- 公開日
マシンラーニングモデル: モデル圧縮方法
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
なぜなら、彼らは今やあまりにも大きくなってしまったからだ。
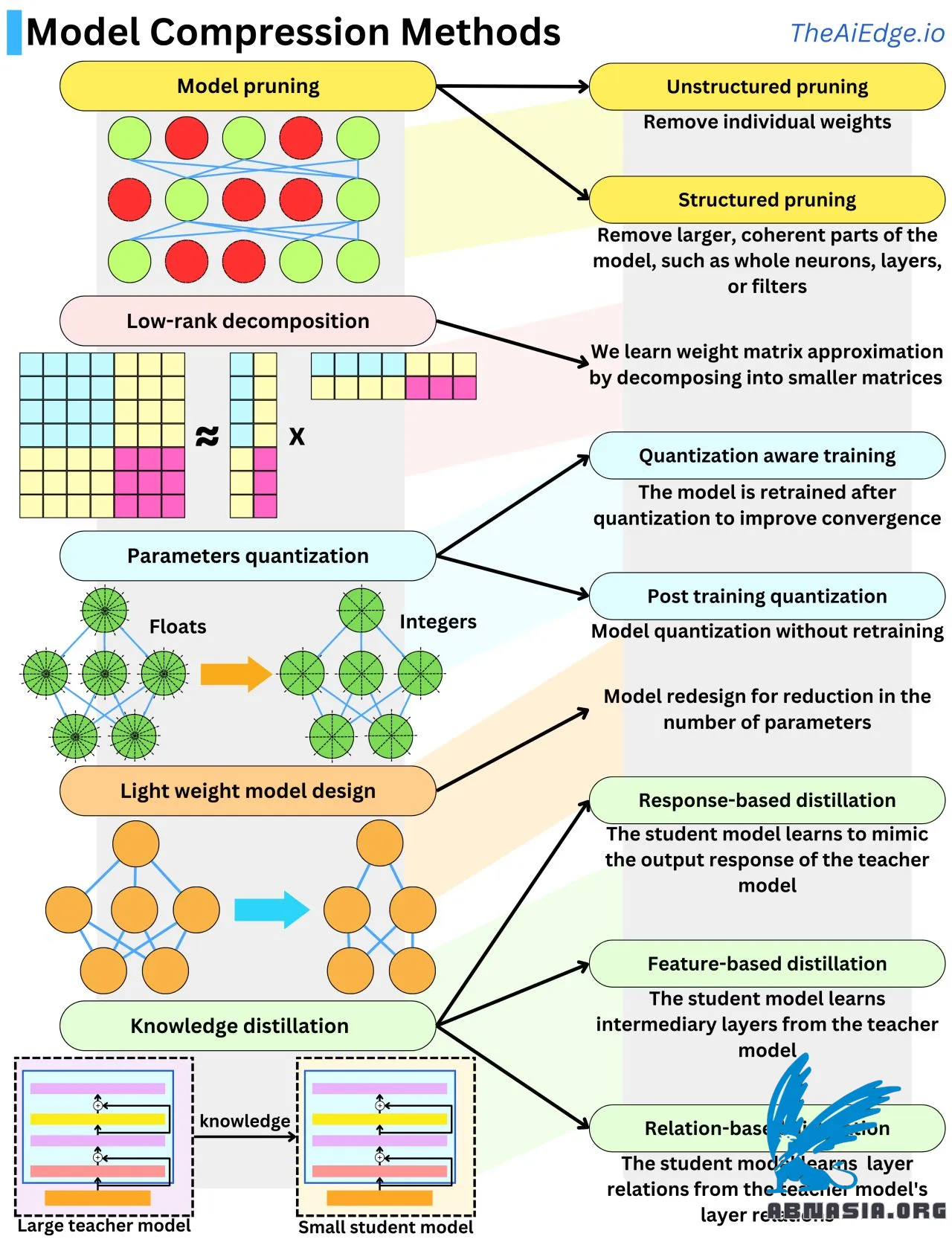
最近では、多くの人が扱う機械学習モデルの最大のものは、メモリサイズが数GB程度にしか達していませんでした。しかし、現在では、新しい生成モデルはすべて、1Bから1Tのパラメータを持つものが続々と出てきています。規模の把握のために、1つの浮動小数点パラメータは、32ビットまたは4バイト(Float16の場合は2バイト)なので、新しいモデルはそれぞれ、メモリサイズが4GBから4TBの範囲に及ぶ可能性があり、各モデルは高価なハードウェアで動作しています。また、逆伝播アルゴリズムの際には、これらのモデルは、10倍のメモリを必要とする場合があります。規模の増加が著しいことから、モデルサイズを削減しながらパフォーマンスを維持するための研究が多く行われてきました。モデルサイズを圧縮するための主な手法は5つあります。
モデルプルーニングは、ネットワークから重要でない重みを削除することです。ゲームは、「重要」という意味をその文脈で理解することです。典型的なアプローチは、各重みの損失関数への影響を測定することです。これは、損失関数の勾配と2次導関数を調べることで簡単に実行できます。別の方法は、L1またはL2正則化を使用して、低い大きさの重みを削除することです。ニューロン、層、またはフィルタの全体を削除することを「構造化プルーニング」と呼び、推論速度の向上に際してはより効率的です。
モデル量子化は、パラメータの精度を低下させることです。通常は、浮動小数点(32ビット)から整数(8ビット)に移行します。これは、4倍のモデル圧縮です。パラメータを量子化すると、モデルは収束点から逸脱する傾向があります。したがって、追加のトレーニングデータで微調整することで、モデルパフォーマンスを維持することが一般的です。これを「量子化対応トレーニング」と呼びます。この最後のステップを省略すると、「後処理量子化」と呼ばれ、パフォーマンスを助けるために、重みに対して追加のヒューリスティック修正を実行できます。
低ランク分解は、ニューラルネットワークの重み行列が低次元行列の積で近似できるという事実に基づいています。N x N行列は、2つのN x 1行列の積で近似できます。これは、O(N^2) -> O(N)の空間複雑性の改善です。
知識蒸留は、1つのモデルから別のモデルへの知識の転移です。通常は、大きなモデルから小さなモデルへの転移です。生徒モデルが類似の出力レスポンスを生成することを学ぶ場合、それはレスポンスベースの蒸留です。生徒モデルが類似の中間層を再現することを学ぶ場合、それは特徴ベースの蒸留です。生徒モデルが層間の相互作用を再現することを学ぶ場合、それは関係ベースの蒸留です。
軽量モデル設計は、経験的結果から得られた知識を使用して、効率的なアーキテクチャを設計することです。これは、LLM研究で最も使用されている方法の1つです。
日本語版は Ai 支援を使用しているため、小さな間違いが存在する可能性があることをご了承ください。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私たちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA