- 公開日
OpenAi O1: 非常に優れたベンチマーク
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
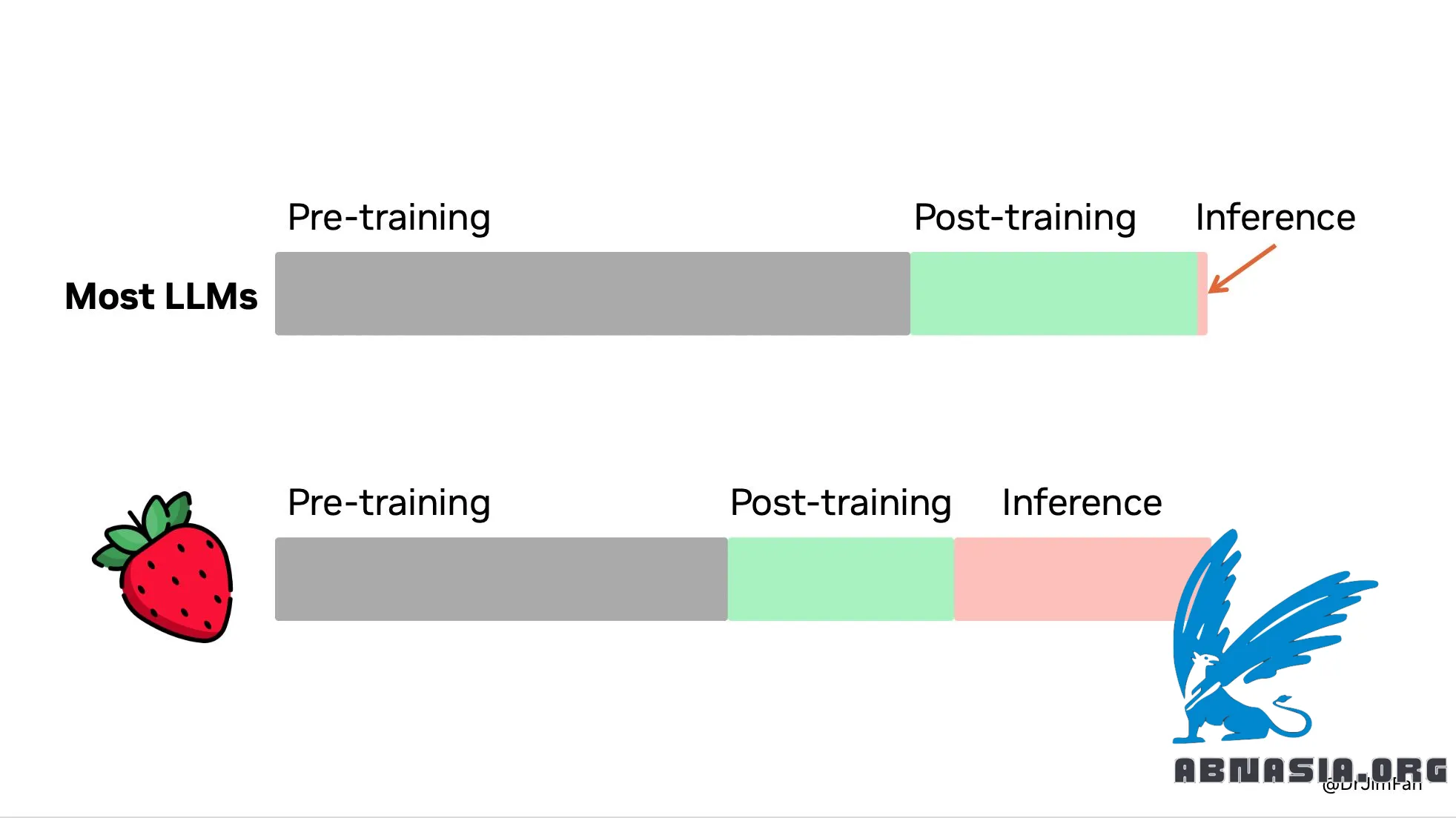
"OpenAI Strawberry (o1) がリリースされました!ついに、推論時間スケーリングのパラダイムが普及し、運用環境に導入されるのが見えてきました。サットン氏が苦い教訓で述べたように、コンピューティングで無限に拡張できる手法は学習と検索の 2 つだけです。後者に焦点を移す時期が来ています。
推論を実行するために巨大なモデルは必要ありません。トリビア QA などのベンチマークで優れたパフォーマンスを発揮するために、多くのパラメーターが事実の記憶に特化しています。知識、つまりブラウザやコード検証ツールなどのツールを呼び出す方法を知っている小さな「推論コア」から推論を取り出すことは可能です。トレーニング前の計算量が減少する可能性があります。
膨大な量のコンピューティングが、トレーニング前/トレーニング後ではなく推論の提供に移されます。 LLM はテキストベースのシミュレーターです。シミュレータで多くの可能な戦略とシナリオを展開することで、モデルは最終的に適切なソリューションに収束します。このプロセスは、AlphaGo のモンテカルロ木探索 (MCTS) と同様、よく研究された問題です。
OpenAI はずっと前に推論スケーリング則を発見していたはずですが、これは学術界が最近発見したばかりです。先月、Arxiv に 1 週間おきに 2 つの論文が掲載されました。
ラージ ランゲージ モンキー: 繰り返しサンプリングによる推論計算のスケーリング。ブラウンら。 DeepSeek-Coder は、SWE-Bench で 1 サンプルの 15.9% から 250 サンプルの 56% まで増加し、Sonnet-3.5 を上回っていることがわかりました。
LLM テスト時間計算を最適にスケーリングすることは、モデル パラメーターをスケーリングするよりも効果的です。スネルら。テスト時の探索では、PaLM 2-S が MATH で 14 倍大きいモデルを上回ることがわかりました。
o1 を製品化することは、学術的なベンチマークを達成することよりもはるかに困難です。現実の推論の問題について、いつ検索を停止するかをどのように決定すればよいでしょうか?報酬関数とは何ですか?成功基準?ループ内でコード インタプリタなどのツールをいつ呼び出すか?これらの CPU プロセスの計算コストを考慮に入れるにはどうすればよいでしょうか?彼らの研究投稿はあまり共有されませんでした。
イチゴは簡単にデータ フライホイールになります。答えが正しければ、検索トレース全体が、正の報酬と負の報酬の両方を含むトレーニング例のミニ データセットになります。
これにより、MCTS がより洗練されたトレーニング データを生成するにつれて、AlphaGo のバリュー ネットワーク (各盤上のポジションの品質を評価するために使用) が向上するのと同様に、GPT の将来のバージョンの推論コアが向上します。"
日本語版は Ai 支援を使用しているため、小さな間違いが存在する可能性があることをご了承ください。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私たちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA