- 公開日
マルチGPUトレーニングの4つの戦略をビジュアルで解説。
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
デフォルトでは、深層学習モデルは複数のGPUが利用可能であっても、トレーニングに単一のGPUのみを利用します。ここではその回避策を示します。
大規模データセットを扱う場合、トレーニングのワークロードを複数のGPUに分散させることが理想的です。
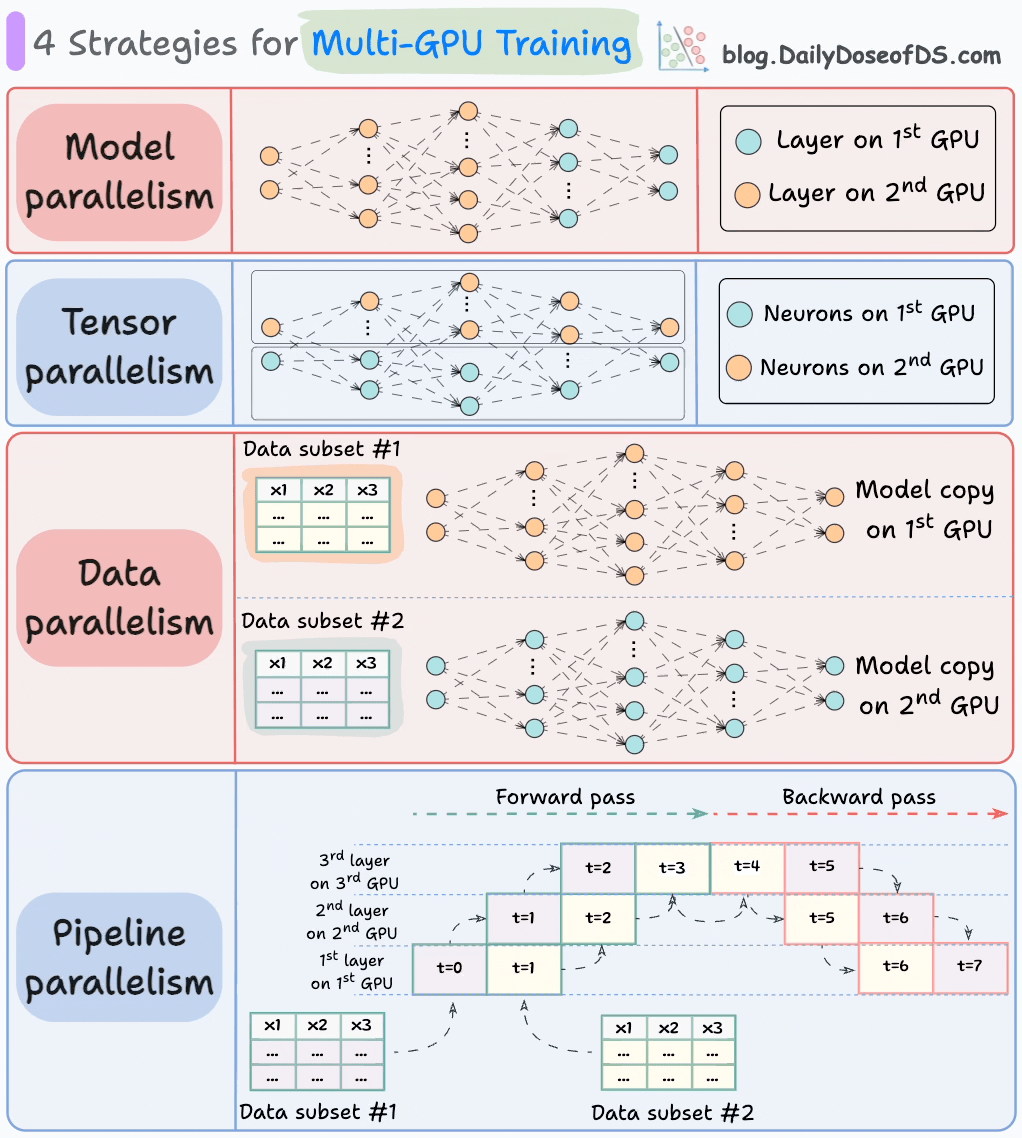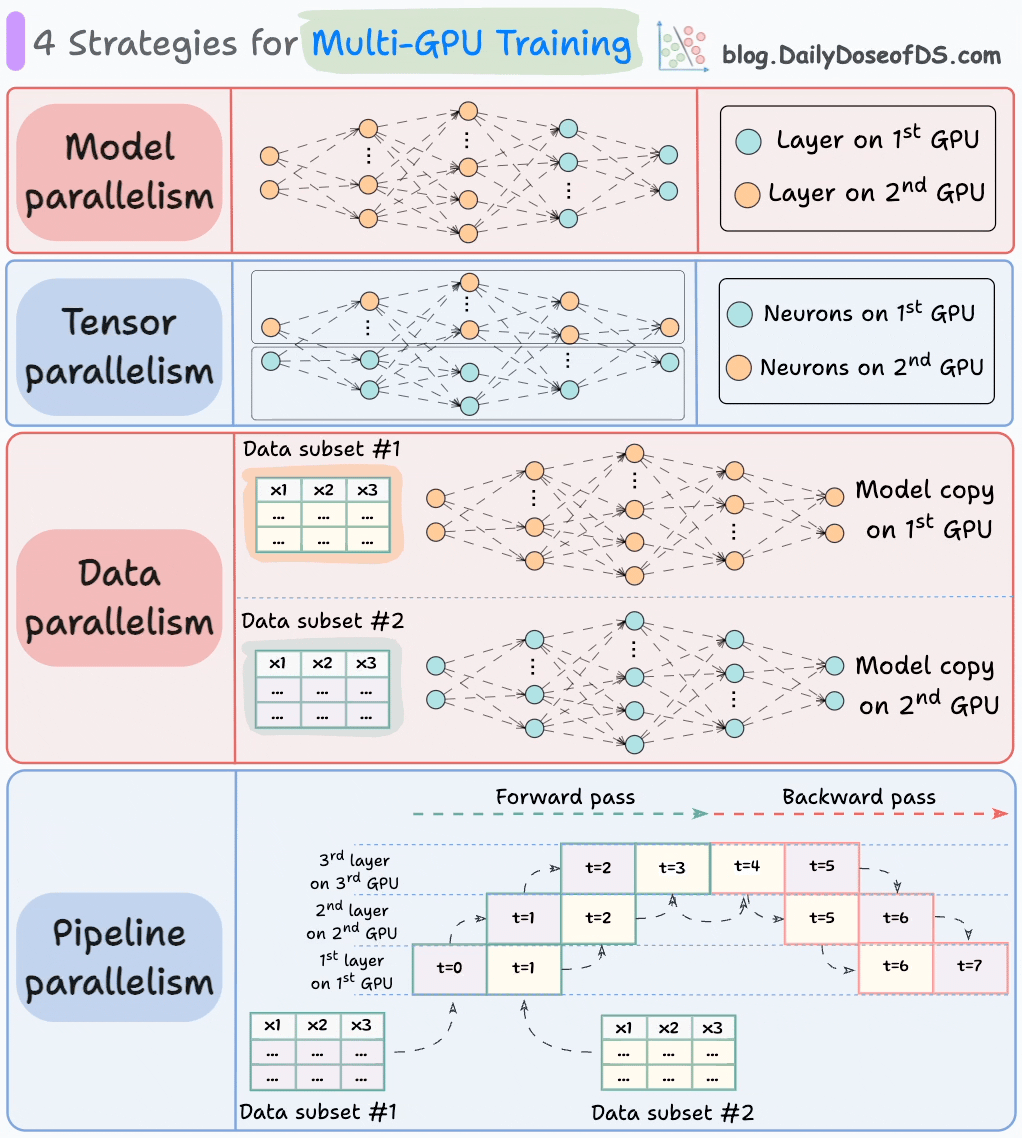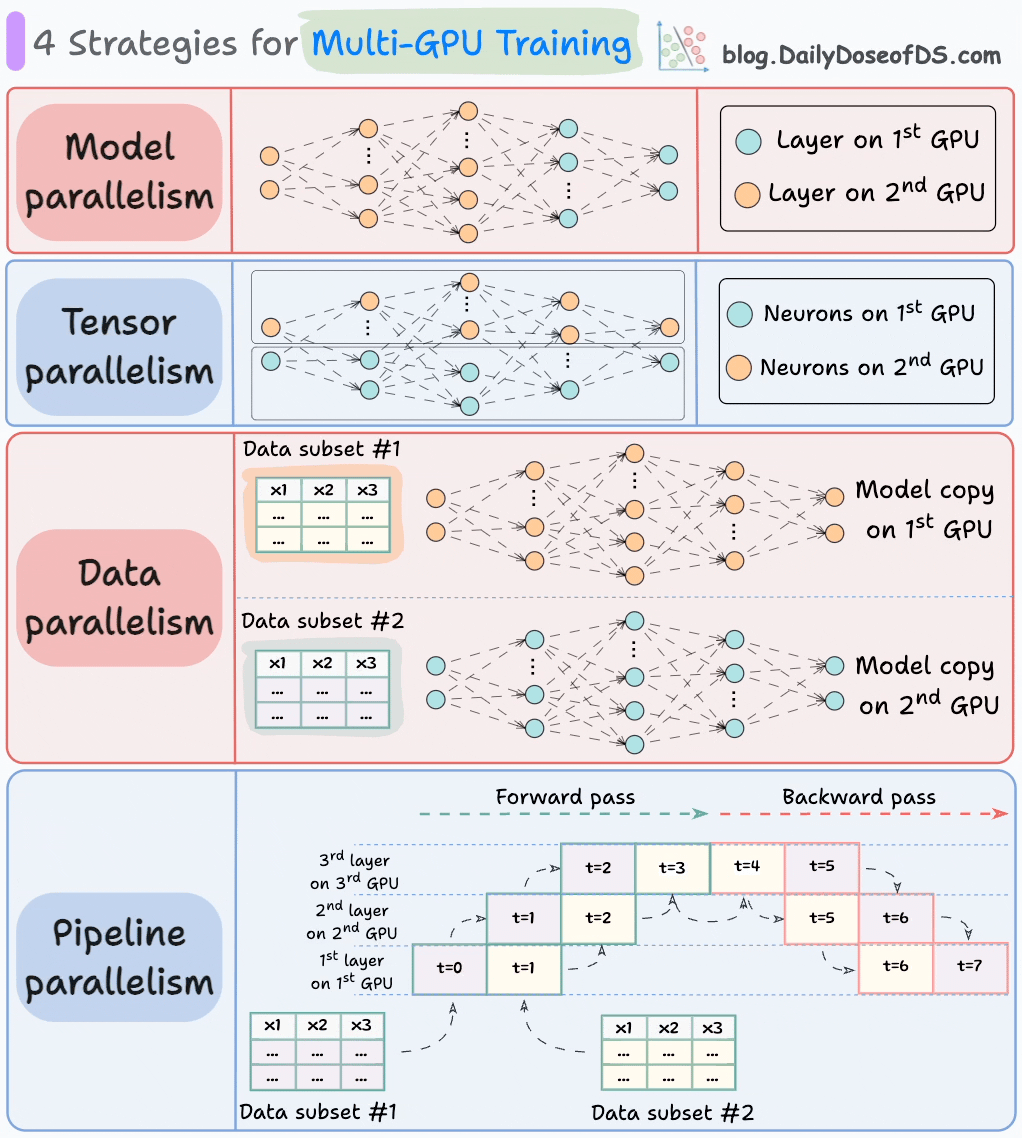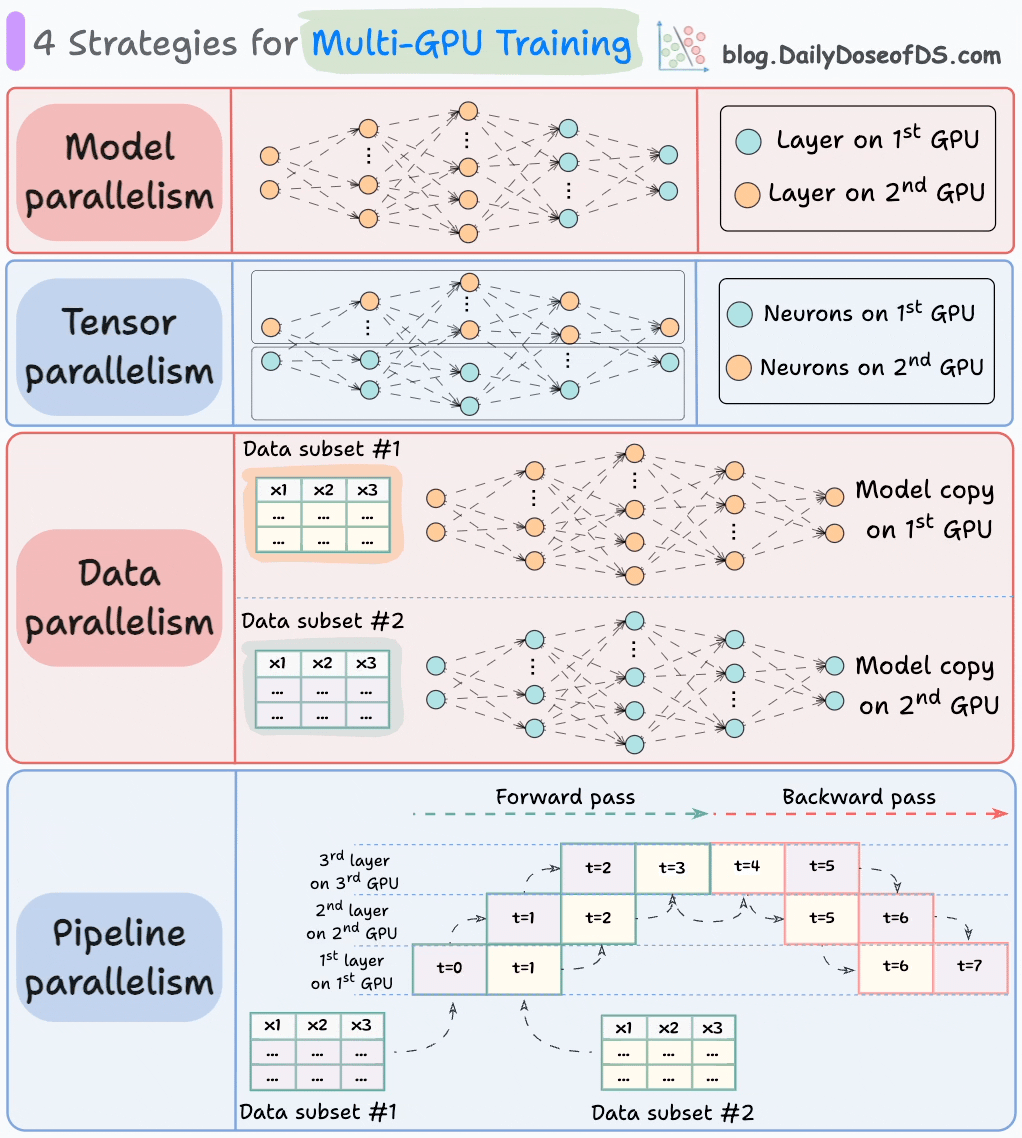
以下の図は、多GPUトレーニングの4つの一般的な戦略を示しています。
- モデル並列化
- モデルを複数のGPUに分割して配置します。
- 1つのGPUに収まりきらない巨大なモデルに有効です。
- ただし、モデル並列化は、GPU間でデータをやり取りする必要があるため、ボトルネックを引き起こします。
- テンソル並列化
- 個々のテンソル演算を複数のデバイスまたはプロセッサに分散して処理します。
- 大規模なテンソル演算(例:行列乗算)を小さなテンソル演算に分割し、それぞれの小さな演算を別のデバイスまたはプロセッサで実行するという考えに基づいています。
- これらの並列化戦略は、PyTorchなどの深層学習フレームワークの標準的な実装に組み込まれていますが、分散環境ではさらに強調されます。
- データ並列化
- モデルをすべてのGPUに複製します。
- データを小さなバッチに分割し、それぞれのバッチを別のGPUで処理します。
- 各GPUからの更新(または勾配)を集約し、すべてのGPUでモデルパラメータを更新します。
- パイプライン並列化
データ並列化とモデル並列化の組み合わせと見なされることが多いです。
標準的なモデル並列化の問題は、最初のGPUが2番目のGPUにある層にデータを伝播するときにアイドル状態になることです。
パイプライン並列化は、最初のGPUが最初のマイクロバッチの計算を完了し、2番目のGPUにある層にアクティベーションを転送した後、次のマイクロバッチをロードすることでこの問題に対処します。
プロセスは次のようになります。
↳ 最初のマイクロバッチは、最初のGPUにある層を通過します。
↳ 2番目のGPUは、最初のマイクロバッチのアクティベーションを受け取ります。
↳ 2番目のGPUがデータを層を通過させるときに、別のマイクロバッチが最初のGPUにロードされます。
↳ このプロセスは続きます。
- このようにして、GPUの利用率が大幅に改善されます。これは、以下のアニメーションで明らかです。ここでは、同じタイムスタンプで複数のGPUが利用されています(t=1、t=2、t=5、t=6を参照)。
日本語版は Ai 支援を使用しているため、小さな間違いが存在する可能性があることをご了承ください。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私たちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA