- 公開日
トランスフォーマーで何が重要か?
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
What Matters In Transformers? は、LLM の Llama のようなもので、実際に注意層の半分を削除しても、モデル性能が著しく低下しないことを発見した興味深い論文です。
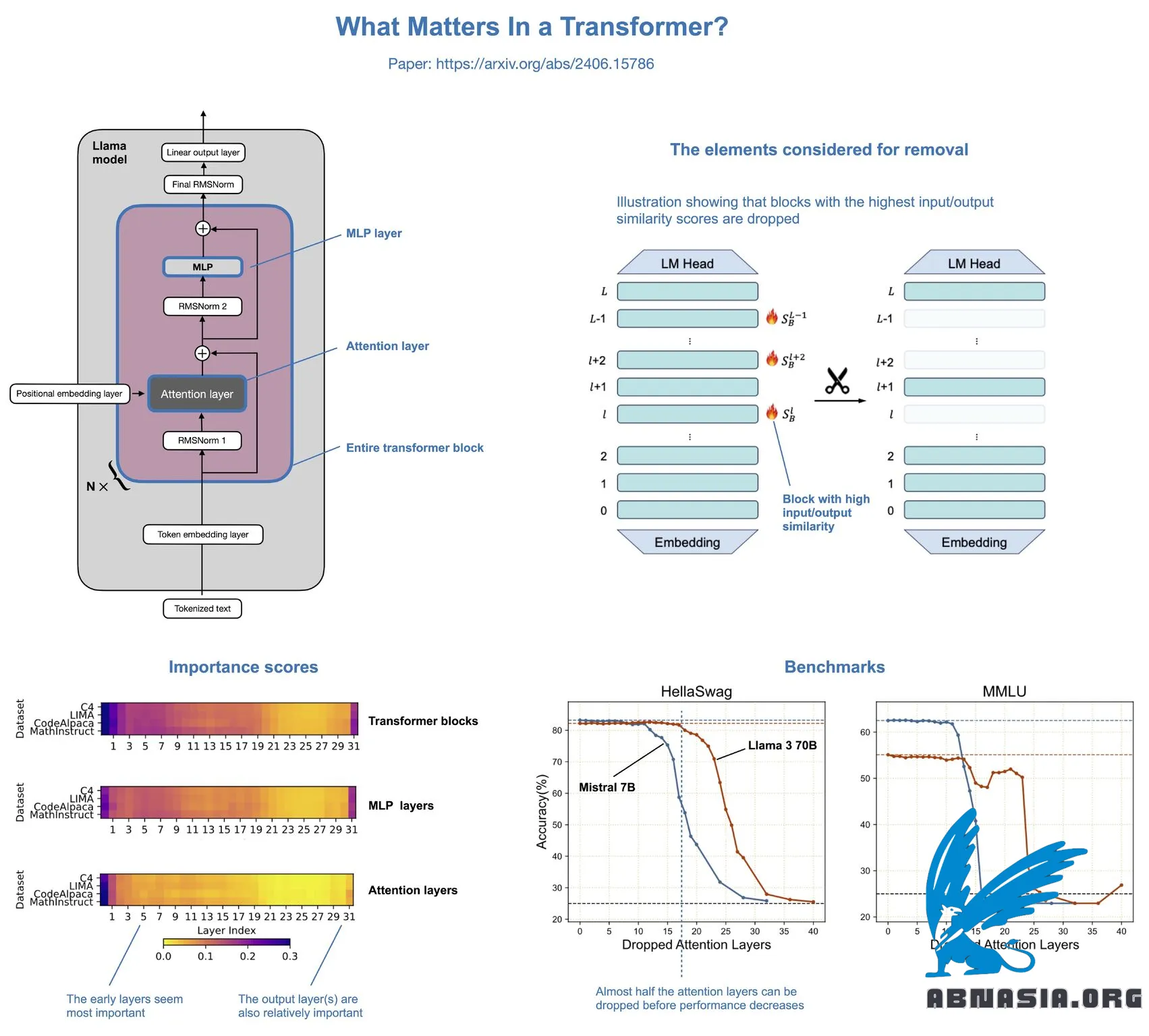
この概念は比較的単純です。著者は、注意層、MLP層、またはトランスフォーマーのブロック全体を削除します。
トランスフォーマーのブロック全体を削除すると、パフォーマンスが大幅に低下します。
MLP層を削除すると、パフォーマンスが大幅に低下します。
注意層を削除しても、ほとんどパフォーマンスが低下しません!
Llama 2 70Bでは、注意層の半分を削除して(これにより48%の速度向上が得られる)しても、モデルのベンチマークでは2.4%の低下しかありません。著者は最近、Llama 3の結果も論文に追加し、それらは似ています。
注意層はランダムに削除されませんでしたが、コサインベースの類似性スコアに基づいて削除されました。入力と出力が非常に似ている場合、層は冗長であり、削除できます。
これは非常に興味深い結果であり、さまざまなモデル圧縮技術(プルーニングや量子化など)と組み合わせて複合効果を得る可能性があります。
さらに、層は反復的な方法ではなく、1回で削除され、削除後には再トレーニングは必要ありません。ただし、削除後にモデルを再トレーニングすると、失われたパフォーマンスの一部を回復することができる可能性があります。
全体として、非常に単純ですが非常に興味深い研究です。より大きなアーキテクチャには、計算上の冗長性がたくさんある可能性があります。
ただし、この研究には大きな注意点があります。主に学術的なベンチマーク(HellaSwag、MMLUなど)に焦点が当てられています。会話のパフォーマンスを測定するベンチマークでのモデルのパフォーマンスは不明です。
日本語版は Ai 支援を使用しているため、小さな間違いが存在する可能性があることをご了承ください。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私たちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA