- 公開日
マシンラーニングの場合、データが間違う可能性は無限大です。
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
それらを完全に避けるためのマジックのようなトリックはありませんが、ある程度軽減する方法はあります。
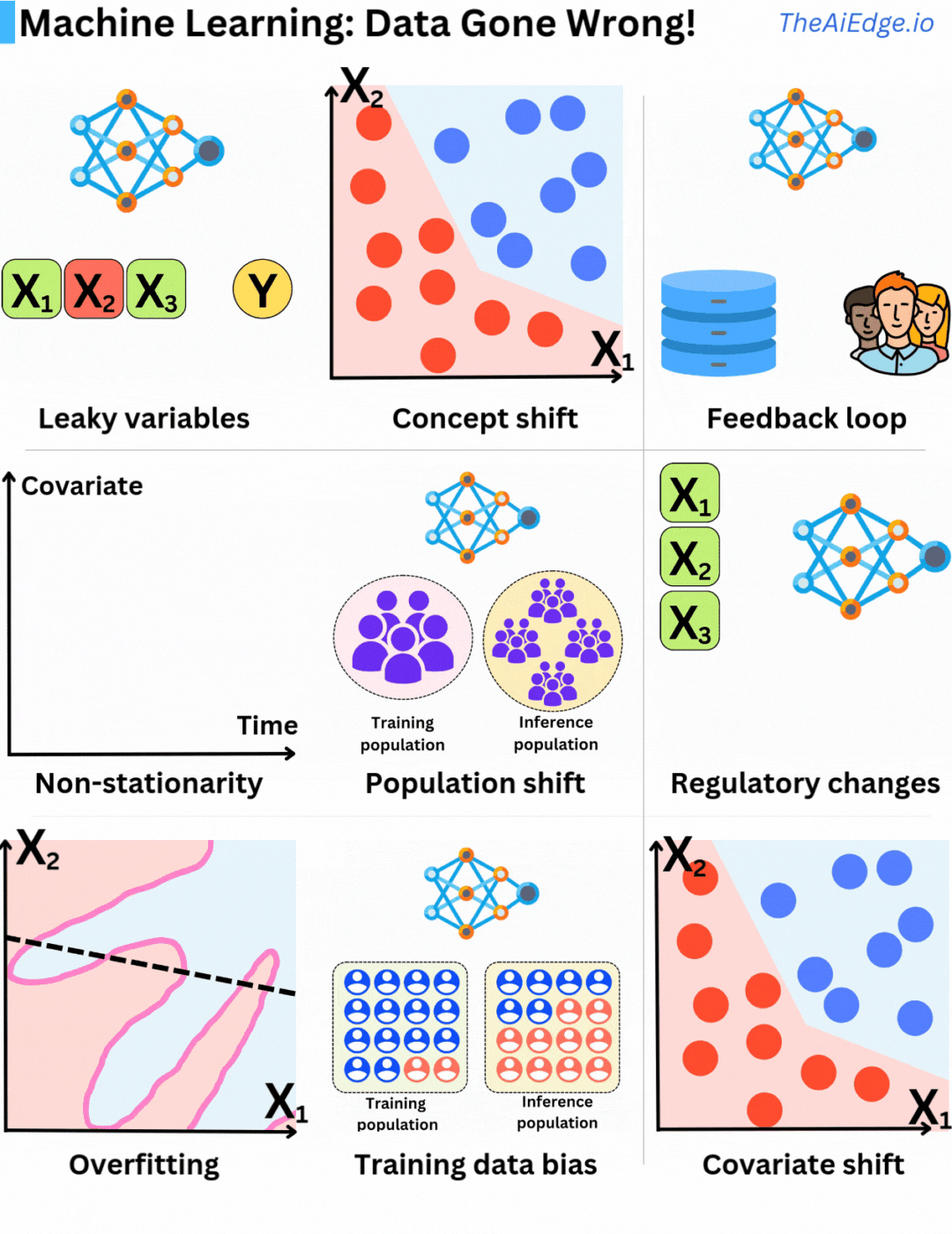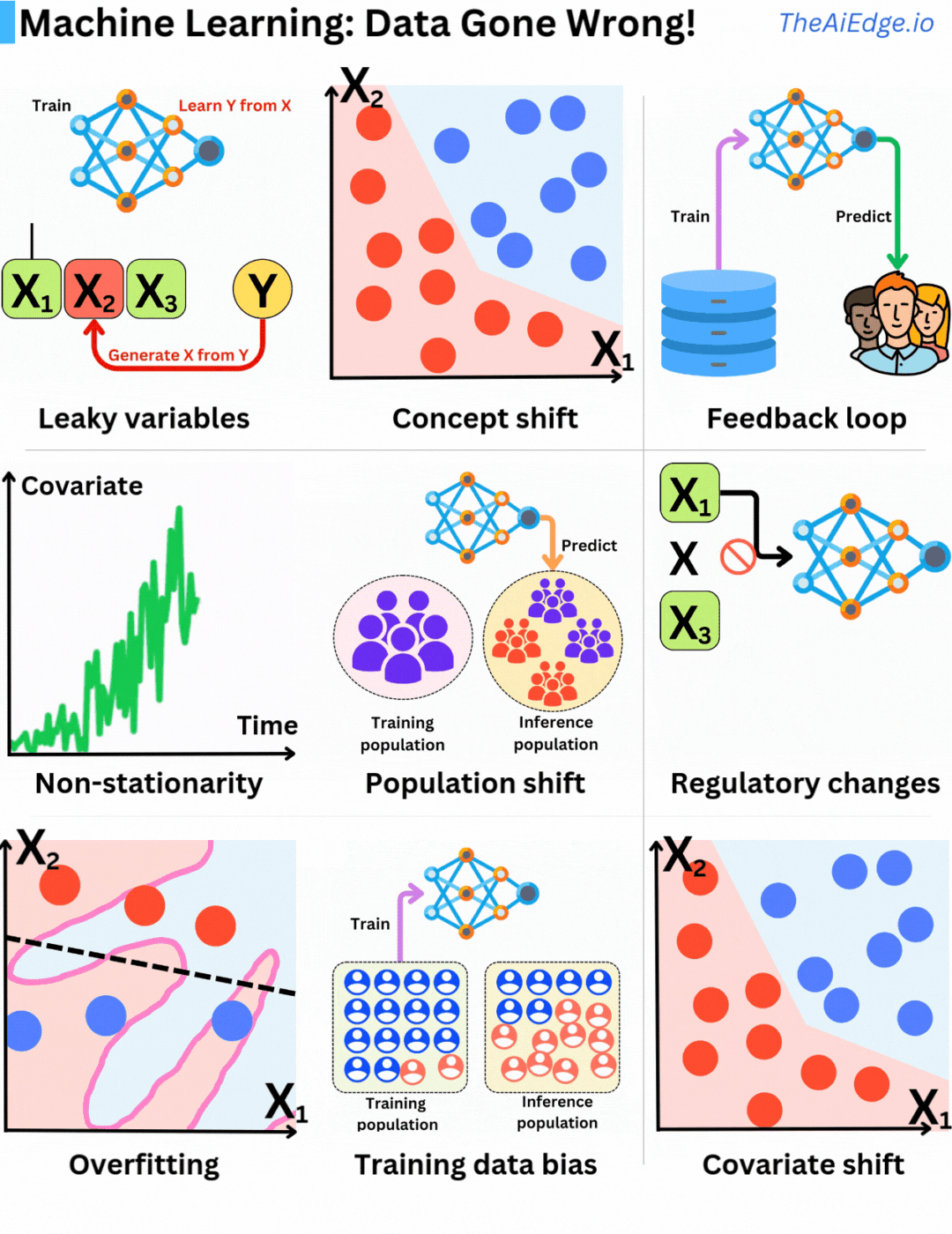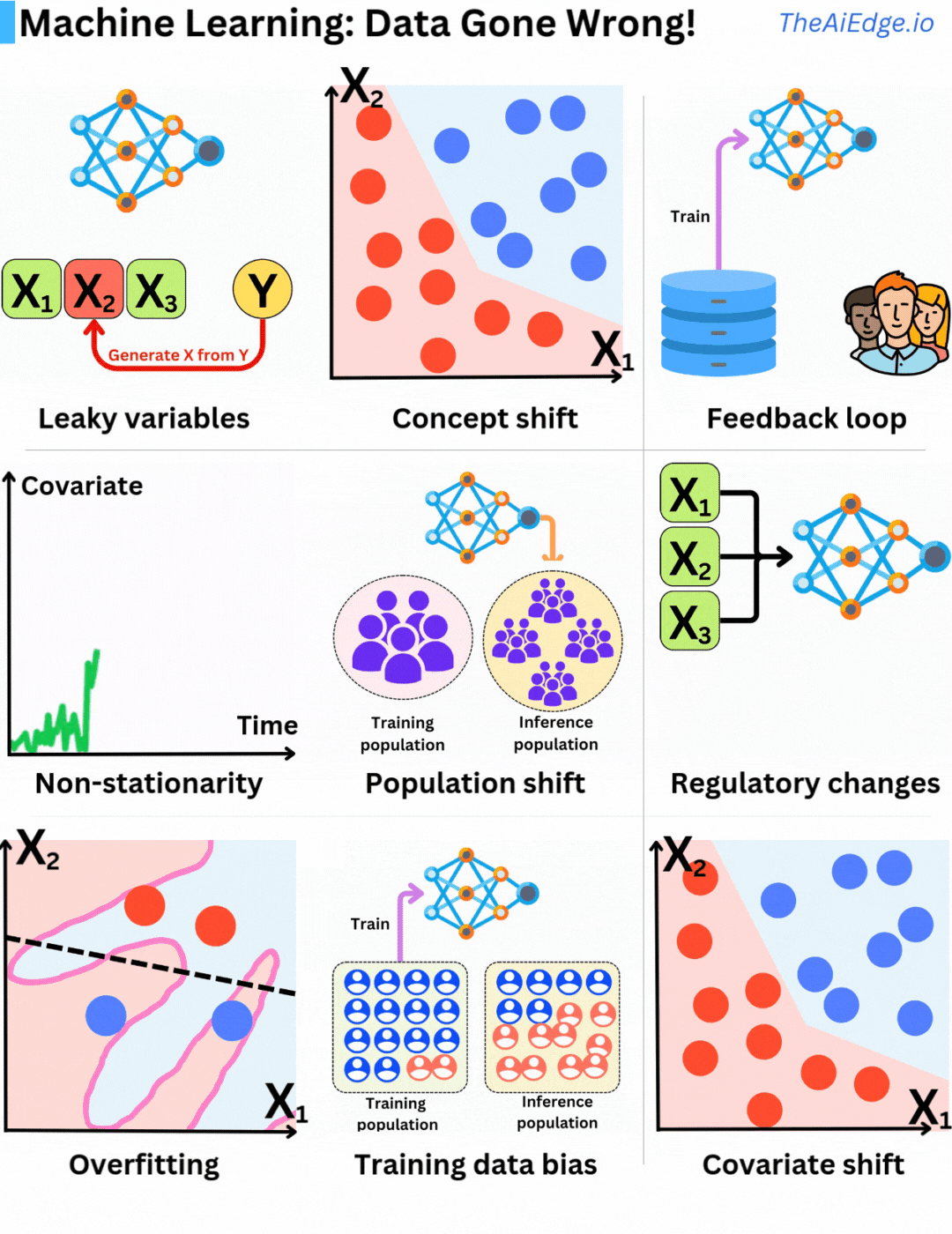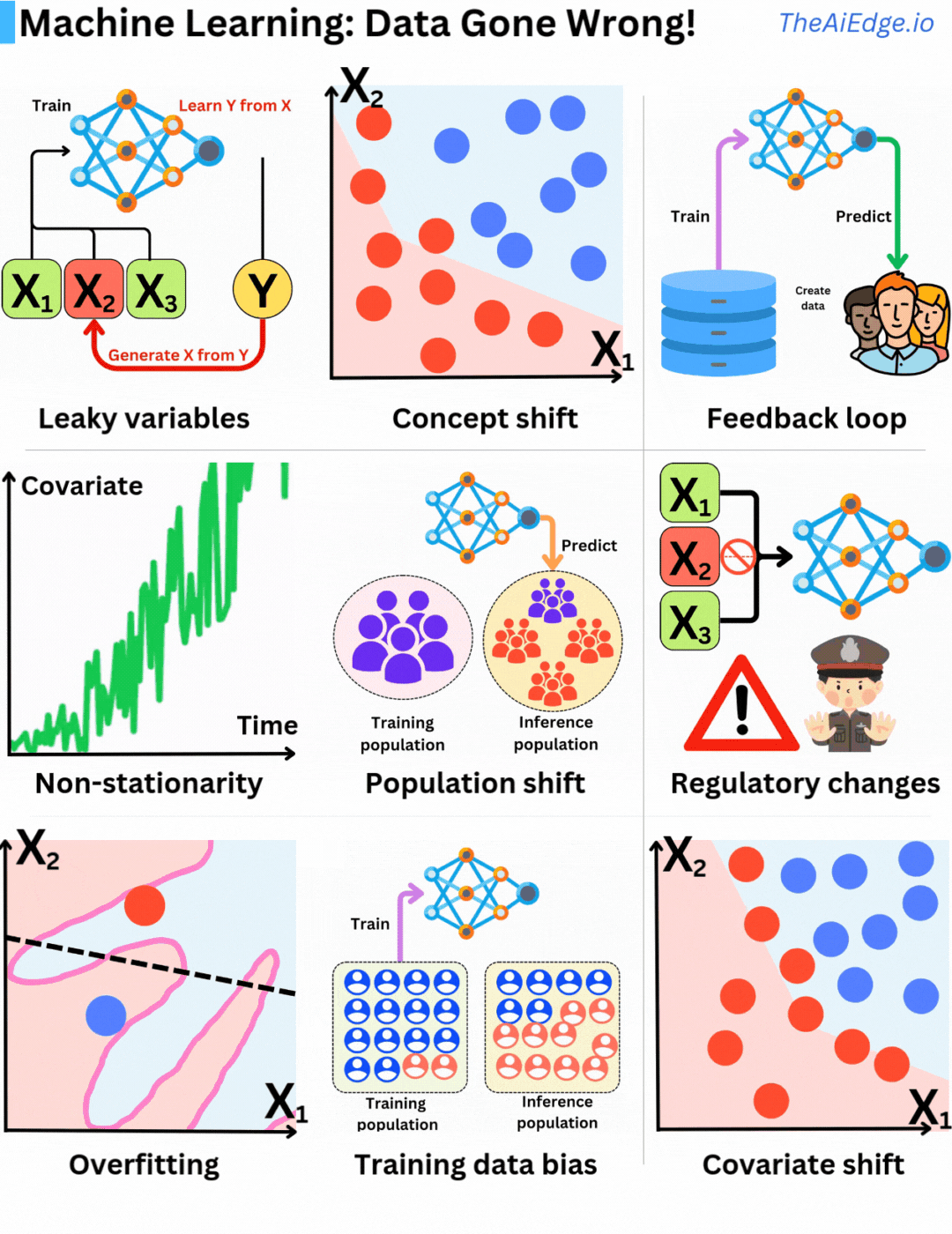
機械学習におけるデータの問題は、確かに無限に存在します。しかも、それらの問題を完全に回避するための魔法のような方法はありませんが、ある程度緩和する方法はあります。
リーキー変数とは、予測時には知ることができなかった情報をトレーニングデータに使用することです。ある意味では、予測しようとしているものを特徴セットの一部として含めており、見かけ上はモデルが過剰にパフォーマンスを発揮することにつながります。
コンセプトドリフトとは、基本的な入力変数の分布が同じままであるのに、ターゲット変数との関係が変化することです。したがって、定期的な再トレーニングや継続的なトレーニング戦略を実施することが重要です。
フィードバックループとは、現在のモデルの予測を使用して将来のトレーニングデータを蓄積することです。その結果、将来のモデルは、生産データをうまく表していないデータに基づいてトレーニングされることになり、選択バイアスが生じます。特に、レコメンダーエンジンではよく見られます。実際には、より良いモデルにつながる可能性もありますが、前のモデルで犯したミスを強化する可能性もあります。
定常性は、統計学習における基本的な仮定であり、サンプルは同一に分布するものと仮定します。ただし、サンプルの確率分布が時間の経過とともに変化する場合(非定常)、同一分布仮定は破綻します。したがって、定常性のある特徴を構築することが重要です。たとえば、ドル金額は良い特徴ではありません(インフレのため)が、相対的なドル変化(Δ)の方が良いかもしれません。
人口シフトは、コンセプトシフトや非定常性につながる典型的な問題です。モデルで推測するための基本的な人口が時間の経過とともに変化し、元のトレーニングデータはもはや現在の人口を代表するものではなくなります。再び、定期的な再トレーニングはこの問題に対する良い解決策です。
規制変更は難しい問題です!ある日、新しいデータ保護法が制定されたり、Appleストアがプライバシーポリシーを変更したりして、特定の特徴を取得することが不可能になることがあります。特定のデータに依存していた企業は、Google PlayやAppleストアが一時的に許可していたデータを取得することができなくなったために倒産することになりました。
オーバーフィッティングは、もちろん最もよく知られている問題ですが、幸いなことに、すべてのMLエンジニアがよく準備されている問題です。これは、モデルがテストデータにうまく一般化できず、トレーニングデータ内の統計ノイズを多く捉えることです。
トレーニングデータバイアスとは、トレーニング中のサンプル分布が生産データ分布をうまく表していないことです。結果として、バイアスしたモデルが生成されます。バイアスがどのように推測に影響するかを理解することが重要です。
共変量シフトとは、入力特徴分布 P(X) が変化するが、ターゲット P(Y|X) との関係は変化しないことです。これにより、トレーニングデータの選択プロセスでバイアスが生じ、不正確なモデルが生成される可能性があります。
日本語版は Ai 支援を使用しているため、小さな間違いが存在する可能性があることをご了承ください。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私たちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA