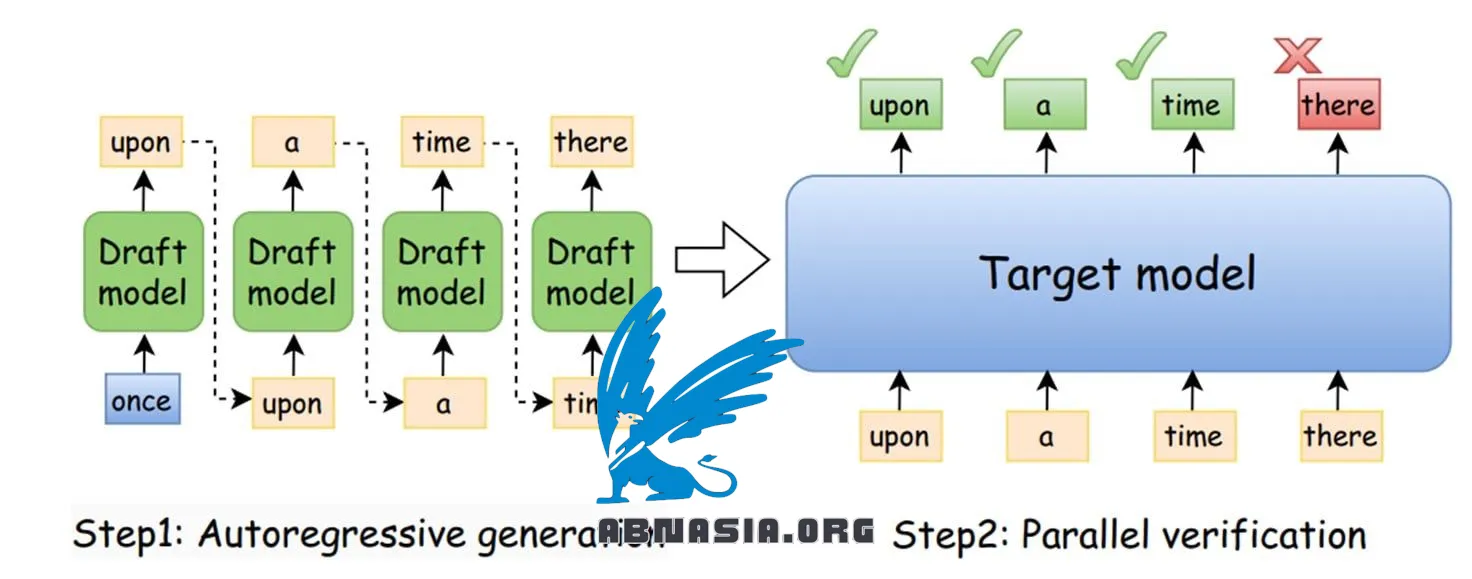
推測的デコーディングとは?
これは、メインのLLMと共に動作するドラフトモデル(SLM)を使用するテクニックです。
1.ドラフトモデルは、次のK個のトークンを予測します。
2.メインのLLMは、必要に応じてそれらを検証および修正します。
3.一致しない場合は、LLMはシーケンスを続け、ドラフトモデルは更新された入力を使用して再開します。
なぜ効果的か:
• コードの補完では、最大3倍高速化。
• 要約、テキスト生成、指示文の生成では、最大2倍高速化。
事前トレーニングされたドラフトモデル:
• Llama-3.1-8B-FastDraft-150M
• Phi-3-mini-FastDraft-50M
なぜ重要か:
これにより、LLMは高速化、効率化され、実世界のタスクに適したものになります。
日本語版は Ai 支援を使用しているため、小さな間違いが存在する可能性があることをご了承ください。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私たちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA