- เผยแพร่เมื่อ
ไม่มีข้อจำกัดในการที่ข้อมูลอาจผิดพลาดได้ เมื่อพูดถึงการเรียนรู้ของเครื่อง
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
ไม่มีกลอุบายที่จะหลีกเลี่ยงสิ่งเหล่านั้นได้ แต่มีวิธีลดผลกระทบของมันในระดับหนึ่ง
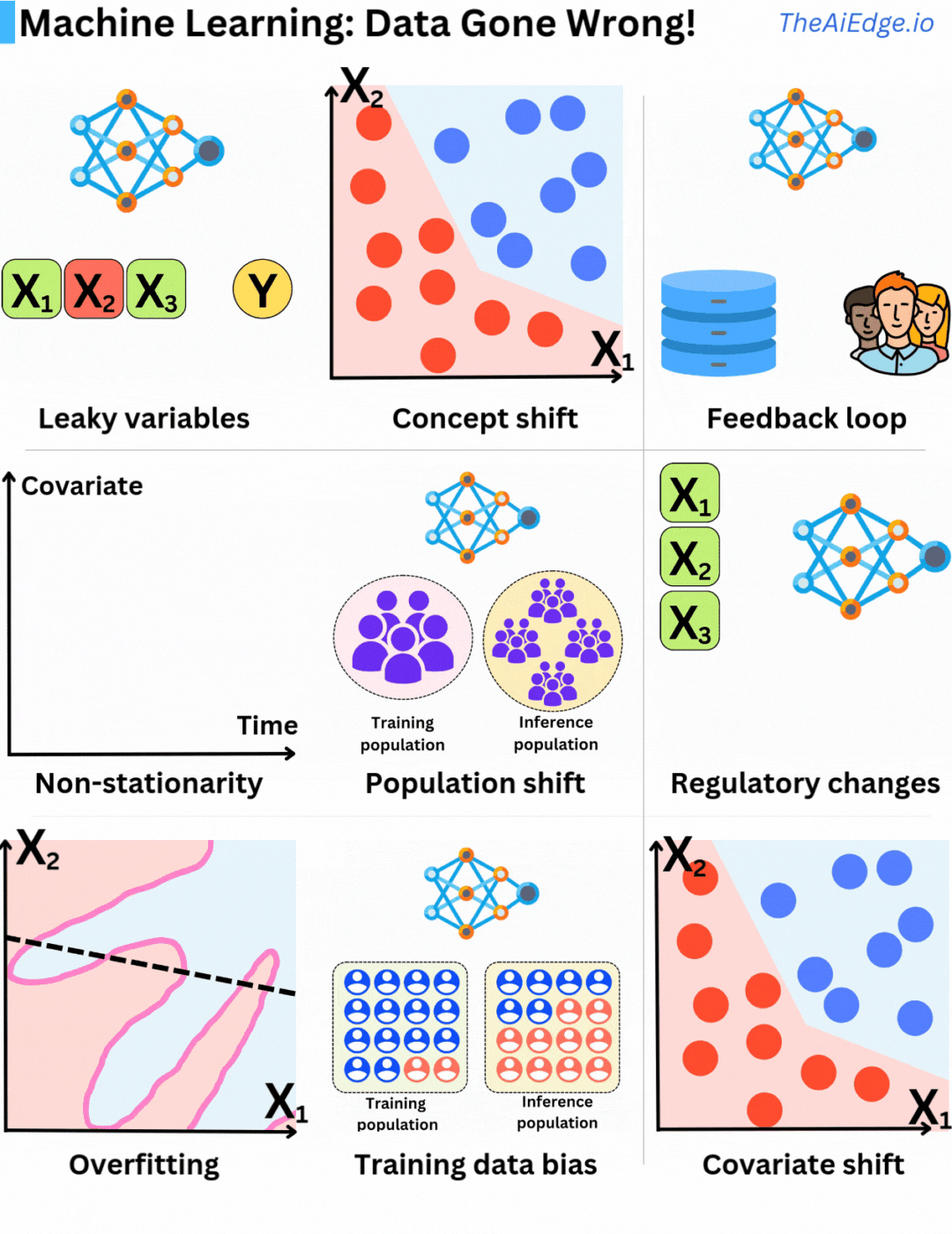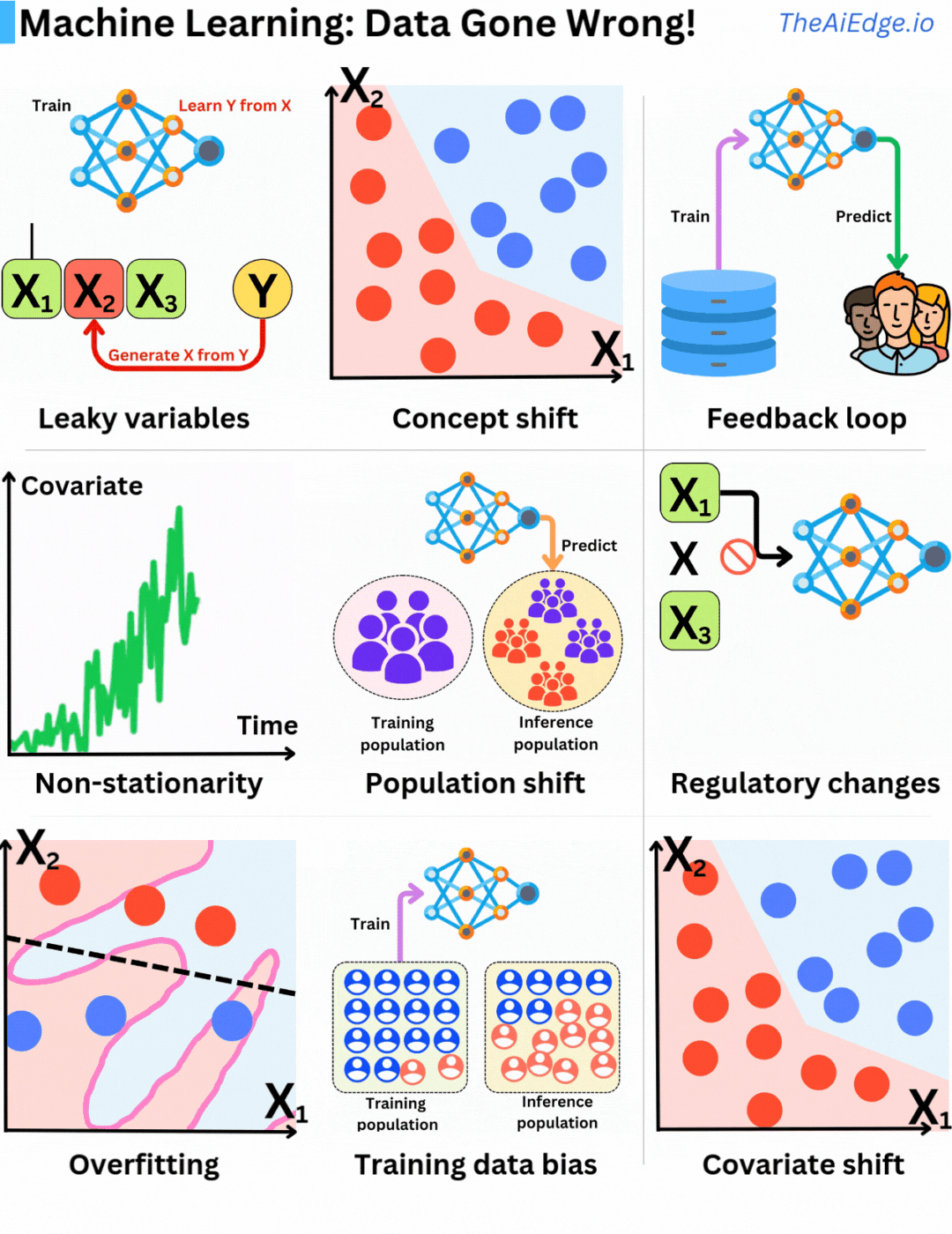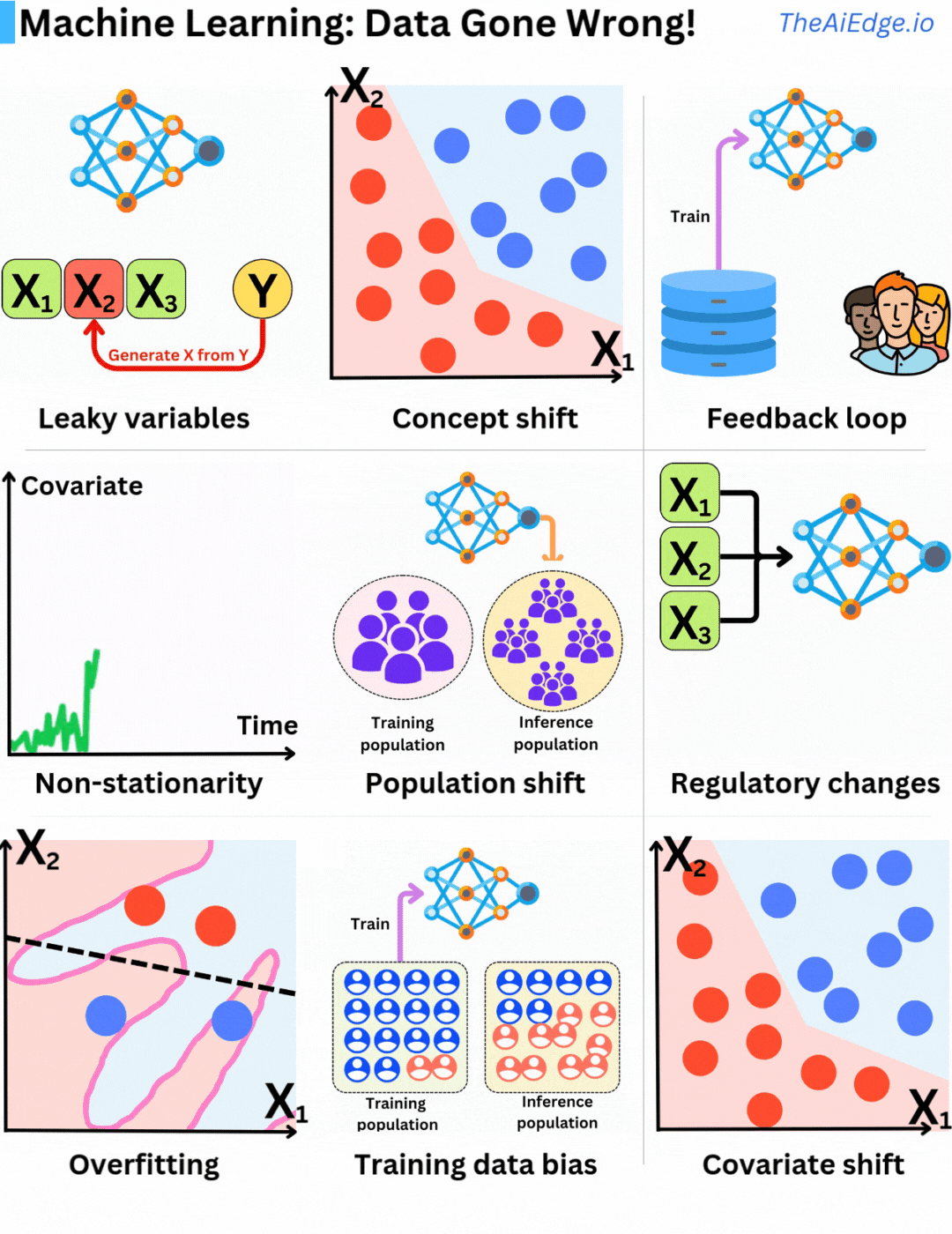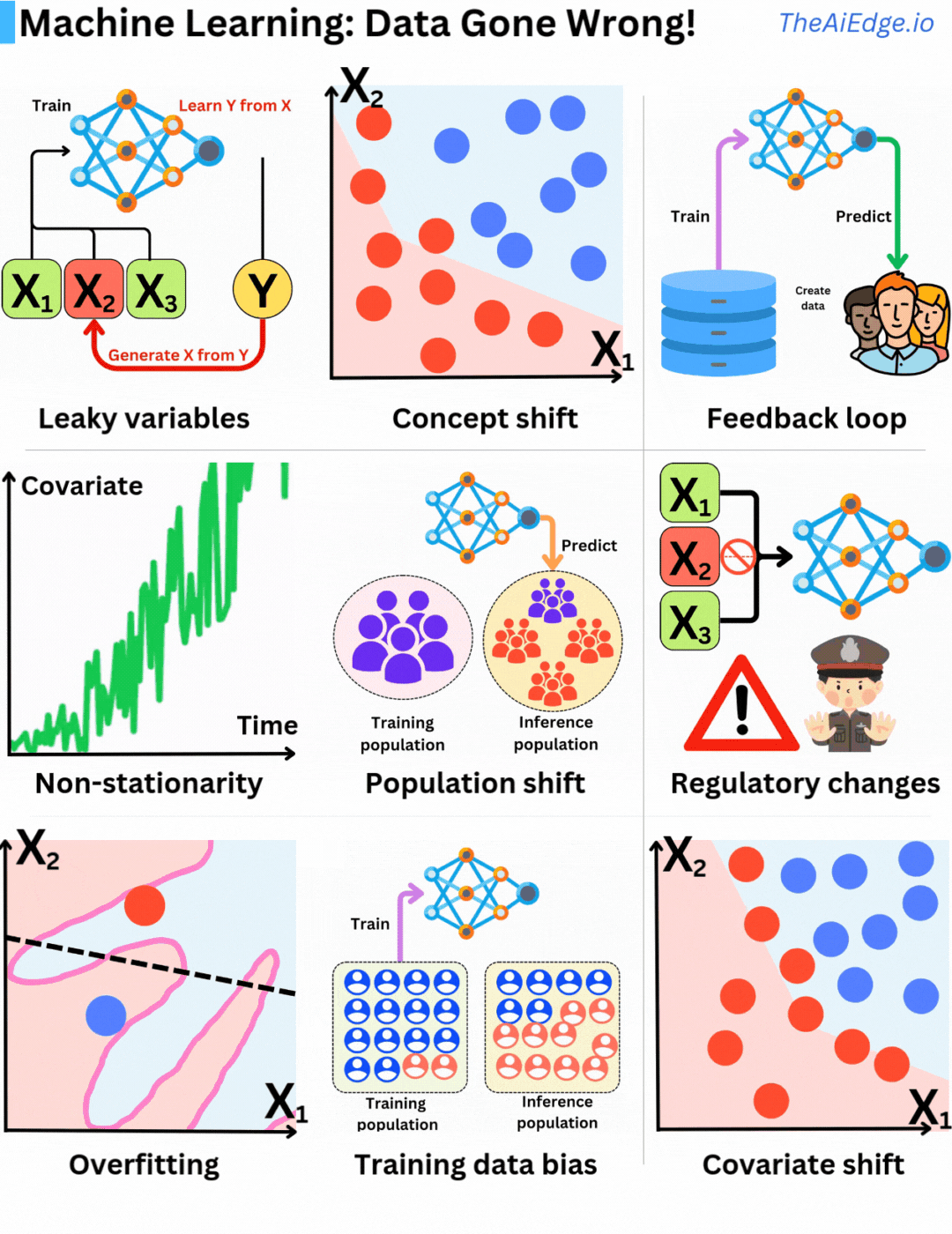
ไม่มีข้อจำกัดวิธีที่ข้อมูลอาจผิดพลาดเมื่อใช้ Machine Learning มากนัก ไม่มีวิธีแก้ปัญหาที่ดีเยี่ยมในการหลีกเลี่ยง แต่ก็มีวิธีลดผลกระทบได้บ้าง
ตัวแปรรั่วไหล (Leaky variables) คือการใช้ข้อมูลที่คุณไม่สามารถรู้ได้ในขณะทำนายในการฝึกอบรมข้อมูล ซึ่งหมายความว่าคุณกำลังรวมสิ่งที่คุณพยายามทำนายเป็นส่วนหนึ่งของชุดคุณสมบัติ ซึ่งนำไปสู่โมเดลที่ดูเหมือนจะทำงานได้ดีเกินไป
การเปลี่ยนแปลงแนวคิด (Concept drift) คือเมื่อการกระจายตัวของตัวแปรอินพุตที่ซ่อนอยู่ยังคงเหมือนเดิม แต่ความสัมพันธ์ของตัวแปรเหล่านั้นกับตัวแปรเป้าหมายเปลี่ยนแปลงไป นั่นเป็นเหตุผลที่ต้องมีการฝึกอบรมแบบงวดหรือแบบต่อเนื่อง
วงจรการให้ข้อเสนอแนะ (Feedback loops) คือเมื่อใช้การทำนายของโมเดลปัจจุบันเพื่อสะสมข้อมูลฝึกอบรมในอนาคต ทำให้เกิดความลำเอียงในการเลือกข้อมูลสำหรับโมเดลที่ฝึกอบรมในอนาคต ซึ่งไม่ได้แสดงถึงข้อมูลการผลิตที่ดี สิ่งนี้เกิดขึ้นบ่อยในระบบแนะนำ!
ความคงตัว (Stationarity) เป็นสมมติฐานพื้นฐานในการเรียนรู้ทางสถิติ เนื่องจากเราถือว่าข้อมูลตัวอย่างมีการกระจายตัวเหมือนกัน หากการกระจายตัวของความน่าจะเป็นเปลี่ยนแปลงไปตามเวลา (ไม่คงตัว) สมมติฐานการกระจายตัวเหมือนกันจะถูกละเมิด นั่นเป็นเหตุผลที่สำคัญในการสร้างคุณสมบัติที่มีความคงตัวมากที่สุด ตัวอย่างเช่น จำนวนเงินไม่ใช่คุณสมบัติที่ดี (เนื่องจากอัตราเงินเฟ้อ) แต่การเปลี่ยนแปลงจำนวนเงินสัมพัทธ์ (Δ) อาจดีกว่า
การเปลี่ยนแปลงประชากร (Population shift) เป็นปัญหาทั่วไปที่นำไปสู่การเปลี่ยนแปลงแนวคิดและการไม่คงตัว ประชากรที่ใช้ในการสร้างโมเดลเปลี่ยนแปลงไปตามเวลา และข้อมูลฝึกอบรมเดิมไม่ได้เป็นตัวแทนของประชากรปัจจุบันอีกต่อไป การฝึกอบรมแบบงวดเป็นวิธีการแก้ปัญหาที่ดีสำหรับปัญหานี้
การเปลี่ยนแปลงกฎระเบียบ (Regulatory changes) เป็นปัญหาที่ยาก! วันหนึ่ง กฎหมายข้อมูลใหม่ถูกผ่านหรือ Apple Store เปลี่ยนนโยบายความเป็นส่วนตัว ทำให้การเก็บข้อมูลคุณสมบัติบางอย่างเป็นไปไม่ได้ บริษัทหลายแห่งล้มละลายเพราะพึ่งพาข้อมูลเฉพาะที่ Google Play หรือ Apple Store อนุญาตให้เก็บได้เมื่อก่อน แต่ห้ามในภายหลัง
การปรับให้เหมาะสมมากเกินไป (Overfitting) เป็นปัญหาที่รู้จักกันดีที่สุด และ幸ด้วยว่ามันเป็นปัญหาที่วิศวกร ML ทุกคนเตรียมพร้อมดี! นี่คือเมื่อโมเดลไม่สามารถสรุปผลได้ดีกับข้อมูลทดสอบเพราะมันจับเสียงรบกวนทางสถิติในข้อมูลฝึกอบรมมากเกินไป
ความลำเอียงของข้อมูลฝึกอบรม (Training data bias) คือเมื่อการกระจายตัวอย่างระหว่างการฝึกอบรมไม่ได้เป็นตัวแทนของการกระจายตัวอย่างข้อมูลการผลิต ทำให้เกิดโมเดลที่ลำเอียง มีความสำคัญที่จะต้องเข้าใจว่าความลำเอียงจะส่งผลต่อการอนุมานอย่างไร
การเปลี่ยนแปลงคอเวเรต (Covariate shift) คือเมื่อการกระจายตัวของคุณสมบัติอินพุต P(X) เปลี่ยนแปลง แต่ความสัมพันธ์ของตัวแปรเหล่านั้นกับตัวแปรเป้าหมาย P(Y|X) ยังคงเหมือนเดิม สิ่งนี้อาจนำไปสู่ความลำเอียงในการเลือกข้อมูลฝึกอบรม ซึ่งอาจส่งผลให้โมเดลไม่แม่นยำ
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA